文章来源于公众号:Code center ,作者五柳
前言
「静态节点提升」是「Vue3」针对 VNode 更新过程性能问题而提出的一个优化点。众所周知,在大型应用场景下,「Vue2.x」 的 patchVNode 过程,即 diff 过程是非常缓慢的,这是一个十分令人头疼的问题。
虽然,对于面试常问的 diff 过程在一定程度上是减少了对 DOM 的直接操作。但是,「这个减少是有一定成本的」。因为,如果是复杂应用,那么就会存在父子关系非常复杂的 VNode,而这也就是 diff 的痛点,它会不断地递归调用 patchVNode,不断堆叠而成的几毫秒,最终就会造成 VNode 更新缓慢。
也因此,这也是为什么我们所看到的大型应用诸如阿里云之类的采用的是基于「React」的技术栈的原因之一。所以,「Vue3」也是痛改前非,重写了整个 Compiler 过程,提出了静态提升、靶向更新等优化点,来提高 patchVNode 过程。
那么,回到今天的正题,我们从源码角度看看在整个编译过程「Vue3」静态节点提升究竟是「何许人也」?
什么是 patchFlag
由于,在 compile 过程的 transfrom 阶段会提及 AST Element 上的 patchFlag 属性。所以,在正式认识 complie 之前,我们先搞清楚一个概念,什么是 patchFlag?
patchFlag 是 complier 时的 transform 阶段解析 AST Element 打上的「优化标识」。并且,顾名思义 patchFlag,patch 一词表示着它会为 runtime时的 patchVNode 提供依据,从而实现靶向更新 VNode 的效果。因此,这样一来一往,也就是耳熟能详的 Vue3 巧妙结合 runtime 与 compiler 实现靶向更新和静态提升。
而在源码中 patchFlag 被定义为一个「数字枚举类型」,每一个枚举值对应的标识意义会是这样:
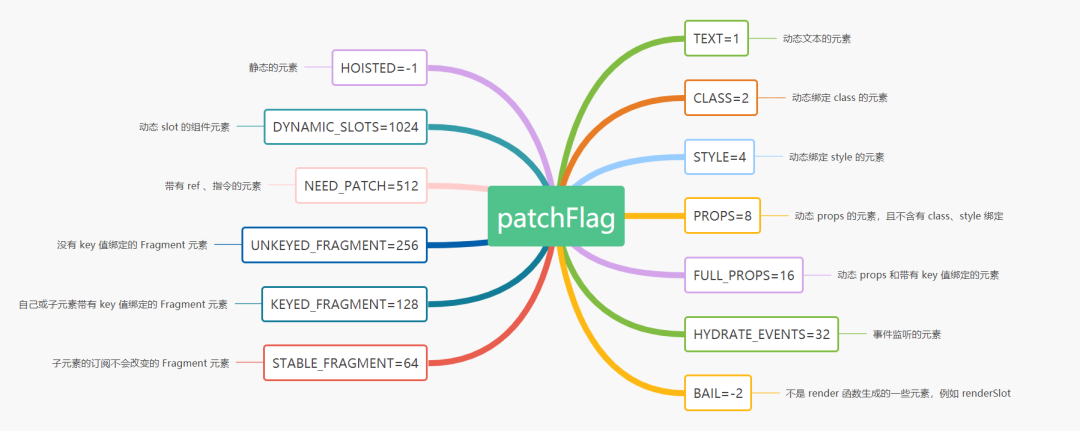
并且,值得一提的是整体上 patchFlag 的分为两大类:
- 当
patchFlag的值「大于」 0 时,代表所对应的元素在patchVNode时或render时是可以被优化生成或更新的。 - 当
patchFlag的值「小于」 0 时,代表所对应的元素在patchVNode时,是需要被full diff,即进行递归遍历VNode tree的比较更新过程。
其实,还有两类特殊的
flag:shapeFlag和slogFlag,这里我就不对此展开,有兴趣的同学可以自行去了解。
Compile 编译过程
对比 Vue2.x 编译过程
了解过「Vue2.x」源码的同学,我想应该都知道在「Vue2.x」中的 Compile 过程会是这样:
parse编译模板生成原始 AST。optimize优化原始 AST,标记 AST Element 为静态根节点或静态节点。generate根据优化后的 AST,生成可执行代码,例如_c、_l之类的。

而在「Vue3」中,整体的 Compile 过程仍然是三个阶段,但是不同于「Vue2.x」的是,第二个阶段换成了正常编译器都会存在的阶段 transform。所以,它看起来会是这样:

在源码中,它对应的伪代码会是这样:
export function baseCompile(
template: string | RootNode,
options: CompilerOptions = {}
): CodegenResult {
...
const ast = isString(template) ? baseParse(template, options) : template
...
transform(
ast,
extend({}, options, {....})
)
return generate(
ast,
extend({}, options, {
prefixIdentifiers
})
)
} 那么,我想这个时候大家可能会问为什么会是 transform?它的职责是什么?
通过简单的对比「Vue2.x」编译过程的第二阶段的 optimize,很明显,transform并不是「无米之炊」,它仍然有着「优化」原始 AST 的作用,而具体职责会表现在:
- 对所有 AST Element 新增
codegen属性来帮助generate更准确地生成「最优」的可执行代码。 - 对静态 AST Element 新增
hoists属性来实现静态节点的「单独创建」。 - …
此外,transform 还标识了诸如 isBlock、helpers 等属性,来生成最优的可执行代码,这里我们就不细谈,有兴趣的同学可以自行了解。
baseParse 构建原始抽象语法树(AST)
baseParse 顾名思义起着「解析」的作用,它的表现和「Vue2.x」的 parse 相同,都是解析模板 tempalte 生成「原始 AST」。
假设,此时我们有一个这样的模板 template:
<div><div>hi vue3</div><div>{{msg}}</div></div> 那么,它在经过 baseParse 处理后生成的 AST 看起来会是这样:
{
cached: 0,
children: [{…}],
codegenNode: undefined,
components: [],
directives: [],
helpers: [],
hoists: [],
imports: [],
loc: {start: {…}, end: {…}, source: "<div><div>hi vue3</div><div>{{msg}}</div></div>"},
temps: 0,
type: 0
} 如果,了解过「Vue2.x」编译过程的同学应该对于上面这颗 AST 的大部分属性不会陌生。AST 的本质是通过用对象来描述「DSL」(特殊领域语言),例如:
children中存放的就是最外层div的后代。loc则用来描述这个 AST Element 在整个字符串(template)中的位置信息。type则是用于描述这个元素的类型(例如 5 为插值、2 为文本)等等。
并且,可以看到的是不同于「Vue2.x」的 AST,这里我们多了诸如 helpers、codegenNode、hoists 等属性。而,这些属性会在 transform 阶段进行相应地赋值,进而帮助 generate 阶段生成「更优的」可执行代码。
transfrom 优化原始抽象语法树(AST)
对于 transform 阶段,如果了解过「编译器」的工作流程的同学应该知道,一个完整的编译器的工作流程会是这样:
- 首先,
parse解析原始代码字符串,生成抽象语法树 AST。 - 其次,
transform转化抽象语法树,让它变成更贴近目标「DSL」的结构。 - 最后,
codegen根据转化后的抽象语法树生成目标「DSL」的可执行代码。
而在「Vue3」采用 Monorepo 的方式管理项目后,compile 对应的能力就是一个编译器。所以,transform 也是整个编译过程的重中之重。换句话说,如果没有 transform 对 AST 做诸多层面的转化,「Vue」仍然会挂在 diff 这个「饱受诟病」的过程。
相比之下,「Vue2.x」的编译阶段没有完整的
transform,只是optimize优化了一下 AST,可以想象在「Vue」设计之初尤大也没想到它以后会「这么地流行」!
那么,我们来看看 transform 函数源码中的定义:
function transform(root: RootNode, options: TransformOptions) {
const context = createTransformContext(root, options)
traverseNode(root, context)
if (options.hoistStatic) {
hoistStatic(root, context)
}
if (!options.ssr) {
createRootCodegen(root, context)
}
// finalize meta information
root.helpers = [...context.helpers]
root.components = [...context.components]
root.directives = [...context.directives]
root.imports = [...context.imports]
root.hoists = context.hoists
root.temps = context.temps
root.cached = context.cached
} 可以说,transform 函数做了什么,在它的定义中是「一览无余」。这里我们提一下它对静态提升其决定性作用的两件事:
- 将原始 AST 中的静态节点对应的 AST Element 赋值给根 AST 的
hoists属性。 - 获取原始 AST 需要的 helpers 对应的键名,用于
generate阶段的生成可执行代码的获取对应函数,例如createTextVNode、createStaticVNode、renderList等等。
并且,在 traverseNode 函数中会对 AST Element 应用具体的 transform 函数,大致可以分为两类:
- 静态节点
transform应用,即节点不含有插值、指令、props、动态样式的绑定等。 - 动态节点
transform应用,即节点含有插值、指令、props、动态样式的绑定等。
那么,我们就来看看对于静态节点 transform 是如何应用的?
静态节点 transform 应用
这里,对于上面我们说到的这个栗子,静态节点就是这个部分:
<div>hi vue3</div> 而它在没有进行 transform 应用之前,它对应的 AST 会是这样:
{
children: [{
content: "hi vue3"
loc: {start: {…}, end: {…}, source: "hi vue3"}
type: 2
}],
codegenNode: undefined,
isSelfClosing: false,
loc: {start: {…}, end: {…}, source: "<div>hi vue3</div>"},
ns: 0,
props: [],
tag: "div",
tagType: 0,
type: 1
} 可以看出,此时它的 codegenNode 是 undefined。而在源码中各类 transform函数被定义为 plugin,它会根据 baseParse 生成的 AST 「递归应用」对应的 plugin。然后,创建对应 AST Element 的 codegen 对象。
所以,此时我们会命中 transformElement 和 transformText 两个 plugin的逻辑。
「transformText」
transformText 顾名思义,它和「文本」相关。很显然,此时的 AST Element 所属的类型就是 Text。那么,我们先来看一下 transformText 函数对应的伪代码:
export const transformText: NodeTransform = (node, context) => {
if (
node.type === NodeTypes.ROOT ||
node.type === NodeTypes.ELEMENT ||
node.type === NodeTypes.FOR ||
node.type === NodeTypes.IF_BRANCH
) {
return () => {
const children = node.children
let currentContainer: CompoundExpressionNode | undefined = undefined
let hasText = false
for (let i = 0; i < children.length; i++) { // {1}
const child = children[i]
if (isText(child)) {
hasText = true
...
}
}
if (
!hasText ||
(children.length === 1 &&
(node.type === NodeTypes.ROOT ||
(node.type === NodeTypes.ELEMENT &&
node.tagType === ElementTypes.ELEMENT)))
) { // {2}
return
}
...
}
}
} 可以看到,这里我们会命中 「{2}」 的逻辑,即如果对于「节点含有单一文本」 transformText 并不需要进行额外的处理,即该节点仍然在这里仍然保留和「Vue2.x」版本一样的处理方式。
而 transfromText 真正发挥作用的场景是当模板中存在这样的情况:
<div>ab {a} {b}</div> 此时 transformText 需要将两者放在一个「单独的」 AST Element 下,在源码中它被称为「Compound Expression」,即「组合的表达式」。这种组合的目的是为了 patchVNode 这类 VNode 时做到「更好地定位和实现 DOM 的更新」。反之,如果是一个文本节点和插值动态节点的话,在 patchVNode 阶段同样的操作需要进行两次,例如对于同一个 DOM 节点操作两次。
「transformElement」
transformElement 是一个所有 AST Element 都会被执行的一个 plugin,它的核心是为 AST Element 生成最基础的 codegen 属性。例如标识出对应 patchFlag,从而为生成 VNode 提供依据,例如 dynamicChildren。
而对于静态节点,同样是起到一个初始化它的 codegenNode 属性的作用。并且,从上面介绍的 patchFlag 的类型,我们可以知道它的 patchFlag 为默认值 0。所以,它的 codegenNode 属性值看起来会是这样:
{
children: {
content: "hi vue3"
loc: {start: {…}, end: {…}, source: "hi vue3"}
type: 2
},
directives: undefined,
disableTracking: false,
dynamicProps: undefined,
isBlock: false,
loc: {start: {…}, end: {…}, source: "<div>hi vue3</div>"},
patchFlag: undefined,
props: undefined,
tag: ""div"",
type: 13
}generate 生成可执行代码
generate 是 compile 阶段的最后一步,它的作用是将 transform 转换后的 AST 生成对应的「可执行代码」,从而在之后 Runtime 的 Render 阶段时,就可以通过可执行代码生成对应的 VNode Tree,然后最终映射为真实的 DOM Tree 在页面上。
同样地,这一阶段在「Vue2.x」也是由 generate 函数完成,它会生成是诸如 _l、_c 之类的函数,这本质上是对 _createElement 函数的封装。而相比较「Vue2.x」版本的 generate,「Vue3」改变了很多,其 generate 函数对应的伪代码会是这样:
export function generate(
ast: RootNode,
options: CodegenOptions & {
onContextCreated?: (context: CodegenContext) => void
} = {}
): CodegenResult {
const context = createCodegenContext(ast, options)
if (options.onContextCreated) options.onContextCreated(context)
const {
mode,
push,
prefixIdentifiers,
indent,
deindent,
newline,
scopeId,
ssr
} = context
...
genFunctionPreamble(ast, context)
...
if (!ssr) {
...
push(`function render(_ctx, _cache${optimizeSources}) {`)
}
....
return {
ast,
code: context.code,
// SourceMapGenerator does have toJSON() method but it's not in the types
map: context.map ? (context.map as any).toJSON() : undefined
}
}所以,接下来,我们就来「一睹」带有静态节点对应的 AST 生成的可执行代码的过程会是怎样。
CodegenContext 代码生成上下文
从上面 generate 函数的伪代码可以看到,在函数的开始调用了 createCodegenContext 为当前 AST 生成了一个 context。在整个 generate 函数的执行过程「都依托」于一个 CodegenContext 「生成代码上下文」(对象)的能力,它是通过 createCodegenContext 函数生成。而 CodegenContext 的接口定义会是这样:
interface CodegenContext
extends Omit {
source: string
code: string
line: number
column: number
offset: number
indentLevel: number
pure: boolean
map?: SourceMapGenerator
helper(key: symbol): string
push(code: string, node?: CodegenNode): void
indent(): void
deindent(withoutNewLine?: boolean): void
newline(): void
} 可以看到 CodegenContext 对象中有诸如 push、indent、newline 之类的方法。而它们的作用是在根据 AST 来生成代码时用来「实现换行」、「添加代码」、「缩进」等功能。从而,最终形成一个个可执行代码,即我们所认知的 render 函数,并且,它会作为 CodegenContext 的 code 属性的值返回。
下面,我们就来看下静态节点的可执行代码生成的核心,它被称为 Preamble 前导。
genFunctionPreamble 生成前准备
整个静态提升的可执行代码生成就是在 genFunctionPreamble 函数部分完成的。并且,大家仔细「斟酌」一番静态提升的字眼,静态二字我们可以不看,但是「提升二字」,直抒本意地表达出它(静态节点)被「提高了」。
为什么说是提高了?因为在源码中的体现,确实是被提高了。在前面的 generate 函数,我们可以看到 genFunctionPreamble 是先于 render 函数加入context.code 中,所以,在 Runtime 时的 Render 阶段,它会先于 render 函数执行。
geneFunctionPreamble 函数(伪代码):
function genFunctionPreamble(ast: RootNode, context: CodegenContext) {
const {
ssr,
prefixIdentifiers,
push,
newline,
runtimeModuleName,
runtimeGlobalName
} = context
...
const aliasHelper = (s: symbol) => `${helperNameMap[s]}: _${helperNameMap[s]}`
if (ast.helpers.length > 0) {
...
if (ast.hoists.length) {
const staticHelpers = [
CREATE_VNODE,
CREATE_COMMENT,
CREATE_TEXT,
CREATE_STATIC
]
.filter(helper => ast.helpers.includes(helper))
.map(aliasHelper)
.join(', ')
push(`const { ${staticHelpers} } = _Vue\n`)
}
}
...
genHoists(ast.hoists, context)
newline()
push(`return `)
} 可以看到,这里会对前面我们在 transform 函数提及的 hoists 属性的长度进行判断。显然,对于前面说的这个栗子,它的 ast.hoists.length 长度是大于 0 的。所以,这里就会根据 hoists 中的 AST 生成对应的可执行代码。因此,到这里,生成的可执行代码会是这样:
const _Vue = Vue
const { createVNode: _createVNode } = _Vue
// 静态提升部分
const _hoisted_1 = _createVNode("div", null, "hi vue3", -1 /* HOISTED */)
// render 函数会在这下面小结
静态节点提升在整个 compile 编译阶段体现,从最初的 baseCompile 到 transform 转化原始 AST、再到 generate 的优先 render 函数处理生成可执行代码,最后交给 Runtime 时的 Render 执行,这种设计可以说是非常精妙!所以,这样一来,就完成了我们经常看到在一些文章提及的「Vue3」对于静态节点在整个生命周期中它只会执行「一次创建」的源码实现,这在一定程度上降低了性能上的开销。
以上就是W3Cschool编程狮关于Vue 3.0 diff 新特性 – 静态节点提升的相关介绍了,希望对大家有所帮助。