先来看看HTTP是什么吧。
VulnHub-DC-6靶机-wpscan爆破+命令注入反弹shell+nmap提权
鸿蒙的 Javascript 框架逐行源码解读
文章来源于公众号:justjavac ,作者justjavac
我曾经介绍过鸿蒙的 Javascript 框架,这几天终于把 JS 仓库编译通过了,期间踩了不少坑,也给鸿蒙贡献了几个 PR。
今天我们就来逐行分析鸿蒙系统中的 JS 框架。
文中的所有代码都基于鸿蒙的当前最新版(版本为 677ed06,提交日期为 2020-09-10)。
鸿蒙系统使用 Javascript 开发 GUI 是一种类似于微信小程序、轻应用的模式。而这个 MVVM 模式中,V 其实是由 C++ 来承担的。Javascript 代码只是其中的 ViewModel 层。
鸿蒙 JS 框架是零依赖的,只在开发打包过程中使用到了一些 npm 包。打包完之的代码是没有依赖任何 npm 包的。我们先看一下使用鸿蒙 JS 框架写出来的 JS 代码到底长什么样。
export default {
data: {
return { count: 1 };
},
increase() {
++this.count;
},
decrease() {
--this.count;
},
}如果我不告诉你这是鸿蒙,你甚至会以为它是 vue 或小程序。如果单独把 JS 拿出来使用(脱离鸿蒙系统),代码是这样:
const vm = new ViewModel({
data() {
return { count: 1 };
},
increase() {
++this.count;
},
decrease() {
--this.count;
},
});
console.log(vm.count); // 1
vm.increase();
console.log(vm.count); // 2
vm.decrease();
console.log(vm.count); // 1仓库中的所有 JS 代码实现了一个响应式系统,充当了 MVVM 中的 ViewModel。
下面我们逐行分析。
src 目录中一共有 4 个目录,总计 8 个文件。其中 1 个是单元测试。还有 1 个性能分析。再除去 2 个 index.js 文件,有用的文件一共是 4 个。也是本文分析的重点。
src
├── __test__
│ └── index.test.js
├── core
│ └── index.js
├── index.js
├── observer
│ ├── index.js
│ ├── observer.js
│ ├── subject.js
│ └── utils.js
└── profiler
└── index.js 首先是入口文件,src/index.js,只有 2 行代码:
import { ViewModel } from './core';
export default ViewModel; 其实就是重新导出。 另一个类似的文件是 src/observer/index.js,也是 2 行代码:
export { Observer } from './observer';
export { Subject } from './subject';observer 和 subject 实现了一个观察者模式。subject 是主题,也就是被观察者。observer 是观察者。当 subject 有任何变化时需要主动通知被观察者。这就是响应式。
这 2 个文件都使用到了 src/observer/utils.js,所以我们先分析一下 utils 文件。分 3 部分。
第一部分
export const ObserverStack = {
stack: [],
push(observer) {
this.stack.push(observer);
},
pop() {
return this.stack.pop();
},
top() {
return this.stack[this.stack.length - 1];
}
}; 首先是定义了一个用来存放观察者的栈,遵循后进先出的原则,内部使用 stack 数组来存储。
- 入栈操作
push,和数组的push函数一样,在栈顶放入一个观察者observer。 - 出栈操作
pop,和数组的pop函数一样,在将栈顶的观察者删除,并返回这个被删除的观察者。 - 取栈顶元素
top,和pop操作不同,top是把栈顶元素取出来,但是并不删除。
第二部分
export const SYMBOL_OBSERVABLE = '__ob__';
export const canObserve = target => typeof target === 'object'; 定义了一个字符串常量 SYMBOL_OBSERVABLE。为了后面用着方便。
定义了一个函数 canObserve,目标是否可以被观察。只有对象才能被观察,所以使用 typeof 来判断目标的类型。等等,好像有什么不对。如果 target 为 null 的话,函数也会返回 true。如果 null 不可观察,那么这就是一个 bug。(写这篇文章的时候我已经提了一个 PR,并询问了这种行为是否是期望的行为)。
第三部分
export const defineProp = (target, key, value) => {
Object.defineProperty(target, key, { enumerable: false, value });
}; 这个没有什么好解释的,就是 Object.defineProperty 代码太长了,定义一个函数来避免代码重复。 下面再来分析观察者 src/observer/observer.js,分 4 部分。
第一部分
export function Observer(context, getter, callback, meta) {
this._ctx = context;
this._getter = getter;
this._fn = callback;
this._meta = meta;
this._lastValue = this._get();
}构造函数。接受 4 个参数。
context 当前观察者所处的上下午,类型是 ViewModel。当第三个参数 callback 调用时,函数的 this 就是这个 context。
getter 类型是一个函数,用来获取某个属性的值。
callback 类型是一个函数,当某个值变化后执行的回调函数。
meta 元数据。观察者(Observer)并不关注 meta 元数据。
在构造函数的最后一行,this._lastValue = this._get()。下面来分析 _get 函数。
第二部分
Observer.prototype._get = function() {
try {
ObserverStack.push(this);
return this._getter.call(this._ctx);
} finally {
ObserverStack.pop();
}
}; ObserverStack 就是上面分析过的用来存储所有观察者的栈。将当前观察者入栈,并通过 _getter 取得当前值。结合第一部分的构造函数,这个值存储在了 _lastValue 属性中。 执行完这个过程后,这个观察者就已经初始化完成了。
第三部分
Observer.prototype.update = function() {
const lastValue = this._lastValue;
const nextValue = this._get();
const context = this._ctx;
const meta = this._meta;
if (nextValue !== lastValue || canObserve(nextValue)) {
this._fn.call(context, nextValue, lastValue, meta);
this._lastValue = nextValue;
}
};这部分实现了数据更新时的脏检查(Dirty checking)机制。比较更新后的值和当前值,如果不同,那么就执行回调函数。如果这个回调函数是渲染 UI,那么则可以实现按需渲染。如果值相同,那么再检查设置的新值是否可以被观察,再决定到底要不要执行回调函数。
第四部分
Observer.prototype.subscribe = function(subject, key) {
const detach = subject.attach(key, this);
if (typeof detach !== 'function') {
return;
}
if (!this._detaches) {
this._detaches = [];
}
this._detaches.push(detach);
};
Observer.prototype.unsubscribe = function() {
const detaches = this._detaches;
if (!detaches) {
return;
}
while (detaches.length) {
detaches.pop()();
}
};订阅与取消订阅。
我们前面经常说观察者和被观察者。对于观察者模式其实还有另一种说法,叫订阅/发布模式。而这部分代码则实现了对主题(subject)的订阅。
先调用主题的 attach 方法进行订阅。如果订阅成功,subject.attach 方法会返回一个函数,当调用这个函数就会取消订阅。为了将来能够取消订阅,这个返回值必需保存起来。
subject 的实现很多人应该已经猜到了。观察者订阅了 subject,那么 subject 需要做的就是,当数据变化时即使通知观察者。subject 如何知道数据发生了变化呢,机制和 vue2 一样,使用 Object.defineProperty 做属性劫持。
下面再来分析观察者 src/observer/subject.js,分 7 部分。
第一部分
export function Subject(target) {
const subject = this;
subject._hijacking = true;
defineProp(target, SYMBOL_OBSERVABLE, subject);
if (Array.isArray(target)) {
hijackArray(target);
}
Object.keys(target).forEach(key => hijack(target, key, target[key]));
} 构造函数。基本没什么难点。设置 _hijacking 属性为 true,用来标示这个对象已经被劫持了。Object.keys 通过遍历来劫持每个属性。如果是数组,则调用 hijackArray。
第二部分 两个静态方法。
Subject.of = function(target) {
if (!target || !canObserve(target)) {
return target;
}
if (target[SYMBOL_OBSERVABLE]) {
return target[SYMBOL_OBSERVABLE];
}
return new Subject(target);
};
Subject.is = function(target) {
return target && target._hijacking;
}; Subject 的构造函数并不直接被外部调用,而是封装到了 Subject.of 静态方法中。
如果目标不能被观察,那么直接返回目标。
如果 target[SYMBOL_OBSERVABLE] 不是 undefined,说明目标已经被初始化过了。
否则,调用构造函数初始化 Subject。
Subject.is 则用来判断目标是否被劫持过了。
第三部分
Subject.prototype.attach = function(key, observer) {
if (typeof key === 'undefined' || !observer) {
return;
}
if (!this._obsMap) {
this._obsMap = {};
}
if (!this._obsMap[key]) {
this._obsMap[key] = [];
}
const observers = this._obsMap[key];
if (observers.indexOf(observer) < 0) {
observers.push(observer);
return function() {
observers.splice(observers.indexOf(observer), 1);
};
}
}; 这个方法很眼熟,对,就是上文的 Observer.prototype.subscribe 中调用的。作用是某个观察者用来订阅主题。而这个方法则是“主题是怎么订阅的”。
观察者维护这一个主题的哈希表 _obsMap。哈希表的 key 是需要订阅的 key。比如某个观察者订阅了 name 属性的变化,而另一个观察者订阅了 age 属性的变化。而且属性的变化还可以被多个观察者同时订阅,因此哈希表存储的值是一个数组,数据的每个元素都是一个观察者。
第四部分
Subject.prototype.notify = function(key) {
if (
typeof key === 'undefined' ||
!this._obsMap ||
!this._obsMap[key]
) {
return;
}
this._obsMap[key].forEach(observer => observer.update());
}; 当属性发生变化是,通知订阅了此属性的观察者们。遍历每个观察者,并调用观察者的 update 方法。我们上文中也提到了,脏检查就是在这个方法内完成的。
第五部分
Subject.prototype.setParent = function(parent, key) {
this._parent = parent;
this._key = key;
};
Subject.prototype.notifyParent = function() {
this._parent && this._parent.notify(this._key);
}; 这部分是用来处理属性嵌套(nested object)的问题的。就是类似这种对象:{ user: { name: 'JJC' } }。
第六部分
function hijack(target, key, cache) {
const subject = target[SYMBOL_OBSERVABLE];
Object.defineProperty(target, key, {
enumerable: true,
get() {
const observer = ObserverStack.top();
if (observer) {
observer.subscribe(subject, key);
}
const subSubject = Subject.of(cache);
if (Subject.is(subSubject)) {
subSubject.setParent(subject, key);
}
return cache;
},
set(value) {
cache = value;
subject.notify(key);
}
});
} 这一部分展示了如何使用 Object.defineProperty 进行属性劫持。当设置属性时,会调用 set(value),设置新的值,然后调用 subject 的 notify 方法。这里并不进行任何检查,只要设置了属性就会调用,即使属性的新值和旧值一样。notify 会通知所有的观察者。
第七部分 劫持数组方法。
const ObservedMethods = {
PUSH: 'push',
POP: 'pop',
UNSHIFT: 'unshift',
SHIFT: 'shift',
SPLICE: 'splice',
REVERSE: 'reverse'
};
const OBSERVED_METHODS = Object.keys(ObservedMethods).map(
key => ObservedMethods[key]
); ObservedMethods 定义了需要劫持的数组函数。前面大写的用来做 key,后面小写的是需要劫持的方法。
function hijackArray(target) {
OBSERVED_METHODS.forEach(key => {
const originalMethod = target[key];
defineProp(target, key, function() {
const args = Array.prototype.slice.call(arguments);
originalMethod.apply(this, args);
let inserted;
if (ObservedMethods.PUSH === key || ObservedMethods.UNSHIFT === key) {
inserted = args;
} else if (ObservedMethods.SPLICE) {
inserted = args.slice(2);
}
if (inserted && inserted.length) {
inserted.forEach(Subject.of);
}
const subject = target[SYMBOL_OBSERVABLE];
if (subject) {
subject.notifyParent();
}
});
});
} 数组的劫持和对象不同,不能使用 Object.defineProperty。
我们需要劫持 6 个数组方法。分别是头部添加、头部删除、尾部添加、尾部删除、替换/删除某几项、数组反转。
通过重写数组方法实现了数组的劫持。但是这里有一个需要注意的地方,数据的每一个元素都是被观察过的,但是当在数组中添加了新元素时,这些元素还没有被观察。因此代码中还需要判断当前的方法如果是 push、unshift、splice,那么需要将新的元素放入观察者队列中。
以上就是W3Cschool编程狮关于鸿蒙的 Javascript 框架逐行源码解读的相关介绍了,希望对大家有所帮助。
为什么StringBuilder是线程不安全的?
文章来源于公众号:程序新视界 作者:丑胖侠二师兄
在前面的面试题讲解中我们对比了 String、StringBuilder和StringBuffer的区别 ,其中一项便提到 StringBuilder 是非线程安全的,那么是什么原因导致了 StringBuilder 的线程不安全呢?
原因分析
如果你看了 StringBuilder 或 StringBuffer 的源代码会说,因为StringBuilder在append操作时并未使用线程同步,而StringBuffer几乎大部分方法都使用了synchronized关键字进行方法级别的同步处理。
上面这种说法肯定是正确的,对照一下StringBuilder和StringBuffer的部分源代码也能够看出来。
StringBuilder的append方法源代码:
@Override
public StringBuilder append(String str) {
super.append(str);
return this;
} StringBuffer的append方法源代码:
@Override
public synchronized StringBuffer append(String str) {
toStringCache = null;
super.append(str);
return this;
} 对于上面的结论肯定是没什么问题的,但并没有解释是什么原因导致了StringBuilder的线程不安全?为什么要使用synchronized来保证线程安全?如果不是用会出现什么异常情况?
下面我们来逐一讲解。
异常示例
我们先来跑一段代码示例,看看出现的结果是否与我们的预期一致。
@Test
public void test() throws InterruptedException {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < 10; i++) {
new Thread(() -> {
for (int j = 0; j < 1000; j++) {
sb.append("a");
}
}).start();
}
// 睡眠确保所有线程都执行完
Thread.sleep(1000);
System.out.println(sb.length());
} 上述业务逻辑比较简单,就是构建一个StringBuilder,然后创建10个线程,每个线程中拼接字符串“a”1000次,理论上当线程执行完成之后,打印的结果应该是10000才对。
但多次执行上面的代码打印的结果是10000的概率反而非常小,大多数情况都要少于10000。同时,还有一定的概率出现下面的异常信息“
Exception in thread "Thread-0" java.lang.ArrayIndexOutOfBoundsException
at java.lang.System.arraycopy(Native Method)
at java.lang.String.getChars(String.java:826)
at java.lang.AbstractStringBuilder.append(AbstractStringBuilder.java:449)
at java.lang.StringBuilder.append(StringBuilder.java:136)
at com.secbro2.strings.StringBuilderTest.lambda$test$0(StringBuilderTest.java:18)
at java.lang.Thread.run(Thread.java:748)
9007线程不安全的原因
StringBuilder中针对字符串的处理主要依赖两个成员变量char数组value和count。StringBuilder通过对value的不断扩容和count对应的增加来完成字符串的append操作。
// 存储的字符串(通常情况一部分为字符串内容,一部分为默认值)
char[] value;
// 数组已经使用数量
int count; 上面的这两个属性均位于它的抽象父类AbstractStringBuilder中。
如果查看构造方法我们会发现,在创建StringBuilder时会设置数组value的初始化长度。
public StringBuilder(String str) {
super(str.length() + 16);
append(str);
} 默认是传入字符串长度加16。这就是count存在的意义,因为数组中的一部分内容为默认值。
当调用append方法时会对count进行增加,增加值便是append的字符串的长度,具体实现也在抽象父类中。
public AbstractStringBuilder append(String str) {
if (str == null)
return appendNull();
int len = str.length();
ensureCapacityInternal(count + len);
str.getChars(0, len, value, count);
count += len;
return this;
} 我们所说的线程不安全的发生点便是在append方法中count的“+=”操作。我们知道该操作是线程不安全的,那么便会发生两个线程同时读取到count值为5,执行加1操作之后,都变成6,而不是预期的7。这种情况一旦发生便不会出现预期的结果。
抛异常的原因
回头看异常的堆栈信息,回发现有这么一行内容:
at java.lang.String.getChars(String.java:826) 对应的代码就是上面AbstractStringBuilder中append方法中的代码。对应方法的源代码如下:
public void getChars(int srcBegin, int srcEnd, char dst[], int dstBegin) {
if (srcBegin < 0) {
throw new StringIndexOutOfBoundsException(srcBegin);
}
if (srcEnd > value.length) {
throw new StringIndexOutOfBoundsException(srcEnd);
}
if (srcBegin > srcEnd) {
throw new StringIndexOutOfBoundsException(srcEnd - srcBegin);
}
System.arraycopy(value, srcBegin, dst, dstBegin, srcEnd - srcBegin);
} 其实异常是最后一行arraycopy时JVM底层发生的。arraycopy的核心操作就是将传入的String对象copy到value当中。
而异常发生的原因是明明value的下标只到6,程序却要访问和操作下标为7的位置,当然就跑异常了。
那么,为什么会超出这么一个位置呢?这与我们上面讲到到的count被少加有关。在执行str.getChars方法之前还需要根据count校验一下当前的value是否使用完毕,如果使用完了,那么就进行扩容。append中对应的方法如下:
ensureCapacityInternal(count + len);ensureCapacityInternal的具体实现:
private void ensureCapacityInternal(int minimumCapacity) {
// overflow-conscious code
if (minimumCapacity - value.length > 0) {
value = Arrays.copyOf(value,
newCapacity(minimumCapacity));
}
} count本应该为7,value长度为6,本应该触发扩容。但因为并发导致count为6,假设len为1,则传递的minimumCapacity为7,并不会进行扩容操作。这就导致后面执行str.getChars方法进行复制操作时访问了不存在的位置,因此抛出异常。
这里我们顺便看一下扩容方法中的newCapacity方法:
private int newCapacity(int minCapacity) {
// overflow-conscious code
int newCapacity = (value.length << 1) + 2;
if (newCapacity - minCapacity < 0) {
newCapacity = minCapacity;
}
return (newCapacity <= 0 || MAX_ARRAY_SIZE - newCapacity < 0)
? hugeCapacity(minCapacity)
: newCapacity;
} 除了校验部分,最核心的就是将新数组的长度扩充为原来的两倍再加2。把计算所得的新长度作为Arrays.copyOf的参数进行扩容。
小结
经过上面的分析,是不是真正了解了StringBuilder的线程不安全的原因?我们在学习和实践的过程中,不仅要知道一些结论,还要知道这些结论的底层原理,更重要的是学会分析底层原理的方法。
以上就是W3Cschool编程狮关于为什么StringBuilder是线程不安全的?的相关介绍了,希望对大家有所帮助。
图解| Java查找数组中最大值的5种方法!
文章来源于公众号:Java中文社群 作者:磊哥
我们在一些特定场景下,例如查询公司员工的最高薪资,以及班级的最高成绩又或者是面试中都会遇到查找最大值的问题,所以本文我们就来列举一下查询数组中最大值的 5 种方法。
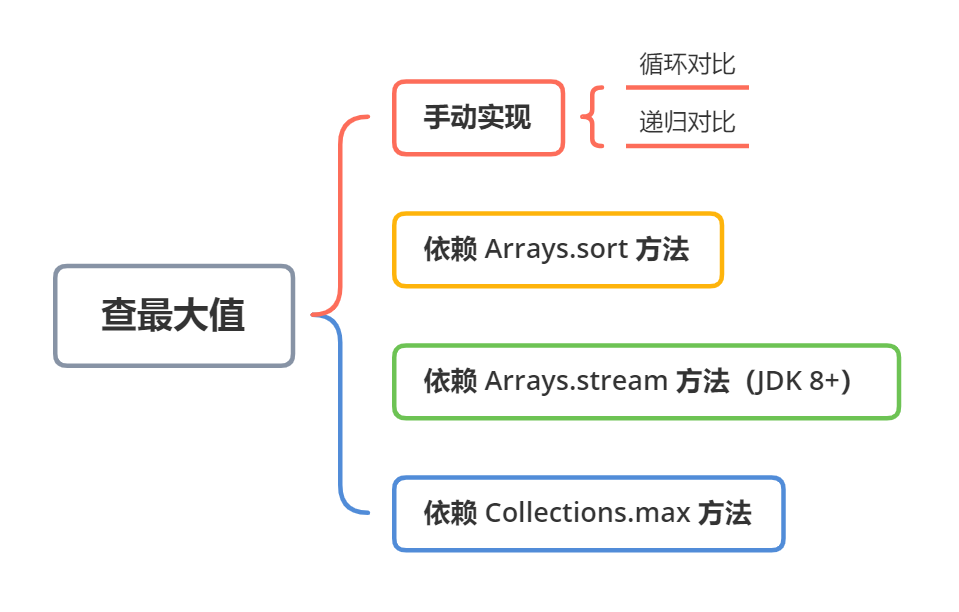
首先我们来看最原始也是最“笨”的实现方法:循环对比和递归对比。
方式一:循环对比
循环对比的执行流程如下图所示:
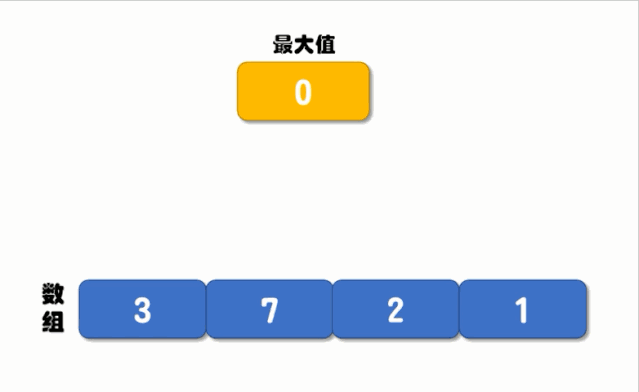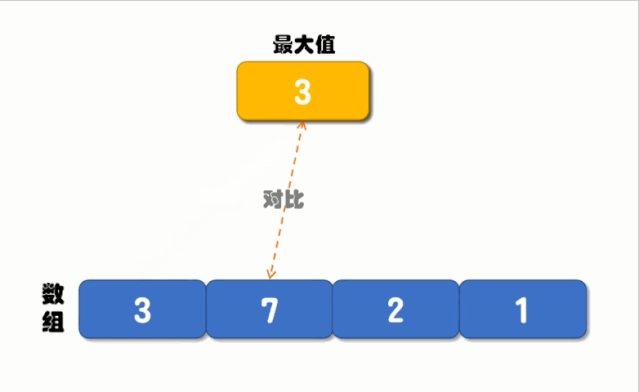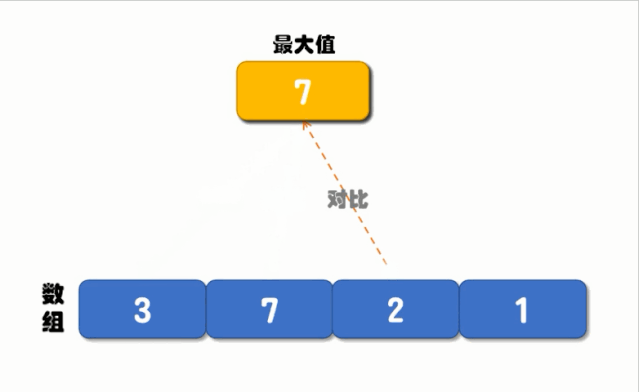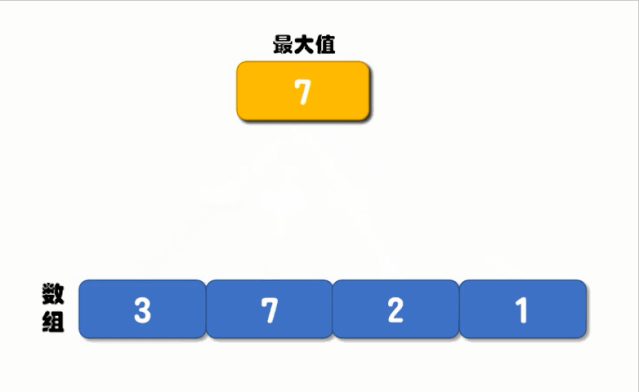
从上图可以看出,循环对比的核心是定义一个最大值,然后循环对比每一个元素,如果元素的值大于最大值就将最大值更新为此元素的值,再进行下一次比较,直到循环结束我们就能找到最大值了,实现代码如下:
public class ArrayMaxTest {
public static void main(String[] args) {
int[] arr = {3, 7, 2, 1, -4};
int max = findMaxByFor(arr); // 查找最大值
System.out.println("最大值是:" + max);
}
/**
* 通过 for 循环查找最大值
* @param arr 待查询数组
* @return 最大值
*/
private static int findMaxByFor(int[] arr) {
int max = 0; // 最大值
for (int item : arr) {
if (item > max) { // 当前值大于最大值,赋值为最大值
max = item;
}
}
return max;
}
}以上程序的执行结果为:
最大值是:7
方式二:递归对比
递归对比的核心是先定义两个位置(起始位置和结束位置),每次对比开始位置和结束位置值的大小,当开始位置的值大于结束位置值时,将最大值设置为开始位置的值,然后将结束位置 -1(往前移动一位),继续递归调用;相反,当结束位置的值大于开始位置时,将最大值设置为结束位置的值,将开始位置 +1(往后移动一位),继续递归调用对比,直到递归结束就可以返回最大值了,执行流程如下图所示:
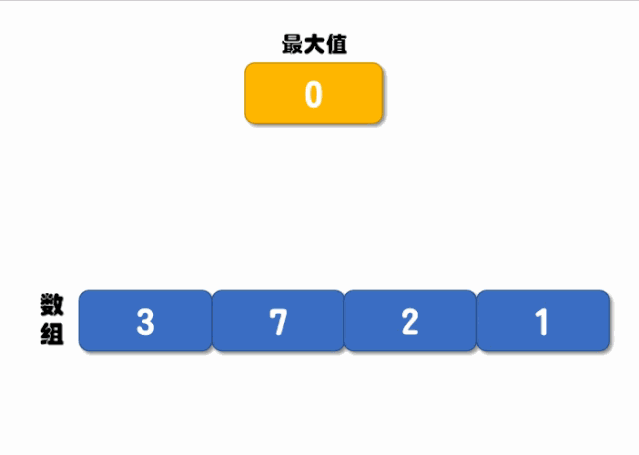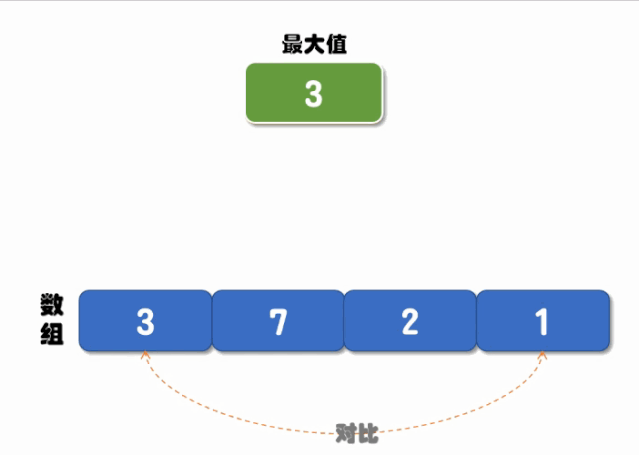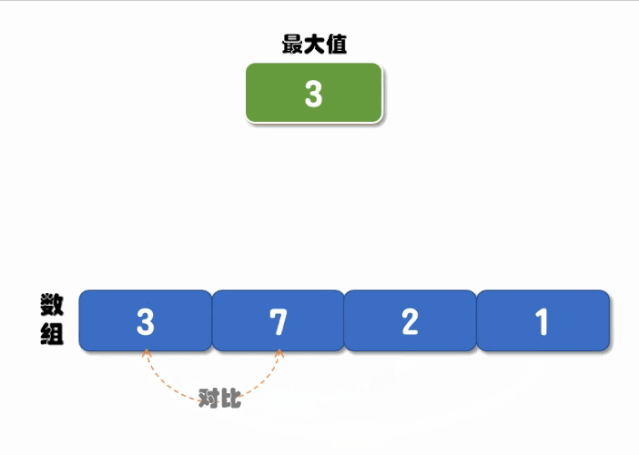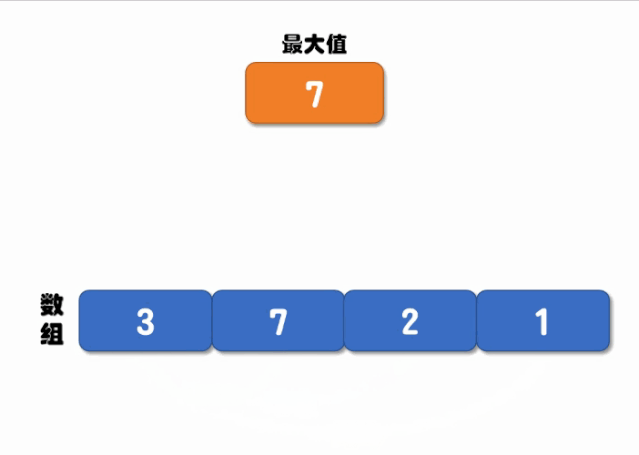
实现代码如下:
public class ArrayMax {
public static void main(String[] args) {
int[] arr = {3, 7, 2, 1, -4};
int max = findMaxByRecursive(arr, 0, arr.length - 1, 0); // 根据 Collections 查找最大值
System.out.println("最大值是:" + max);
}
/**
* 根据递归查询最大的值
* @param arr 待查询数组
* @param head 最前面的元素的下标
* @param last 最末尾的元素的下标
* @param max (临时)最大值
* @return 最大值
*/
private static int findMaxByRecursive(int[] arr, int head, int last, int max) {
if (head == last) {
// 递归完了,返回结果
return max;
} else {
if (arr[head] > arr[last]) {
max = arr[head]; // 赋最大值
// 从后往前移动递归
return findMaxByRecursive(arr, head, last - 1, max);
} else {
max = arr[last]; // 赋最大值
// 从前往后移动递归
return findMaxByRecursive(arr, head + 1, last, max);
}
}
}
}以上程序的执行结果为:
最大值是:7
方式三:依赖 Arrays.sort() 实现
根据 Arrays.sort 方法可以将数组从小到大进行排序,排序完成之后,取最后一位的值就是最大值了,实现代码如下:
import java.util.Arrays;
public class ArrayMax {
public static void main(String[] args) {
int[] arr = {3, 7, 2, 1, -4};
int max = findMaxBySort(arr); // 根据 Arrays.sort 查找最大值
System.out.println("最大值是:" + max);
}
/**
* 根据 Arrays.sort 查找最大值
* @param arr 待查询数组
* @return 最大值
*/
private static int findMaxBySort(int[] arr) {
Arrays.sort(arr);
return arr[arr.length - 1];
}
}以上程序的执行结果为:
最大值是:7
方式四:根据 Arrays.stream() 实现
stream 是 JDK 8 新增的核心功能之一,使用它我们可以很方便的实现很多功能,比如查找最大值、最小值等,实现代码如下:
import java.util.Arrays;
public class ArrayMax {
public static void main(String[] args) {
int[] arr = {3, 7, 2, 1, -4};
int max = findMaxByStream(arr); // 根据 stream 查找最大值
System.out.println("最大值是:" + max);
}
/**
* 根据 stream 查找最大值
* @param arr 待查询数组
* @return 最大值
*/
private static int findMaxByStream(int[] arr) {
return Arrays.stream(arr).max().getAsInt();
}
}以上程序的执行结果为:
最大值是:7
方式五:依赖 Collections.max() 实现
使用 Collections 集合工具类也可以查找最大值和最小值,但在使用之前我们想要将数组(Array)转换成集合(List),实现代码如下:
import org.apache.commons.lang3.ArrayUtils;
import java.util.Arrays;
import java.util.Collections;
public class ArrayMax {
public static void main(String[] args) {
int[] arr = {3, 7, 2, 1, -4};
int max = findMaxByCollections(arr); // 根据 Collections 查找最大值
System.out.println("最大值是:" + max);
}
/**
* 根据 Collections 查找最大值
* @param arr 待查询数组
* @return 最大值
*/
private static int findMaxByCollections(int[] arr) {
List<Integer> list = Arrays.asList(
org.apache.commons.lang3.ArrayUtils.toObject(arr));
return Collections.max(list);
}
}以上程序的执行结果为:
最大值是:7
扩展知识:Arrays.sort 方法执行原理
为了搞明白 Arrays#sort 方法执行的原理,我们查看了源码发现 sort 方法的核心是通过循环进行排序的,源码如下:
for (int i = left, j = i; i < right; j = ++i) {
int ai = a[i + 1];
while (ai < a[j]) {
a[j + 1] = a[j];
if (j-- == left) {
break;
}
}
a[j + 1] = ai;
}执行流程如下图所示:

总结
本文介绍了 5 种查询数组中最大值的方法,从大的维度可分为:手动实现和依赖接口实现。手动实现主要是通过循环和递归对比的方式,但这种方式并不推荐,因为它不够优雅;依赖接口实现的方法有很多,其中主要推荐使用的是使用 stream 来实现查找最大值,因为它足够简单优雅。
以上就是W3Cschool编程狮关于图解| Java查找数组中最大值的5种方法!的相关介绍了,希望对大家有所帮助。
听说vue项目不用build也能用?
文章来源于公众号:小丑的小屋
人们经常说 Vue JS 或 React 是多么简单,甚至微不足道。嗯… 我不同意。它们不简单。毕竟,它们被广泛用于构建大规模的、通常是关键任务的系统。除了这些过于乐观的课程,还有很多东西需要学习。它们的生态系统是巨大的。工具要求很高。文档非常丰富。发现和理解最佳实践和高效的设计模式需要付出大量的努力。
那么他们的吸引力是什么呢?对我来说,这是他们进步性。只有在必要的时候,复杂性才会逐渐引入项目。我可以从简单的 JavaScript 开始,有一些先决条件,不需要复杂的构建设置。然后,随着需求的增长,我开始添加新的概念,并学习如何使用它们。诸如模块、组件、路由、状态管理、状态传播、异步代码、响应式、服务器端呈现之类的东西最终都会出现在图片中。但只有当他们的时间到来,只有当我准备好了他们!
这篇文章的源代码可以在 bitbucket.org/letsdebugit/minimalistic-vue 中找到,你可以在这里运行示例应用程序。
简单项目的简单工具
当我开始一个新项目时,简单开始是至关重要的。这个职业的认知负担已经够重的了。我不需要更多了,除非真的需要。同样重要的是,只要应用程序保持简单,项目设置就保持简单。对于许多项目来说,我所需要的只是一个网页背后的小小的智能引擎。一些可以连接照片库的东西。可以从外部源获取更新并保持 UI 同步。为什么我要为此而引入 TypeScript 和 webpack 呢?但是 Vanilla JS 的成本很高。我喜欢拥有诸如状态管理、响应式和数据绑定之类的东西。它们节省了很多时间,并且有助于构建一个一致的用户界面。幸运的是,这在进步的 web 框架中是可能的。在下面的示例中,我想展示如何以最简单的方式介绍 Vue JS 并享受其功能。
应用程序设计
下面的例子是一个小小的单页网页应用程序。它有一个页眉,内容区域和页脚。在内容区域有一条消息和一个按钮。当用户点击按钮时,消息会发生变化:

作为一个谨慎的程序员,我希望从一开始就正确地构造应用程序。在用户界面中有以下元素:
- header
- main area
- footer
我希望将每个组件定义为一个单独的组件。我希望将他们的代码放在单独的模块中,以便于识别和使用。
在一个典型的 Vue JS 设置中,您将使用 .vue 的单组件文件。不幸的是,这需要一个基于 webpack、 rollup 等的构建过程。事实证明,您可以在不使用任何构建过程的情况下获得几乎相同的体验!它可能不像原来的协议那么全面,但是对于许多简单的场景来说还是不错的。更重要的是,它没有常规构建过程和 CLI 工具引入的复杂性和依赖性。
工程项目结构
该项目的结构如下:
index.html
index.js
index.css
header/
header.js
header.css
content/
content.js
content.css
footer/
footer.js
footer.css我们的逻辑 UI 组件清楚地反映在项目的目录结构中。
自力更生
当浏览器加载 index. html 时,会发生以下情况:
- Vue JS 库是从 CDN 库中获取的 unpkg.com/vue
- 获取组件样式
- 应用程序模块从 index.js 导出然后被执行
注意我们是如何使用 < script type = ” module” & 来告诉浏览器我们正在加载所有花里胡哨的现代 ES6 代码!
当执行 index.js 时,它会导入包含我们的组件的后续模块:
Content from 内容来自/content/content.js
Header from 标题来自/header/header.js
Footer from 的页脚/footer/footer.js这些组件与常规的 Vue JS 单文件组件没有多大区别。它们可以拥有 Vue JS 组件的所有特性和功能,比如:
data
props
methods
computed
lifecycle events
slots
template with markup
etc. 因为没有构建过程,我们的组件必须以不同的方式组合在一起。现代的 JavaScript 特性在这方面对我们有所帮助。与打包相反,我们可以在任何需要的地方import所需的依赖项。经过这么多年不费脑筋的打包浏览器终于知道如何导入模块; 然后,我们将使用 JS 模板文本代替template。
组件代码的结构如下:
const template = `
<div>
...
</div>
`
export default {
template,
data () {
},
computed: {
},
// etc.
}主要的应用程序组件在 index.js 文件中。它的任务是为所有组件分配定制的 HTML 标记,比如 < app-header > 或 < app-footer > 。
import Header from './header/header.js'
import Content from './content/content.js'
import Footer from './footer/footer.js'
const App = {
el: 'main',
components: {
'app-header': Header,
'app-content': Content,
'app-footer': Footer
}
}
window.addEventListener('load', () => {
new Vue(App)
})然后使用这些自定义标记在 index. html 文件中构建应用程序 UI。我们最终得到了一个简单易懂的用户界面:
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<title>Minimalistic Vue JS</title>
<link rel="stylesheet" href="index.css">
<link rel="stylesheet" href="header/header.css">
<link rel="stylesheet" href="content/content.css">
<link rel="stylesheet" href="footer/footer.css">
<script src="https://unpkg.com/vue">
</script>
<script src="index.js" type="module">
</script>
</head>
<body>
<main>
<app-header bg-color="#c5cae2">
</app-header>
<app-content>
</app-content>
<app-footer>
(c) Tomasz Waraksa, Dublin, Ireland
</app-footer>
</main>
</body>
</html>路由选择
一个不那么琐碎的应用程序通常会有一大堆视图,用户可以导航到这些视图。事实证明,Vue 路由器在我们的设置中工作,没有任何问题。您可以像定义任何其他组件一样定义视图或页面,使用上面描述的相同方法。然后,不要将这些组件注册为自定义标记,而是用标准的方式将它们链接到路由,例如:
import Home from './home/home.js'
import About from './about/about.js'
export default [
{
name: 'home',
path: '/',
component: Home
},
{
name: 'about',
path: '/about',
component: About
}
]然后获取 Vue Router 库并在 index. html 中添加路由器占位符:
<head>
...
<script src="https://unpkg.com/vue-router">
</script>
</head>
<body>
...
<router-view>
</router-view>
...
</body>最后,在 index.js 中将路由器与应用程序一起初始化:
const router = new VueRouter({ routes })
const app = {
el: 'main',
router,
...
}现在,您可以通过输入 URL、使用 < router-link > 组件或以编程方式导航到这两个页面。
最后,我们几乎拥有了 Vue JS 的全部能力,而没有任何构建过程的复杂性。要部署这个应用程序,我们只需将文件复制到一个 web 服务器。然后只希望我们的访问者会使用一个像样的浏览器。
最后
这篇文章也可以在作者Tomasz Waraksa的博客 Let’s Debug It 上找到。完整的源代码可以在 google bitbucket.org/letsdebugit/minimalistic-vue 上找到。所有的荣誉和感谢都归功于 Vue JS 框架的创建者。
以上就是W3Cschool编程狮关于听说vue项目不用build也能用?的相关介绍了,希望对大家有所帮助。
重新认识Typescript | Vue3源码系列
以下文章来源于公众号:Vue中文社区 ,作者刀哥
初次见面
官方对其只用了一句话来描述
TypeScript is a typed superset of JavaScript that compiles to plain JavaScript. Any browser. Any host. Any OS. Open source.
大致意思为,TypeScript 是开源的,TypeScript 是 JavaScript 的类型的超集,它可以编译成纯 JavaScript。编译出来的 JavaScript 可以运行在任何浏览器上。TypeScript 编译工具可以运行在任何服务器和任何系统上
- 问题: 什么是超集
超集是集合论的术语 说到超集,不得不说另一个,子集,怎么理解这两个概念呢,举个例子
如果一个集合A里面的的所有元素集合B里面都存在,那么我们可以理解集合A是集合B的子集,反之集合B为集合A的超集
现在我们就能理解为 TypeScript 里包含了 Javascript 的所有特性,这也意味着我们可以将.js后缀直接命名为.ts文件跑到 TypeScript 的编绎系统中
Typescript 解决了什么问题
一个事物的诞生一定会有其存在的价值
那么 TypeScript 的价值是什么呢?
回答这个问题之前,我们有必要先来了解一下 TypeScript 的工作理念
本质上是在 Javascript 上增加一套静态类型系统(编译时进行类型分析),强调静态类型系统是为了和运行时的类型检查机制做区分,TypeScript 的代码最终会被编译为 Javascript
我们再回到问题本身,缩小一下范围,TypeScript 创造的价值大部分是在开发时体现的(编译时),而非运行时,如
- 强大的编辑器智能提示 (研发效率,开发体验)
- 代码可读性增强 (团队协作,开发体验)
- 编译时类型检查 (业务稳健,前端项目中Top10 的错误类型低级的类型错误占比达到70%)
正文
本篇文章作为 Vue3 源码系列前置篇章之一,Typescript 的科普文,主要目的为了大家在面对 Vue3 源码时不会显得那么不知所措,下来将介绍一些 Typescript 的基本使用
变量申明
基本类型
let isDone: boolean = false
let num: number = 1
let str: string = 'vue3js.cn'
let arr: number[] = [1, 2, 3]
let arr2: Array<number> = [1, 2, 3] // 泛型数组
let obj: Object = {}
let u: undefined = undefined;
let n: null = null;类型补充
- 枚举
Enum
使用枚举类型可以为一组数值赋予友好的名字
enum LogLevel {
info = 'info',
warn = 'warn',
error = 'error',
}- 元组
Tuple
允许数组各元素的类型不必相同。比如,你可以定义一对值分别为 string和number类型的元组
// Declare a tuple type
let x: [string, number];
// Initialize it
x = ['hello', 10]; // OK
// Initialize it incorrectly
x = [10, 'hello']; // Error- 任意值
Any
表示任意类型,通常用于不确定内容的类型,比如来自用户输入或第三方代码库
let notSure: any = 4;
notSure = "maybe a string instead";
notSure = false; // okay, definitely a boolean- 空值
Void
与 any 相反,通常用于函数,表示没有返回值
function warnUser(): void {
console.log("This is my warning message");
}- 接口
interface
类型契约,跟我们平常调服务端接口要先定义字段一个理
如下例子 point 跟 Point 类型必须一致,多一个少一个也是不被允许的
interface Point {
x: number
y: number
z?: number
readonly l: number
}
const point: Point = { x: 10, y: 20, z: 30, l: 40 }
const point2: Point = { x: '10', y: 20, z: 30, l: 40 } // Error
const point3: Point = { x: 10, y: 20, z: 30 } // Error
const point4: Point = { x: 10, y: 20, z: 30, l: 40, m: 50 } // Error
可选与只读 ? 表示可选参, readonly 表示只读
const point5: Point = { x: 10, y: 20, l: 40 } // 正常
point5.l = 50 // error函数参数类型与返回值类型
function sum(a: number, b: number): number {
return a + b
} 配合 interface 使用
interface Point {
x: number
y: number
}
function sum({ x, y}: Point): number {
return x + y
}
sum({x:1, y:2}) // 3泛型
泛型的意义在于函数的重用性,设计原则希望组件不仅能够支持当前的数据类型,同时也能支持未来的数据类型
- 比如
根据业务最初的设计函数 identity 入参为String
function identity(arg: String){
return arg
}
console.log(identity('100')) 业务迭代过程参数需要支持 Number
function identity(arg: String){
return arg
}
console.log(identity(100)) // Argument of type '100' is not assignable to parameter of type 'String'.为什么不用any呢?
使用 any 会丢失掉一些信息,我们无法确定返回值是什么类型 泛型可以保证入参跟返回值是相同类型的,它是一种特殊的变量,只用于表示类型而不是值
语法 <T>(arg:T):T 其中T为自定义变量
const hello : string = "Hello vue!"
function say<T>(arg: T): T {
return arg;
}
console.log(say(hello)) // Hello vue! 泛型约束
我们使用同样的例子,加了一个console,但是很不幸运,报错了,因为泛型无法保证每种类型都有.length 属性
const hello : string = "Hello vue!"
function say<T>(arg: T): T {
console.log(arg.length) // Property 'length' does not exist on type 'T'.
return arg;
}
console.log(say(hello)) // Hello vue! 从这里我们也又看出来一个跟any不同的地方,如果我们想要在约束层面上就结束战斗,我们需要定义一个接口来描述约束条件
interface Lengthwise {
length: number;
}
function say<T extends Lengthwise>(arg: T): T {
console.log(arg.length)
return arg;
}
console.log(say(1)) // Argument of type '1' is not assignable to parameter of type 'Lengthwise'.
console.log(say({value: 'hello vue!', length: 10})) // { value: 'hello vue!', length: 10 } 交叉类型
交叉类型(Intersection Types),将多个类型合并为一个类型
interface foo {
x: number
}
interface bar {
b: number
}
type intersection = foo & bar
const result: intersection = {
x: 10,
b: 20
}
const result1: intersection = {
x: 10
} // error联合类型
交叉类型(Union Types),表示一个值可以是几种类型之一。我们用竖线 | 分隔每个类型,所以 number | string | boolean表示一个值可以是 number, string,或 boolean
type arg = string | number | boolean
const foo = (arg: arg):any =>{
console.log(arg)
}
foo(1)
foo('2')
foo(true)函数重载
函数重载(Function Overloading), 允许创建数项名称相同但输入输出类型或个数不同的子程序,可以简单理解为一个函数可以执行多项任务的能力
例我们有一个add函数,它可以接收string类型的参数进行拼接,也可以接收number类型的参数进行相加
function add (arg1: string, arg2: string): string
function add (arg1: number, arg2: number): number
// 实现
function add <T,U>(arg1: T, arg2: U) {
// 在实现上我们要注意严格判断两个参数的类型是否相等,而不能简单的写一个 arg1 + arg2
if (typeof arg1 === 'string' && typeof arg2 === 'string') {
return arg1 + arg2
} else if (typeof arg1 === 'number' && typeof arg2 === 'number') {
return arg1 + arg2
}
}
add(1, 2) // 3
add('1','2') //'12'总结
通过本篇文章,相信大家对Typescript不会再感到陌生了
下面我们来看看在Vue源码Typescript是如何书写的,这里我们以defineComponent函数为例,大家可以通过这个实例,再结合文章的内容,去理解,加深Typescript的认识
// overload 1: direct setup function
export function defineComponent<Props, RawBindings = object>(
setup: (
props: Readonly<Props>,
ctx: SetupContext
) => RawBindings | RenderFunction
): {
new (): ComponentPublicInstance<
Props,
RawBindings,
{},
{},
{},
// public props
VNodeProps & Props
>
} & FunctionalComponent<Props>
// defineComponent一共有四个重载,这里省略三个
// implementation, close to no-op
export function defineComponent(options: unknown) {
return isFunction(options) ? { setup: options } : options
} 以上就是W3Cschool编程狮关于重新认识Typescript | Vue3源码系列的相关介绍了,希望对大家有所帮助。
如何减少开发中的 Bug
文章来源于公众号:前端瓶子君 作者:jartto
一、概述
爱因斯坦曾经说过:「如果给我一个小时解答一道决定我生死的问题,我会花55分钟来弄清楚这道题到底是在问什么。一旦清楚了它在问什么,剩下的5分钟足够解答这个问题。」
虽然我们软件开发过程不会面临生死的抉择,但是却直接影响着用户的使用感受,决定着产品的走向。所以程序员如何减少开发中的 Bug,既反映了代码质量,也反映了个人综合能力。
那么我们该如何有效的减少开发中的 Bug 呢?
我觉得应该从两方面说起:业务层和代码层。
二、业务层
软件开发过程我们就不细说了,直接来看最重要的几个节点:
1.需求讨论阶段 一定要明确需求,测试,开发,产品三方务必达成一致。前期如果存在没有明确的问题,那么后期就会造成无效返工和不必要的争执,这在日常开发尤为常见。
所以,软件开发前期,我们都会进行「评审,反讲,评估」三个阶段。
2.开发完成阶段 开发完成后,程序员首先要完成「自测」,也就是软件开发中的「冒烟测试」,确保主流程无误。否则,在开发工程师提交代码后,测试工程师步履维艰,无法有效开展测试,会造成极大的资源浪费。
更规范的流程需要测试工程师在需求明确之后写出「测试用例」,开发工程师在完成开发后,自行对照「测试用例」完成初步验证,之后就可以代码提测了。
这么做的好处就是既保证了「高质量的代码交付」,同时减少了测试工程师的工作量,我们何乐而不为呢?
3.提测 自测和提测有什么区别呢,从软件开发过程来看,其实开发工程师和测试工程师其实完成了不同阶段的测试:
开发工程师「白盒测试」: 是指实际运行被测程序,通过程序的源代码进行测试而不使用用户界面。这种类型的测试需要从代码句法发现内部代码在算法、溢出、路径和条件等方面的缺点或者错误,进而加以修正。
白盒测试需要从代码句法发现内部代码在算法,溢出,路径,条件等等中的缺点或者错误,进而加以修正。
测试工程师实际进行的是「黑盒测试」。那么什么是「黑盒测试」呢? 黑盒测试也称功能测试,它是通过测试来检测每个功能是否都能正常使用。在测试中,把程序看作一个不能打开的黑盒子,在完全不考虑程序内部结构和内部特性的情况下,在程序接口进行测试。
它只检查程序功能是否按照需求规格说明书的规定正常使用,程序是否能适当地接收输入数据而产生正确的输出信息。黑盒测试着眼于程序外部结构,不考虑内部逻辑结构,主要针对软件界面和软件功能进行测试。
黑盒测试是以用户的角度,从输入数据与输出数据的对应关系出发进行测试的。
很明显,如果外部特性本身设计有问题或规格说明的规定有误,用黑盒测试方法是发现不了的。黑盒测试法注重于测试软件的功能需求,主要试图发现下列几类错误。
功能不正确或遗漏;界面错误;输入和输出错误;数据库访问错误;性能错误;初始化和终止错误等;三、代码层
代码层面,我们需要从以下几方面来说起:
1.Eslint 规避低级语法问题 这个显而易见,编写代码过程发现问题,避免因为简单语法,如:漏写了逗号,变量名写错,大小写问题等
2.边界处理 做好容错,必要的判空,还有就是代码边界问题。多想一想如果数组不存在,我们如何处理?如果数组越界,我们如何修复?如果数据缺失,我们如何使页面不崩溃?
3.单元测试 如果时间允许,我们可以做好单元测试,每次编译代码,或者提测前启动脚本,确定测试脚本都覆盖到了核心代码,尽可能减少代码出错率。
4.积累 为什么说要积累,其实道理很简单。随着开发经验的增长,你可能会碰到很多问题,那么如果细心积累,其实很多错误在不知不觉中就被处理了。反之,你会不断的掉入同一个坑里,在进坑与出坑中迷失自我。那么我们如何积累呢?
首先,碰到自己不会的问题,如果第一时间没有解决,通过查找或者请教别人解决了,那么一定要用小本本记下来,最好使用云笔记。好处不言自明。
其次,要积累自己的函数库,我们经常用到的一些方法,不妨自己做一个封装,不断沉淀。也许有一天,你会发现,自己不知不知觉中写出了一个 Lodash 函数库。
最后,你可以积累优秀的代码片段,嗯,「我们不生产代码,只是优秀代码的搬运工」。
5.学习 一句话,没有什么比学习优秀开源代码更有趣的事情了。阅读优秀源码,学习作者思想,站在巨人肩膀上,你才能走的更远!
做好上面这些,相信你一定会是一位出色的工程师。
四、总结
对于这类开放问题仁者见仁,智者见智,我相信每个人都会有自己的看法,也会有自己一套独特的方法。不管黑猫白猫,能抓住老鼠的就是好猫。对于程序员来说,能减少 Bug 的方法就是好方法。
以上就是W3Cschool编程狮关于如何减少开发中的 Bug的相关介绍了,希望对大家有所帮助。
程序员群体流传一句话:不写代码就有没有 Bug。
我们不能因为怕犯错误而减少写代码,更应该知难而上,越挫越勇。要知道日常开发中 「Bug 是不可避免的,只能减少」。
当然,这不应该成为我们写出 Bug 推脱的理由。不断超越,方是永恒。
10个具有挑战性的JavaScript测验问答【附答案分析】!
文章来源于公众号:前端人
以下 JavaScript 问题旨在具有挑战性和指导意义。如果您确切地知道如何回答每个问题,那很好,但是如果您遇到了一些错误并知道原因,那么我认为那会更好!
问题1:IIFE,HOF
以下代码段是否立即调用函数表达式(IIFE),高阶函数(HOF),或者两者都没有?
((fn, val) => {
return fn(val);
})(console.log, 5);答案:输出5
问题2:下列数组转对象方法中,哪个更合适?
const arr = [1, 2, 3];
//第一种
const a = arr.reduce(
(acc, el, i) => ({ ...acc, [el]: i }),
{}
);
//第二种
const b = {};
for (let i = 0; i < arr.length; i++) {
b[arr[i]] = i;
}答案:第二种
当 b 对象被设置时,b[arr[i]]属性被设置为在每次迭代的当前索引。设置a时,扩展语法(…)将 acc 在每次迭代时创建累加器对象()的浅拷贝,并另外设置新属性。与不执行浅拷贝相比,此浅拷贝更加浪费。a需要在达到结果之前构造2个中间对象,而 b 不会构造任何中间对象。因此,b 被更有效地设置。
问题3
考虑以下函数:superheroMaker的功能。当我们传递以下两个参数时,输出什么?
const superheroMaker = a => {
return a instanceof Function ? a() : a;
};
console.log(superheroMaker(() => 'Batman'));
console.log(superheroMaker('Superman'));答案:输出"Batman" "Superman"
传递() => 'Batman'给superheroMaker时,a是的实例Function。因此,将调用该函数,并返回字符串 "Batman"。当传递"Superman"给superheroMaker时,a它不是的实例,Function因此"Superman"仅返回字符串。因此,输出为”Batman”和”Superman”。
问题4:Object.keys是否等于Object.values?
Object Keys, Object Values
const obj = {
1: 1,
2: 2,
3: 3
};
console.log(Object.keys(obj) == Object.values(obj));答案:输出false
在这种情况下,Object.keys将键转换为字符串["1", "2", "3"],但是Object.values返回的是:[1, 2, 3]。即使值的类型相同,但是他们不是同一个对象,所以相等比较将返回false。
问题5:基本递归考察?
考虑以下递归函数。如果将字符串传递”Hello World”给它,输出什么?
const myFunc = str => {
if (str.length > 1) {
return myFunc(str.slice(1));
}
return str;
};
console.log(myFunc('Hello world'));答案:输出"d"
第一次调用该函数时,str.length 它大于1(”Hello World”即11个字符),因此我们返回调用的相同函数str.slice(1),即string “ello World”。我们重复此过程,直到字符串只有一个字符长:该字符”d”,该字符将返回到初始调用 myFunc 。然后,我们记录该字符。
问题6:函数相等
以下代码输出什么?
const a = c => c;
const b = c => c;
console.log(a == b);
console.log(a(7) === b(7));答案:输出false,true
在第一个测试中,a和b是内存中的不同对象;每个函数定义中的参数和返回值相同都没关系。因此,a不等于b。在第二个测试中,a(7) 返回数字7并 b(7) 返回 number 7。这些原始类型彼此严格相等。
在这种情况下,相等(==)与身份(===)比较运算符无关紧要;任何类型的强制都不会影响结果。
问题7:对象属性相等
a并且b具有相同的不同对象firstName属性。这些属性是否彼此严格相等?
const a = {
firstName: 'Bill'
};
const b = {
firstName: 'Bill'
};
console.log(a.firstName === b.firstName);答案:输出true
答案是肯定的。a.firstName是字符串值”Bill”,b.firstName是字符串值”Bill”。两个相同的字符串始终相等。
问题8:函数函数语法
假设myFunc是一个函数,val1是一个变量,并且val2是一个变量。JavaScript是否允许以下语法?
myFunc(val1)(val2);答案:允许
这是高阶函数的常见模式。如果myFunc(val1)返回一个函数,则该函数将val2作为参数被调用。这是一个实际的示例,您可以尝试一下:
const timesTable = num1 => {
return num2 => {
return num1 * num2;
};
};
console.log(timesTable(4)(5));
// 20问题9:对象属性突变
const a = { firstName: 'Joe' };
const b = a;
b.firstName = 'Pete';
console.log(a);答案:输出{ firstName: 'Pete' }
当我们b = a在第二行中设置时,b并a指向内存中的同一对象。因此firstName,b将属性更改为on 将更改firstName内存中唯一对象的属性,因此a.firstName将反映此更改。
问题10:数组中的最大数
以下函数将始终返回数组中的最大数字吗?
function greatestNumberInArray(arr) {
let greatest = 0;
for (let i = 0; i < arr.length; i++) {
if (greatest < arr[i]) {
greatest = arr[i];
}
}
return greatest;
}答案:输出不是
如果数组中有一个值大于0,则是正确的,如果都是小于0的话,它将返回0。
对于至少一个值0大于或等于一个的数组,此函数才是正确的。但是,如果所有数字均低于,它将返回0。
以上就是W3Cschool编程狮关于10个具有挑战性的JavaScript测验问答的相关介绍了,希望对大家有所帮助。
Vue 进阶面试必问,异步更新机制和 nextTick 原理
以下文章来源于前端下午茶 ,作者SHERlocked93
vue 已是目前国内前端web端三分天下之一,同时也作为本人主要技术栈之一,在日常使用中知其然也好奇着所以然,另外最近的社区涌现了一大票 vue 源码阅读类的文章,在下借这个机会从大家的文章和讨论中汲取了一些营养,同时对一些阅读源码时的想法进行总结,出产一些文章,作为自己思考的输出
目标Vue版本:2.5.17-beta.0
vue 源码注释:github.com/SHERlocked93/vue-analysis
声明:文章中源码的语法都使用 Flow,并且源码根据需要都有删节(为了不被迷糊 @_@),如果要看完整版的请进入上面的github地址
1. 异步更新
上一篇文章我们在依赖收集原理的响应式化方法 defineReactive 中的 setter 访问器中有派发更新 dep.notify() 方法,这个方法会挨个通知在 dep 的 subs 中收集的订阅自己变动的 watchers 执行 update 。一起来看看 update 方法的实现:
// src/core/observer/watcher.js
/* Subscriber接口,当依赖发生改变的时候进行回调 */
update() {
if (this.computed) {
// 一个computed watcher有两种模式:activated lazy(默认)
// 只有当它被至少一个订阅者依赖时才置activated,这通常是另一个计算属性或组件的render function
if (this.dep.subs.length === 0) { // 如果没人订阅这个计算属性的变化
// lazy时,我们希望它只在必要时执行计算,所以我们只是简单地将观察者标记为dirty
// 当计算属性被访问时,实际的计算在this.evaluate()中执行
this.dirty = true
} else {
// activated模式下,我们希望主动执行计算,但只有当值确实发生变化时才通知我们的订阅者
this.getAndInvoke(() => {
this.dep.notify() // 通知渲染watcher重新渲染,通知依赖自己的所有watcher执行update
})
}
} else if (this.sync) { // 同步
this.run()
} else {
queueWatcher(this) // 异步推送到调度者观察者队列中,下一个tick时调用
}
} 如果不是 computed watcher 也非 sync 会把调用 update 的当前 watcher 推送到调度者队列中,下一个 tick 时调用,看看 queueWatcher :
// src/core/observer/scheduler.js
/* 将一个观察者对象push进观察者队列,在队列中已经存在相同的id则
* 该watcher将被跳过,除非它是在队列正被flush时推送
*/
export function queueWatcher (watcher: Watcher) {
const id = watcher.id
if (has[id] == null) { // 检验id是否存在,已经存在则直接跳过,不存在则标记哈希表has,用于下次检验
has[id] = true
queue.push(watcher) // 如果没有正在flush,直接push到队列中
if (!waiting) { // 标记是否已传给nextTick
waiting = true
nextTick(flushSchedulerQueue)
}
}
}
/* 重置调度者状态 */
function resetSchedulerState () {
queue.length = 0
has = {}
waiting = false
} 这里使用了一个 has 的哈希map用来检查是否当前 watcher 的 id 是否存在,若已存在则跳过,不存在则就 push 到 queue 队列中并标记哈希表 has,用于下次检验,防止重复添加。这就是一个去重的过程,比每次查重都要去 queue 中找要文明,在渲染的时候就不会重复patch 相同 watcher 的变化,这样就算同步修改了一百次视图中用到的 data,异步 patch的时候也只会更新最后一次修改。
这里的 waiting 方法是用来标记 flushSchedulerQueue 是否已经传递给 nextTick 的标记位,如果已经传递则只 push 到队列中不传递 flushSchedulerQueue 给 nextTick,等到 resetSchedulerState 重置调度者状态的时候 waiting 会被置回 false 允许 flushSchedulerQueue 被传递给下一个 tick 的回调,总之保证了 flushSchedulerQueue 回调在一个 tick 内只允许被传入一次。来看看被传递给 nextTick 的回调 flushSchedulerQueue 做了什么:
// src/core/observer/scheduler.js
/* nextTick的回调函数,在下一个tick时flush掉两个队列同时运行watchers */
function flushSchedulerQueue () {
flushing = true
let watcher, id
queue.sort((a, b) => a.id - b.id) // 排序
for (index = 0; index < queue.length; index++) { // 不要将length进行缓存
watcher = queue[index]
if (watcher.before) { // 如果watcher有before则执行
watcher.before()
}
id = watcher.id
has[id] = null // 将has的标记删除
watcher.run() // 执行watcher
if (process.env.NODE_ENV !== 'production' && has[id] != null) { // 在dev环境下检查是否进入死循环
circular[id] = (circular[id] || 0) + 1 // 比如user watcher订阅自己的情况
if (circular[id] > MAX_UPDATE_COUNT) { // 持续执行了一百次watch代表可能存在死循环
warn() // 进入死循环的警告
break
}
}
}
resetSchedulerState() // 重置调度者状态
callActivatedHooks() // 使子组件状态都置成active同时调用activated钩子
callUpdatedHooks() // 调用updated钩子
} 在 nextTick 方法中执行 flushSchedulerQueue 方法,这个方法挨个执行 queue 中的watcher的 run 方法。我们看到在首先有个 queue.sort() 方法把队列中的 watcher 按 id 从小到大排了个序,这样做可以保证:
- 组件更新的顺序是从父组件到子组件的顺序,因为父组件总是比子组件先创建。
- 一个组件的 user watchers (侦听器watcher)比 render watcher 先运行,因为 user watchers 往往比 render watcher 更早创建
- 如果一个组件在父组件 watcher 运行期间被销毁,它的 watcher 执行将被跳过
在挨个执行队列中的 for 循环中,index < queue.length 这里没有将 length 进行缓存,因为在执行处理现有 watcher 对象期间,更多的 watcher 对象可能会被 push 进 queue。
那么数据的修改从 model 层反映到 view 的过程:数据更改 -> setter -> Dep -> Watcher -> nextTick -> patch -> 更新视图
2. nextTick原理
2.1 宏任务/微任务
这里就来看看包含着每个 watcher 执行的方法被作为回调传入 nextTick 之后,nextTick对这个方法做了什么。不过首先要了解一下浏览器中的 EventLoop、macro task、micro task几个概念,不了解可以参考一下 JS 与 Node.js 中的事件循环 这篇文章,这里就用一张图来表明一下后两者在主线程中的执行关系:

解释一下,当主线程执行完同步任务后:
- 引擎首先从 macrotask queue 中取出第一个任务,执行完毕后,将 microtask queue 中的所有任务取出,按顺序全部执行;
- 然后再从 macrotask queue 中取下一个,执行完毕后,再次将 microtask queue 中的全部取出;
- 循环往复,直到两个 queue 中的任务都取完。
浏览器环境中常见的异步任务种类,按照优先级:
macro task:同步代码、setImmediate、MessageChannel、setTimeout/setIntervalmicro task:Promise.then、MutationObserver
有的文章把 micro task 叫微任务,macro task 叫宏任务,因为这两个单词拼写太像了 -。- ,所以后面的注释多用中文表示~
先来看看源码中对 micro task与 macro task 的实现:macroTimerFunc、microTimerFunc
// src/core/util/next-tick.js
const callbacks = [] // 存放异步执行的回调
let pending = false // 一个标记位,如果已经有timerFunc被推送到任务队列中去则不需要重复推送
/* 挨个同步执行callbacks中回调 */
function flushCallbacks() {
pending = false
const copies = callbacks.slice(0)
callbacks.length = 0
for (let i = 0; i < copies.length; i++) {
copies[i]()
}
}
let microTimerFunc // 微任务执行方法
let macroTimerFunc // 宏任务执行方法
let useMacroTask = false // 是否强制为宏任务,默认使用微任务
// 宏任务
if (typeof setImmediate !== 'undefined' && isNative(setImmediate)) {
macroTimerFunc = () => {
setImmediate(flushCallbacks)
}
} else if (typeof MessageChannel !== 'undefined' && (
isNative(MessageChannel) ||
MessageChannel.toString() === '[object MessageChannelConstructor]' // PhantomJS
)) {
const channel = new MessageChannel()
const port = channel.port2
channel.port1.onmessage = flushCallbacks
macroTimerFunc = () => {
port.postMessage(1)
}
} else {
macroTimerFunc = () => {
setTimeout(flushCallbacks, 0)
}
}
// 微任务
if (typeof Promise !== 'undefined' && isNative(Promise)) {
const p = Promise.resolve()
microTimerFunc = () => {
p.then(flushCallbacks)
}
} else {
microTimerFunc = macroTimerFunc // fallback to macro
} flushCallbacks 这个方法就是挨个同步的去执行 callbacks 中的回调函数们, callbacks 中的回调函数是在调用 nextTick 的时候添加进去的;那么怎么去使用 micro task 与 macro task 去执行 flushCallbacks 呢,这里他们的实现 macroTimerFunc、microTimerFunc 使用浏览器中宏任务/微任务的 API 对flushCallbacks 方法进行了一层包装。比如宏任务方法 macroTimerFunc=()=>{ setImmediate(flushCallbacks) },这样在触发宏任务执行的时候 macroTimerFunc() 就可以在浏览器中的下一个宏任务 loop 的时候消费这些保存在 callbacks 数组中的回调了,微任务同理。同时也可以看出传给 nextTick 的异步回调函数是被压成了一个同步任务在一个 tick 执行完的,而不是开启多个异步任务。
注意这里有个比较难理解的地方,第一次调用 nextTick 的时候 pending 为 false ,此时已经 push 到浏览器 event loop 中一个宏任务或微任务的 task,如果在没有 flush 掉的情况下继续往 callbacks 里面添加,那么在执行这个占位 queue 的时候会执行之后添加的回调,所以 macroTimerFunc、microTimerFunc 相当于 task queue 的占位,以后 pending 为 true 则继续往占位 queue 里面添加,event loop 轮到这个 task queue 的时候将一并执行。执行 flushCallbacks 时 pending 置 false,允许下一轮执行 nextTick 时往 event loop 占位。
可以看到上面 macroTimerFunc 与 microTimerFunc 进行了在不同浏览器兼容性下的平稳退化,或者说降级策略:
macroTimerFunc:setImmediate -> MessageChannel -> setTimeout。首先检测是否原生支持setImmediate,这个方法只在 IE、Edge 浏览器中原生实现,然后检测是否支持 MessageChannel,如果对MessageChannel不了解可以参考一下这篇文章,还不支持的话最后使用setTimeout;为什么优先使用setImmediate与MessageChannel而不直接使用setTimeout呢,是因为 HTML5 规定 setTimeout 执行的最小延时为4ms,而嵌套的 timeout 表现为10ms,为了尽可能快的让回调执行,没有最小延时限制的前两者显然要优于setTimeout。microTimerFunc:Promise.then -> macroTimerFunc。首先检查是否支持Promise,如果支持的话通过Promise.then来调用flushCallbacks方法,否则退化为macroTimerFunc;vue2.5之后nextTick中因为兼容性原因删除了微任务平稳退化的MutationObserver的方式。
2.2 nextTick实现
最后来看看我们平常用到的 nextTick 方法到底是如何实现的:
// src/core/util/next-tick.js
export function nextTick(cb?: Function, ctx?: Object) {
let _resolve
callbacks.push(() => {
if (cb) {
try {
cb.call(ctx)
} catch (e) {
handleError(e, ctx, 'nextTick')
}
} else if (_resolve) {
_resolve(ctx)
}
})
if (!pending) {
pending = true
if (useMacroTask) {
macroTimerFunc()
} else {
microTimerFunc()
}
}
if (!cb && typeof Promise !== 'undefined') {
return new Promise(resolve => {
_resolve = resolve
})
}
}
/* 强制使用macrotask的方法 */
export function withMacroTask(fn: Function): Function {
return fn._withTask || (fn._withTask = function() {
useMacroTask = true
const res = fn.apply(null, arguments)
useMacroTask = false
return res
})
} nextTick 在这里分为三个部分,我们一起来看一下;
- 首先
nextTick把传入的cb回调函数用try-catch包裹后放在一个匿名函数中推入callbacks数组中,这么做是因为防止单个cb如果执行错误不至于让整个JS线程挂掉,每个cb都包裹是防止这些回调函数如果执行错误不会相互影响,比如前一个抛错了后一个仍然可以执行。 - 然后检查
pending状态,这个跟之前介绍的queueWatcher中的waiting是一个意思,它是一个标记位,一开始是false在进入macroTimerFunc、microTimerFunc方法前被置为true,因此下次调用nextTick就不会进入macroTimerFunc、microTimerFunc方法,这两个方法中会在下一个macro/micro tick时候flushCallbacks异步的去执行callbacks队列中收集的任务,而flushCallbacks方法在执行一开始会把pending置false,因此下一次调用nextTick时候又能开启新一轮的macroTimerFunc、microTimerFunc,这样就形成了vue中的event loop。 - 最后检查是否传入了
cb,因为nextTick还支持Promise化的调用:nextTick().then(() => {}),所以如果没有传入cb就直接return了一个Promise实例,并且把resolve传递给_resolve,这样后者执行的时候就跳到我们调用的时候传递进then的方法中。
Vue源码中 next-tick.js 文件还有一段重要的注释,这里就翻译一下:
在vue2.5之前的版本中,nextTick基本上基于
micro task来实现的,但是在某些情况下micro task具有太高的优先级,并且可能在连续顺序事件之间(例如#4521,#6690)或者甚至在同一事件的事件冒泡过程中之间触发(#6566)。但是如果全部都改成macro task,对一些有重绘和动画的场景也会有性能影响,如 issue #6813。vue2.5之后版本提供的解决办法是默认使用micro task,但在需要时(例如在v-on附加的事件处理程序中)强制使用macro task。
为什么默认优先使用 micro task 呢,是利用其高优先级的特性,保证队列中的微任务在一次循环全部执行完毕。
强制 macro task 的方法是在绑定 DOM 事件的时候,默认会给回调的 handler 函数调用withMacroTask 方法做一层包装 handler = withMacroTask(handler),它保证整个回调函数执行过程中,遇到数据状态的改变,这些改变都会被推到 macro task 中。以上实现在 src/platforms/web/runtime/modules/events.js 的 add 方法中,可以自己看一看具体代码。
刚好在写这篇文章的时候思否上有人问了个问题 vue 2.4 和2.5 版本的 @input 事件不一样 ,这个问题的原因也是因为2.5之前版本的DOM事件采用 micro task ,而之后采用 macro task,解决的途径参考 < Vue.js 升级踩坑小记> 中介绍的几个办法,这里就提供一个在mounted钩子中用 addEventListener 添加原生事件的方法来实现,参见 CodePen。
3. 一个例子
说这么多,不如来个例子,执行参见 CodePen
<div id="app">
<span id='name' ref='name'>{{ name }}</span>
<button @click='change'>change name</button>
<div id='content'></div>
</div>
<script>
new Vue({
el: '#app',
data() {
return {
name: 'SHERlocked93'
}
},
methods: {
change() {
const $name = this.$refs.name
this.$nextTick(() => console.log('setter前:' + $name.innerHTML))
this.name = ' name改喽 '
console.log('同步方式:' + this.$refs.name.innerHTML)
setTimeout(() => this.console("setTimeout方式:" + this.$refs.name.innerHTML))
this.$nextTick(() => console.log('setter后:' + $name.innerHTML))
this.$nextTick().then(() => console.log('Promise方式:' + $name.innerHTML))
}
}
})
</script>执行以下看看结果:
同步方式:SHERlocked93
setter前:SHERlocked93
setter后:name改喽
Promise方式:name改喽
setTimeout方式:name改喽为什么是这样的结果呢,解释一下:
- 同步方式: 当把data中的name修改之后,此时会触发name的
setter中的dep.notify通知依赖本data的render watcher去update,update会把flushSchedulerQueue函数传递给nextTick,render watcher在flushSchedulerQueue函数运行时watcher.run再走diff -> patch那一套重渲染re-render视图,这个过程中会重新依赖收集,这个过程是异步的;所以当我们直接修改了name之后打印,这时异步的改动还没有被patch到视图上,所以获取视图上的DOM元素还是原来的内容。 - setter前: setter前为什么还打印原来的是原来内容呢,是因为
nextTick在被调用的时候把回调挨个push进callbacks数组,之后执行的时候也是for循环出来挨个执行,所以是类似于队列这样一个概念,先入先出;在修改name之后,触发把render watcher填入schedulerQueue队列并把他的执行函数flushSchedulerQueue传递给nextTick,此时callbacks队列中已经有了setter前函数了,因为这个cb是在setter前函数之后被push进callbacks队列的,那么先入先出的执行callbacks中回调的时候先执行setter前函数,这时并未执行render watcher的watcher.run,所以打印DOM元素仍然是原来的内容。 - setter后: setter后这时已经执行完
flushSchedulerQueue,这时render watcher已经把改动patch到视图上,所以此时获取DOM是改过之后的内容。 - Promise方式: 相当于
Promise.then的方式执行这个函数,此时DOM已经更改。 - setTimeout方式: 最后执行macro task的任务,此时DOM已经更改。
注意,在执行 setter前函数 这个异步任务之前,同步的代码已经执行完毕,异步的任务都还未执行,所有的 $nextTick 函数也执行完毕,所有回调都被push进了callbacks队列中等待执行,所以在setter前函数 执行的时候,此时callbacks队列是这样的:[setter前函数,flushSchedulerQueue,setter后函数,Promise方式函数],它是一个micro task队列,执行完毕之后执行macro task setTimeout,所以打印出上面的结果。
另外,如果浏览器的宏任务队列里面有setImmediate、MessageChannel、setTimeout/setInterval 各种类型的任务,那么会按照上面的顺序挨个按照添加进event loop中的顺序执行,所以如果浏览器支持MessageChannel, nextTick 执行的是macroTimerFunc,那么如果 macrotask queue 中同时有 nextTick 添加的任务和用户自己添加的 setTimeout 类型的任务,会优先执行 nextTick 中的任务,因为MessageChannel 的优先级比 setTimeout的高,setImmediate 同理。
以上就是W3Cschool编程狮关于Vue 进阶面试必问,异步更新机制和 nextTick 原理的相关介绍了,希望对大家有所帮助。