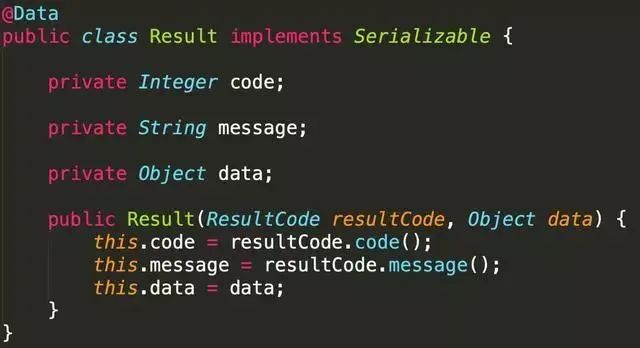
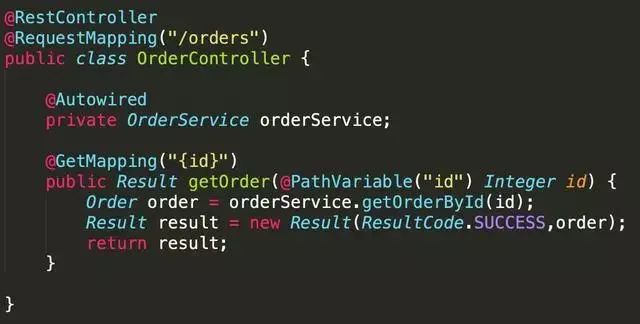
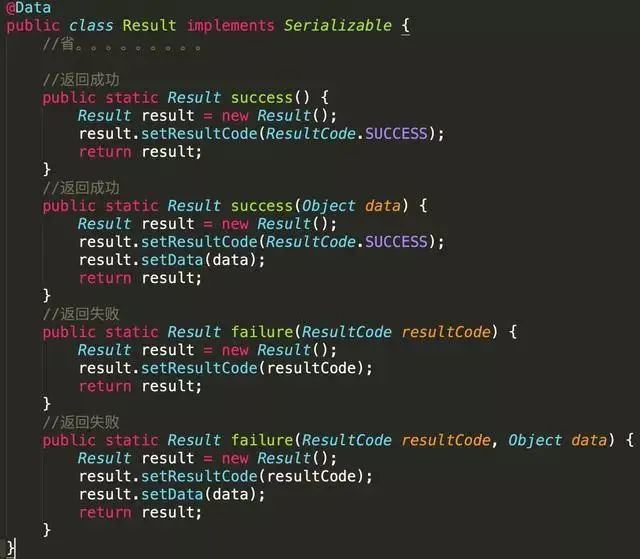
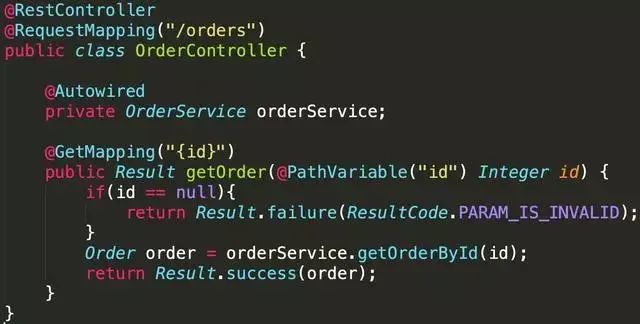
文章来源于公众号:码农知识点 ,作者Monica2333
ES7.x 版本的 x-pack 自带 ElasticSearch SQL,我们可以直接通过 SQL REST API、SQL CLI 等方式使用 SQL 查询。
SQL REST API
在Kibana Console中输入:
POST /_sql?format=txt
{
"query": "SELECT * FROM library ORDER BY page_count DESC LIMIT 5"
}
将上述 SQL 替换为你自己的 SQL 语句,即可。返回格式如下:
author | name | page_count | release_date
-----------------+--------------------+---------------+------------------------
Peter F. Hamilton|Pandora's Star |768 |2004-03-02T00:00:00.000Z
Vernor Vinge |A Fire Upon the Deep|613 |1992-06-01T00:00:00.000Z
Frank Herbert |Dune |604 |1965-06-01T00:00:00.000Z
SQL CLI
elasticsearch-sql-cli 是安装 ES 时 bin 目录的一个脚本文件,也可单独下载。我们在 ES 目录运行
./bin/elasticsearch-sql-cli https://some.server:9200
输入 SQL 即可查询
sql> SELECT * FROM library WHERE page_count > 500 ORDER BY page_count DESC;
author | name | page_count | release_date
-----------------+--------------------+---------------+---------------
Peter F. Hamilton|Pandora's Star |768 |1078185600000
Vernor Vinge |A Fire Upon the Deep|613 |707356800000
Frank Herbert |Dune |604 |-144720000000
SQL To DSL
在Kibana输入:
POST /_sql/translate
{
"query": "SELECT * FROM library ORDER BY page_count DESC",
"fetch_size": 10
}
即可得到转化后的 DSL query:
{
"size": 10,
"docvalue_fields": [
{
"field": "release_date",
"format": "epoch_millis"
}
],
"_source": {
"includes": [
"author",
"name",
"page_count"
],
"excludes": []
},
"sort": [
{
"page_count": {
"order": "desc",
"missing": "_first",
"unmapped_type": "short"
}
}
]
}
因为查询相关的语句已经生成,我们只需要在这个基础上适当修改或不修改就可以愉快使用 DSL 了。
下面我们详细介绍下 ES SQL 支持的SQL语句 和 如何避免错误使用。
首先需要了解下 ES SQL 支持的 SQL 语句中,SQL 术语和ES术语的对应关系:
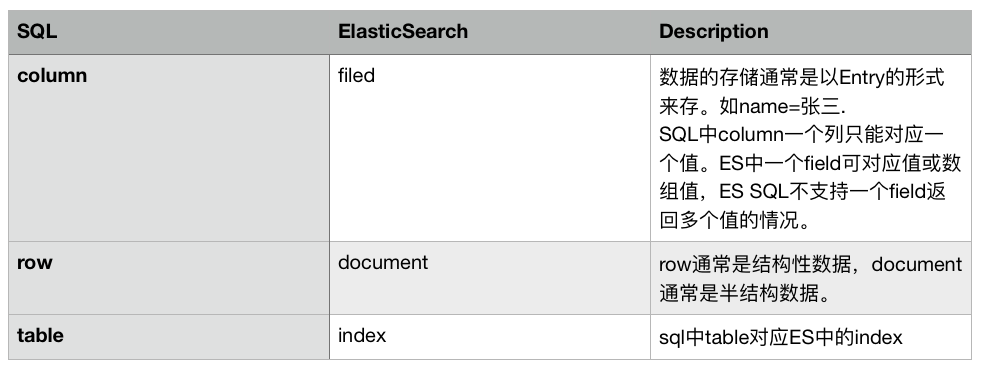
ES SQL 的语法支持大多遵循 ANSI SQL 标准,支持的 SQL 语句有 DML 查询和部分 DDL 查询。 DDL 查询如:DESCRIBE table,SHOW COLUMNS IN table略显鸡肋,我们主要看下对SELECT,Function的DML查询支持。
SELECT
语法结构如下:
SELECT [TOP [ count ] ] select_expr [, ...]
[ FROM table_name ]
[ WHERE condition ]
[ GROUP BY grouping_element [, ...] ]
[ HAVING condition]
[ ORDER BY expression [ ASC | DESC ] [, ...] ]
[ LIMIT [ count ] ]
[ PIVOT ( aggregation_expr FOR column IN ( value [ [ AS ] alias ] [, ...] ) ) ]
表示从0-N个表中获取行数据。SQL 的执行顺序为:
- 获取所有
FROM中的关键词,确定表名。
- 如果有
WHERE条件,过滤掉所有不符合的行。
- 如果有
GROUP BY条件,则分组聚合;如果有HAVING条件,则过滤聚合的结果。
- 上一步得到的结果经过
select_expr运算,确定具体返回的数据。
- 如果有
ORDER BY条件,会对返回的数据排序。
- 如果有
LIMIT or TOP条件,会返回上一步结果的子集。
与常用的SQL有两点不同,ES SQL 支持TOP [ count ]和PIVOT ( aggregation_expr FOR column IN ( value [ [ AS ] alias ] [, ...] ) )子句。
TOP [ count ] :如SELECT TOP 2 first_name FROM emp表示最多返回两条数据,不可与LIMIT条件共用。
PIVOT子句会对其聚合条件得到的结果进行行转列,进一步运算。这个我是没用过,不做介绍。
FUNCTION
基于上面的 SQL 我们其实已经能有过滤,聚合,排序,分页功能的 SQL 了。但是我们需要进一步了解 ES SQL 中 FUNCTION 的支持,才能写出丰富的具有全文搜索,聚合,分组功能的 SQL。 使用SHOW FUNCTIONS 可列举出支持的函数名称和所属类型。
SHOW FUNCTIONS;
name | type
-----------------+---------------
AVG |AGGREGATE
COUNT |AGGREGATE
FIRST |AGGREGATE
FIRST_VALUE |AGGREGATE
LAST |AGGREGATE
LAST_VALUE |AGGREGATE
MAX |AGGREGATE
MIN |AGGREGATE
SUM |AGGREGATE
........
我们主要看下聚合,分组,全文搜索相关的常用函数。
全文匹配函数
MATCH:相当于 DSL 中的match and multi_match查询。
MATCH(
field_exp, --字段名称
constant_exp, --字段的匹配值
[, options]) --可选项
使用举例:
SELECT author, name FROM library WHERE MATCH(author, 'frank');
author | name
---------------+-------------------
Frank Herbert |Dune
Frank Herbert |Dune Messiah
SELECT author, name, SCORE() FROM library WHERE MATCH('author^2,name^5', 'frank dune');
author | name | SCORE()
---------------+-------------------+---------------
Frank Herbert |Dune |11.443176
Frank Herbert |Dune Messiah |9.446629
QUERY:相当于 DSL 中的 query_string 查询。
QUERY(
constant_exp --匹配值表达式
[, options]) --可选项
使用举例:
SELECT author, name, page_count, SCORE() FROM library WHERE QUERY('_exists_:"author" AND page_count:>200 AND (name:/star.*/ OR name:duna~)');
author | name | page_count | SCORE()
------------------+-------------------+---------------+---------------
Frank Herbert |Dune |604 |3.7164764
Frank Herbert |Dune Messiah |331 |3.4169943
SCORE():返回输入数据和返回数据的相关度relevance. 使用举例:
SELECT SCORE(), * FROM library WHERE MATCH(name, 'dune') ORDER BY SCORE() DESC;
SCORE() | author | name | page_count | release_date
---------------+---------------+-------------------+---------------+--------------------
2.2886353 |Frank Herbert |Dune |604 |1965-06-01T00:00:00Z
1.8893257 |Frank Herbert |Dune Messiah |331 |1969-10-15T00:00:00Z
聚合函数
AVG(numeric_field) :计算数字类型的字段的平均值。
SELECT AVG(salary) AS avg FROM emp;
COUNT(expression):返回输入数据的总数,包括COUNT()时field_name对应的值为null的数据。 COUNT(ALL field_name):返回输入数据的总数,不包括field_name对应的值为null的数据。 COUNT(DISTINCT field_name):返回输入数据中field_name对应的值不为null的总数。 SUM(field_name):返回输入数据中数字字段field_name对应的值的总和。 MIN(field_name):返回输入数据中数字字段field_name对应的值的最小值。 MAX(field_name):返回输入数据中数字字段field_name对应的值的最大值。
分组函数
这里的分组函数是对应 DSL 中的bucket分组。
HISTOGRAM:语法如下:
HISTOGRAM(
numeric_exp, --数字表达式,通常是一个field_name
numeric_interval --数字的区间值
)
HISTOGRAM(
date_exp, --date/time表达式,通常是一个field_name
date_time_interval --date/time的区间值
)
如下返回每年1月1号凌晨出生的数据:
ELECT HISTOGRAM(birth_date, INTERVAL 1 YEAR) AS h, COUNT(*) AS c FROM emp GROUP BY h;
h | c
------------------------+---------------
null |10
1952-01-01T00:00:00.000Z|8
1953-01-01T00:00:00.000Z|11
1954-01-01T00:00:00.000Z|8
1955-01-01T00:00:00.000Z|4
1956-01-01T00:00:00.000Z|5
1957-01-01T00:00:00.000Z|4
1958-01-01T00:00:00.000Z|7
1959-01-01T00:00:00.000Z|9
1960-01-01T00:00:00.000Z|8
1961-01-01T00:00:00.000Z|8
1962-01-01T00:00:00.000Z|6
1963-01-01T00:00:00.000Z|7
1964-01-01T00:00:00.000Z|4
1965-01-01T00:00:00.000Z|1
ES SQL局限性
因为ES SQL和ES DSL在功能上并非完全匹配,官方文档提到的 SQL 局限性有:
大的查询可能抛ParsingException
在解析阶段,极大的查询会占用过多的内存,在这种情况下,Elasticsearch SQL引擎将中止解析并抛出错误。
nested类型字段的表示方法
SQL 中不支持nested类型的字段,只能使用
[nested_field_name].[sub_field_name]
这种形式来引用内嵌子字段。 使用举例:
SELECT dep.dep_name.keyword FROM test_emp GROUP BY languages;
nested类型字段不能用在where 和 order by 的Scalar函数上
如以下 SQL 都是错误的
SELECT * FROM test_emp WHERE LENGTH(dep.dep_name.keyword) > 5;
SELECT * FROM test_emp ORDER BY YEAR(dep.start_date);
不支持多个nested字段的同时查询
如嵌套字段nested_A和nested_B无法同时使用。
nested内层字段分页限制
当分页查询有nested字段时,分页结果可能不正确。这是因为:ES 中的分页查询发生在Root nested document上,而不是它的内层字段上。
keyword类型的字段不支持normalizer
不支持数组类型的字段
这是因为在 SQL 中一个field只对应一个值,这种情况下我们可以使用上面介绍的 SQL To DSL 的 API 转化为 DSL 语句,用 DSL 查询就好了。
聚合排序的限制
- 排序字段必须是聚合桶中的字段,ES SQL CLI突破了这种限制,但上限不能超过512行,否则在sorting阶段会抛异常。推荐搭配
Limit子句使用,如:
SELECT * FROM test GROUP BY age ORDER BY COUNT(*) LIMIT 100;
- 聚合排序的排序条件不支持Scalar函数或者简单的操作符运算。聚合后的复杂字段(比如包含聚合函数)也是不能用在排序条件上的。
以下是错误例子:
SELECT age, ROUND(AVG(salary)) AS avg FROM test GROUP BY age ORDER BY avg;
SELECT age, MAX(salary) - MIN(salary) AS diff FROM test GROUP BY age ORDER BY diff;
子查询的限制
子查询中包含GROUP BY or HAVING 或者比SELECT X FROM (SELECT ...) WHERE [simple_condition]这种结构复杂,都是可能执行不成功的。
TIME 数据类型的字段不支持GROUP BY条件和HISTOGRAM函数
如以下查询是错误的:
SELECT count(*) FROM test GROUP BY CAST(date_created AS TIME);
SELECT HISTOGRAM(CAST(birth_date AS TIME), INTERVAL '10' MINUTES) as h, COUNT(*) FROM t GROUP BY h
但是将 TIME 类型的字段包装为Scalar函数返回是支持 GROUP BY 的,如:
SELECT count(*) FROM test GROUP BY MINUTE((CAST(date_created AS TIME));
返回字段的限制 如果一个字段不在 source 中存储,是无法查询到的。keyword, date, scaled_float, geo_point, geo_shape这些类型的字段不受这种限制,因为他们不是从_source中返回,而是从docvalue_fields中返回。
以上就是W3Cschool编程狮关于查询ElasticSearch:用SQL代替DSL的相关介绍了,希望对大家有所帮助。