文章来源于公众号:架构头条 作者:John Griffin 译者 |:无明
本文作者根据自己的使用体验,详细对比了 Go 和 Java 的使用差异,给了开发者们一个中肯的选用参考。
老实说,我很喜欢 Java。我在 Spiral Scout 工作的那几年,使用了 EJB2、DB2 和 Oracle 等后端技术,积累了很多软件开发方面的专业知识。过去几年,我转向基于自然语言处理的机器人项目,涉及的技术包括 Spring Boot、Redis、RabbitMQ、Open NLP、IBM Watson 和 UIMA。一直以来,我选择的语言是 Java,它一直很高效,有时还会觉得它很有趣。
1. 初遇 Go
2017 年初,我接手了一个非常有趣的项目,一个用于监控和种植水培植物的自动化编程系统。项目的原始代码里包含了一个使用 CGo 开发的支持三个不同系统(Windows、MacOS 和 ARM)的网关。
因为对 Go 不熟悉,我一边学习,一边用它来实现功能。因为已有代码库的结构非常复杂,对我来说是难上加难。用 Go 开发的支持三种不同操作系统的程序意味着需要针对三种不同的系统进行部署、测试和运行维护。此外,代码采用了单例设计模式,导致系统严重相互依赖,难以预测会出现什么问题,而且难以理解。最后,我选择使用 Java 来实现新版本,但最终也变得非常丑陋和令人困惑。
在加入 Spiral Scout 后,我尝试停止使用 Java。我决定拥抱 Go,并尽可能多地使用 Go 来开发。我发现它是一种创新且全面的语言,我们的团队现在仍然每天在各种项目中使用它。
但是,与任何一门编程语言一样,Go 也有它的缺点,而且我不想撒谎——有时候我真的很想念 Java。
如果说我的编程经验教会了我什么,那一定是——软件开发没有银弹。我将在这篇文章里详细分享我使用一门传统语言和一门新语言的经历。
2. 简洁性
Go 和 Java 都是 C 家族语言,所以它们具有相似的语法。因此,Java 开发人员可以很容易读懂 Go 代码,反之亦然。Go 不需要在语句末尾使用分号(’;’),只有少数情况例外。对我来说,Go 的行分隔方式更清晰,更易读。
Go 和 Java 都使用了我最喜欢的功能之一,即垃圾收集器(GC),用来帮助防止内存泄漏。与 C++ 不同,C 家族的程序员需要处理内存泄漏问题。垃圾回收器是自动化内存管理的一个特性,减轻了程序员的负担。
Go 的 GC 并未使用“弱世代假设”,但它的表现仍然非常出色,并且 STW(Stop-the-World)的时间非常短。在 1.5 版中,STW 降得更多,并且很稳定,而在 1.8 版中,它降到了 1 毫秒以下。
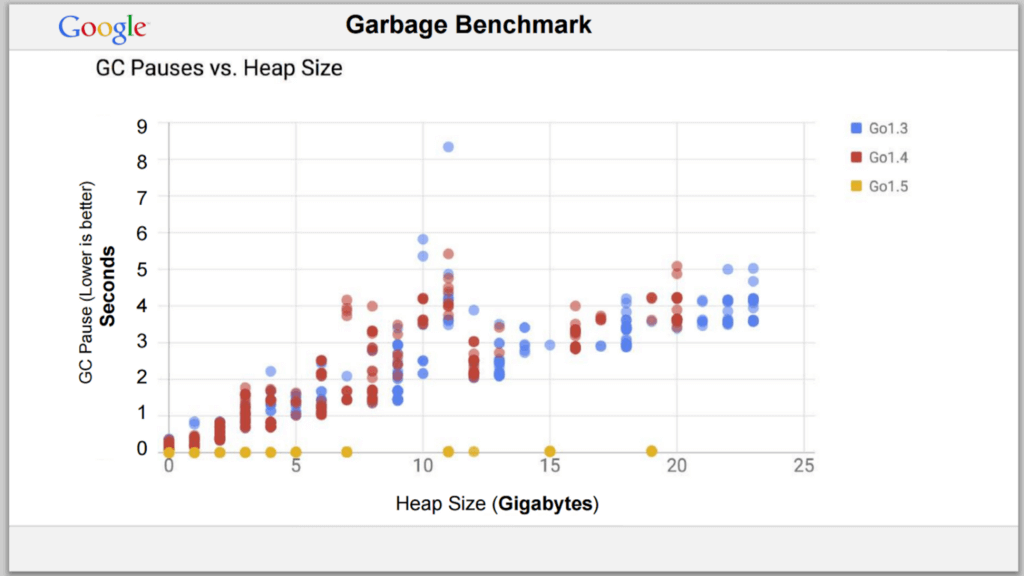
Go 的 GC 只有少量的一些选项,即用于设置初始垃圾回收目标百分比的 GOGC 变量。而 Java 有 4 个不同的垃圾回收器,每个垃圾回收器都有大量的选项。
尽管 Java 和 Go 都被认为是跨平台的,但 Java 需要 Java 虚拟机(JVM)来解释编译后的代码,而 Go 是将代码编译成目标平台的二进制文件。但我认为,与 Go 相比,Java 对平台的依赖程度更低,因为 Go 每次都需要为新平台编译二进制文件。从测试和 DevOps 的角度来看,分别为不同的平台编译二进制文件非常耗时,并且跨平台的 Go 编译在某些情况下不起作用,尤其是在使用 CGo 时。而对于 Java,你可以在安装了 JVM 的任何地方使用相同的 jar。Go 需要的 RAM 更小一些,并且不需要安装和管理虚拟机。
反射。Java 的反射更方便、更流行也更常用,而 Go 的反射似乎更复杂。Java 是一种面向对象的编程语言,因此除原始类型之外的所有东西都被视为对象。如果要使用反射,可以创建一个类,并从类中获取所需的信息,如下所示:
Class cls = obj.getClass();
Constructor constructor = cls.getConstructor();
Method[] methods = cls.getDeclaredFields();这样就可以访问构造函数、方法和属性,然后调用或对它们赋值。
Go 没有类的概念,并且结构体只包含了已声明的字段。因此,我们需要借助“reflection”包来获得所需的信息:
type Foo struct {
A int `tag1:"First Tag"
tag2:"Second Tag"`
B string
}
f := Foo{A: 10, B: "Salutations"}
fType := reflect.TypeOf(f)
switch t.Kind(fType)
case reflect.Struct:
for i := 0; i < t.NumField(); i++ {
f := t.Field(i)
// ...
}
}我觉得这不是一个大问题,但由于 Go 中没有结构体的构造函数,所以很多原始类型必须单独处理,并且需要考虑到指针。在 Go 中,我们可以进行指针传递或值传递。Go 的结构体可以将函数作为字段。所有这些都让 Go 的反射变得更加复杂。
可访问性。Java 有 private、protected 和 public 修饰符,为数据、方法和对象提供了不同的访问作用域。Go 有与 Java 的 public 和 private 相似的 exported/unexported,但没有修饰符。以大写字母开头的所有内容都将被导出,对其他包可见,未导出(小写)的变量或函数仅在当前包中可见。
3. Go 与 Java 的大不同
Go 不是面向对象编程语言。Go 没有类似 Java 的继承机制,因为它没有通过继承实现传统的多态性。实际上,它没有对象,只有结构体。它可以通过接口和让结构体实现接口来模拟一些面向对象特性。此外,你可以在结构体中嵌入结构体,但内部结构体无法访问外部结构体的数据和方法。Go 使用组合而不是继承将一些行为和数据组合在一起。
Go 是一种命令式语言,Java 是一种声明式语言。Go 没有依赖注入,我们需要显式地将所有东西包装在一起。因此,在使用 Go 时尽量少用“魔法”之类的东西。一切代码对于代码评审人员来说都应该是显而易见的。Go 程序员应该了解 Go 代码如何使用内存、文件系统和其他资源。
Java 要求开发人员更多地地关注程序的业务逻辑,知道如何创建、过滤、修改和存储数据。系统底层和数据库方面的东西都是通过配置和注解来完成的(比如通过 Spring Boot 等通用框架)。我们尽可能把枯燥乏味的东西留给框架去做。这样做很方便,但控制也反转了,限制了我们优化整个过程的能力。
变量定义的顺序。在 Java 中,你可以这样定义变量:
String name;而在 Go 中,你得这么写:
name string在我刚开始使用 Go 时,这也是令我感到困惑的一个地方。
4. Go 好的方面
简单优雅的并发。Go 具有强大的并发模型,叫作“通信顺序进程”或 CSP。Go 使用 n-to-m 分析器,允许在 n 个系统线程中执行 m 个并发。启动并发例程非常简单,只需使用 Go 的一个关键字即可,例如:
go doMyWork()这样就可以并发执行 doMyWork()。
进程之间的通信可以通过共享内存(不推荐)和通道来完成。我们可以使用与环境变量 GOMAXPROCS 定义的进程数一样多的核心,并带来非常健壮和流畅的并行性。默认情况下,进程数等于核心数。
Go 提供了一种特殊模式来运行二进制文件,并可以检测执行竟态条件。我们可以通过这种方式测试并证明自己的程序是不是并发安全的。
go run -race myapp.go应用程序将在竟态检测模式下运行。
Go 提供了很多开箱即用且非常有用的基本功能(https://golang.org/dl/),例如用于并发的“sync”包(https://golang.org/pkg/sync/)。“Once”类型的单例可以这么写:
package singleton
import ("sync")
type singleton struct { }
var instance *singleton
var once sync.Once
func GetInstance() *singleton {
once.Do(func() {
instance = &singleton{}
})
return instance
}sync 包还为并发 map 实现、互斥锁、条件变量和 WaitGroup 提供了一种结构体。atomic 包(https://golang.org/pkg/sync/atomic/) 支持并发安全转换和数学运算——它们基本上是编写并发代码所需的一切。
指针。借助指针,Go 可以更好地控制如何分配内存、垃圾回收器负载以及其他在 Java 中无法实现的性能调优。与 Java 相比,Go 更像是一种低级的语言,并且支持更容易、更快的性能优化。
鸭子类型(Duck Typing)。“如果它走路像鸭子,并且像鸭子一样嘎嘎叫,那它一定就是鸭子”。在 Go 中就是这样的:无需定义某种结构体是否实现了给定的接口,只要这个结构体具有与给定接口相同的方法签名,那它就是实现了这个接口。这非常有用,作为代码库的调用端,你可以定义外部库结构体所需的任意接口。而在 Java 中,对象必须显式声明实现了哪些接口。
性能分析器。Go 的性能分析工具让性能问题分析变得便捷和轻松。Go 的分析器可以揭示程序的内存分配和 CPU 使用情况,并在可视化图形中展示出来,让性能优化变得非常容易。Java 也有很性能分析器,比如 Java VisualVM,但它们都比 Go 的复杂,而且依赖 JVM 的运行情况,因此它们提供的统计信息与垃圾回收器的运行相关。
CGO。Go 可以与 C 语言集成,因此你可以在 Go 项目中开发带有 C 代码片段的应用程序。开发人员可以使用 CGo 创建调用 C 代码的 Go 程序包。Go 为 exclude/include 给定平台的 C 代码片段提供了各种构建选项。
将函数作为参数。Go 函数可以作为变量传递给另一个函数或作为结构体的字段。这种多功能性令人耳目一新。Java 8 引入了 lambda,但它们不是真正的函数,只是单函数对象。
清晰的代码风格准则。Go 社区提供了很多示例和说明:
https://golang.org/doc/effective_go.html
函数可以返回多个参数,这个也非常有用。
package main
import "fmt"
func returnMany() (int, string, error) {
return 1, "example", nil
}
func main() {
i, s, err := returnMany()
fmt.Printf("Returned %s %s %v", i, s, err)
}5. Go 不好的方面
没有多态性(除非通过接口来实现)。在 Go 中,如果在同一个包中有两个函数具有不同的参数但含义相同,必须给它们指定不同的名字。例如这段代码:
func makeWorkInt(number int) {
fmt.Printf(“Work done number %d”, number)
}
func makeWorkStr(title string) {
fmt.Printf(“Work done title %s”, title)
}这样一来,你就会得到很多方法,它们做的事情差不多,但名字都不一样,而且看起来很“丑”。
另外,Go 也没有继承多态性。被嵌入到结构体里的结构体只知道其自己的方法,对“宿主”结构体的方法一无所知。对于像我这样的开发人员来说,这尤其具有挑战性,因为我们是从其他 OOP 语言(最基本的概念之一就是继承)过渡到 Go 的。
不过,随着时间的推移,我开始意识到这种处理多态性的方法只是另一种思维方式,而且是有道理的,因为组合比继承更加可靠,并且运行时间是可变的。
错误处理。在 Go 中,完全由你来决定返回什么错误以及如何返回错误,因此作为开发人员,你需要负责返回和传递错误。毫无疑问的是,错误可能会被隐藏掉,这是一个痛点。时刻要记得检查错误并把它们传递出去,这有点烦人,而且不安全。
当然,你可以使用 linter 来检查隐藏的错误,但这只是一种辅助手段,不是真正的解决方案。在 Java 中,处理异常要方便得多。如果是 RuntimeException,甚至不必将其添加到函数的签名中。
public void causeNullPointerException() {
throw new NullPointerException("demo");
}
/*
...
*/
try {
causeNullPointerException();
} catch(NullPointerException e) {
System.out.println("Caught inside fun().");
throw e; // rethrowing the exception
}没有泛型。虽然泛型很方便,但它会增加复杂性,而且从类型系统和运行时方面来看,泛型的成本很高。在构建 Go 代码时,你需要处理各种不同的类型或使用代码生成。
没有注解。尽管可以用代码生成替换一部分编译时注解,但运行时注解是不能替换的。这是有道理的,因为 Go 不是声明式的,并且代码里不应该包含任何“魔法”。我喜欢在 Java 中使用注解,因为它们让代码更优雅、简单和简约。
在为 HTTP 服务器端点生成 swagger 文件时,注解会非常有用。目前在 Go 中需要手动编写 swagger 文件,或者为端点提供特别的注释。每次 API 发生改动时,这都是一件很痛苦的事情。但是,Java 中的注解就像是一种魔法一样,人们通常都不用去关心它们是怎么实现的。
Go 的依赖管理。我之前曾写过一篇关于如何使用 vgo 和 dep 在 Go 中进行依赖管理的文章。Go 的依赖管理的演变之路充满了坎坷。最初,除了“ Gopgk”之外没有其他依赖管理工具,后来发布了实验性的“Vendor”,后被“vgo”取代,然后又被 1.10 版“go mod”取代。如今,我们可以手动或者使用各种 Go 命令(例如“go get”)来修改 go.mod 文件描述符,但这也让依赖关系变得不稳定。
Java 有 Maven 和 Gradle 之类的声明式工具,用来进行依赖关系管理,也用于构建、部署和处理其他 CD/CI 任务。但是,在 Go 中,我们必须使用 Makefile、docker-composes 和 bash 脚本自定义构建所需的依赖管理,这只会使 CD/CI 的过程和稳定性变得更加复杂。
包的名称里包括了托管域名。例如:
import "github.com/pkg/errors"这真的很奇怪,而且很不方便,因为你不能在不修改项目代码库导入的情况下用自己的实现替换别人的实现。
在 Java 中,导入通常以公司名称开头,例如:
import by.spirascout.public.examples.simple.Helper;区别在于,在 Go 中,go get 会向 by.spirascout.public 获取资源。在 Java 中,包名和域名不一定是相关联的。
我希望所有与依赖管理有关的问题都是暂时的,将来会得到妥善的解决。
6. 写在最后
Go 最有趣的一个地方是它所遵循的代码命名规则——基于代码可读性心理学:
https://medium.com/@egonelbre/psychology-of-code-readability-d23b1ff1258a
你可以用各种方法写出清晰且可维护的代码,尽管 Go 是多单词的编程语言,但写出来的代码仍然很清晰。
Go Web 开发经验让我看到了 Go 的快速、强大和易于理解,它非常适用于小型服务和并发处理。对于大型复杂的系统、功能复杂的服务以及单服务器系统,Java 目前仍然是王者。
英文原文
https://dzone.com/articles/when-to-use-go-vs-java-one-programmers-take-on-two
以上就是W3Cschool编程狮关于程序员技术选型:写Go还是Java?的相关介绍了,希望对大家有所帮助。