文章转载自公众号:前端工匠(微信号:frontJS)
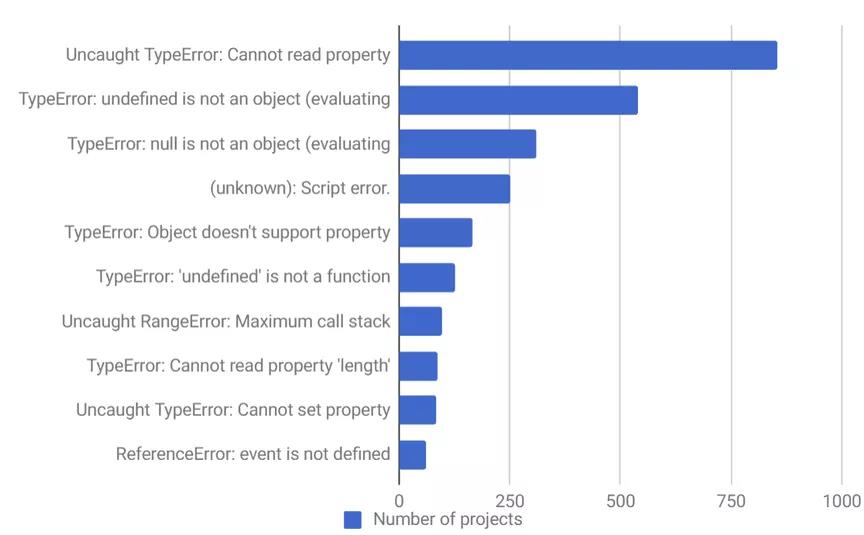
2020年注定是不平凡的一年,找工作的竞争压力可想而知,如何从众多面试者中脱颖而出呢,总结了一波前端常见面试题,希望对大家有所帮助!
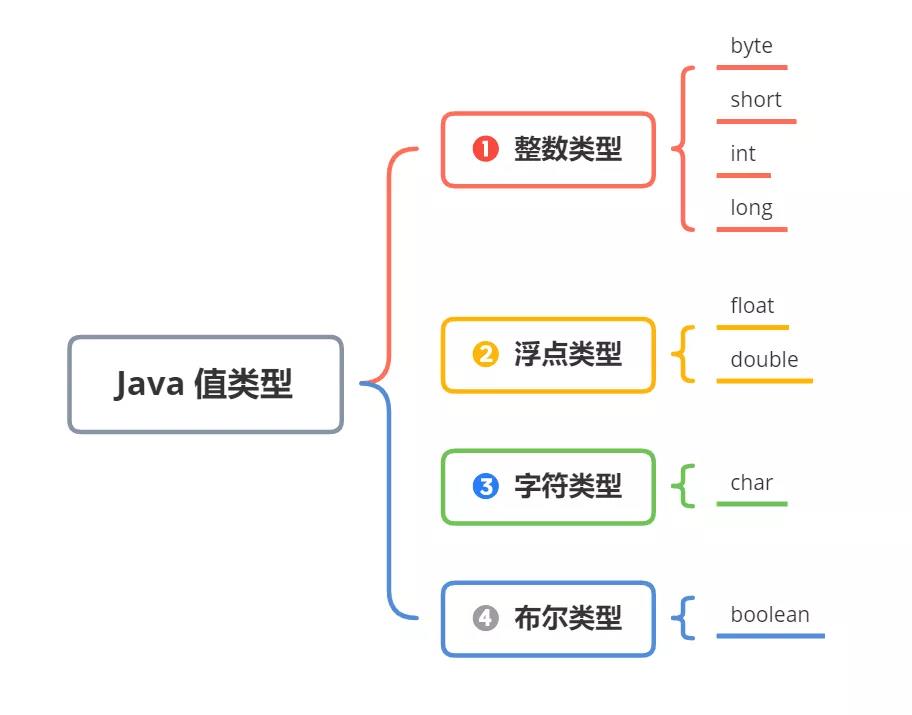
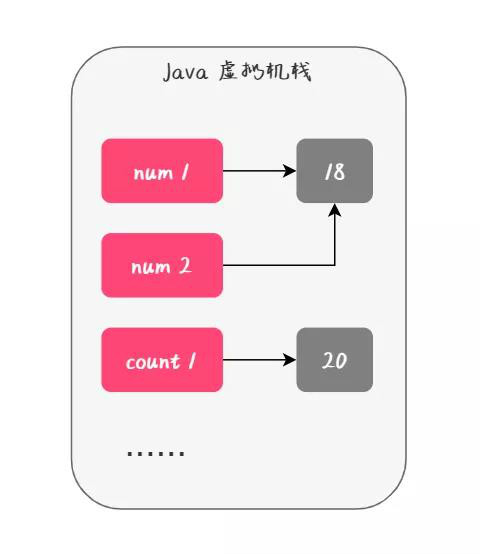
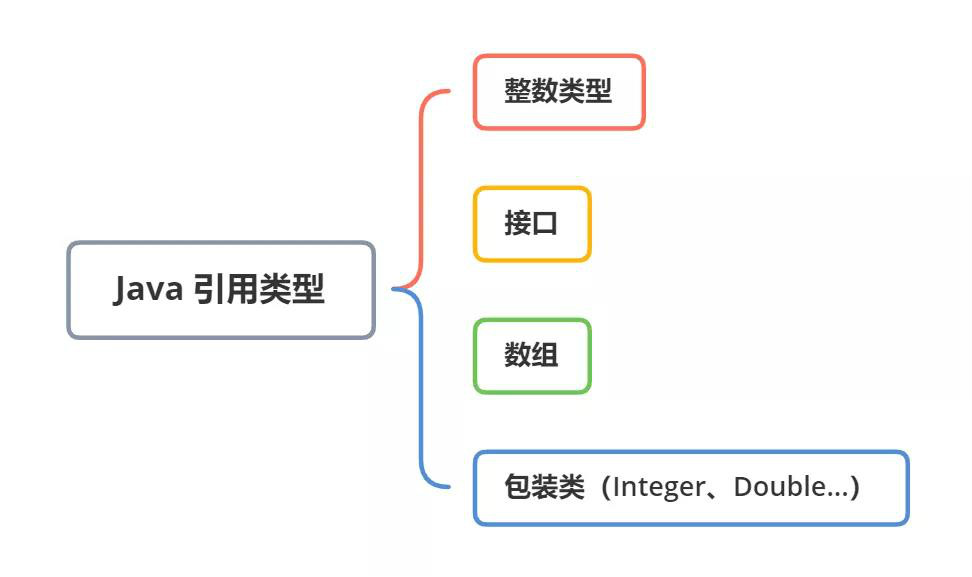
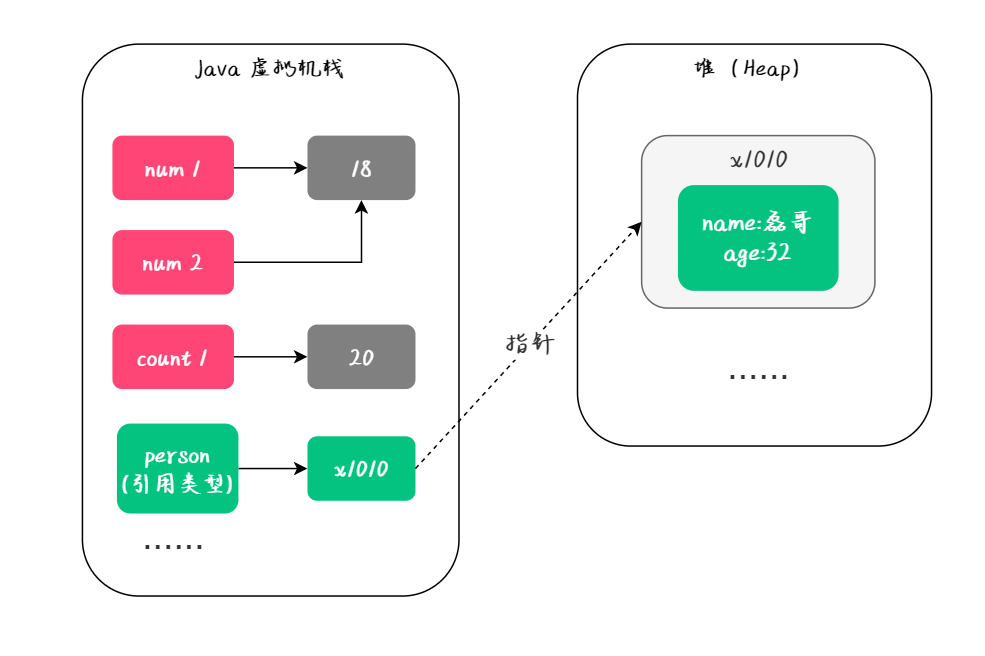
1. javascript 作用域与预解析
什么是预解析?
分两步执行:
第一步:(代码还没有执行。预览页面之前,写完之后)
找程序中var关键字,如果找到了提前给var定义的变量赋值undefined
找程序中的普通函数,如果找到了,函数提升,将整个函数赋值给函数名。
如果找的var的名字和函数名字相同,函数优先。
第二步: 逐行解析代码。按照上下顺序。如果碰到函数定义,忽略。
重点:函数内部同样适用于js预解析。
我们通过几道面试题,来了解下作用域和和预解析的原理
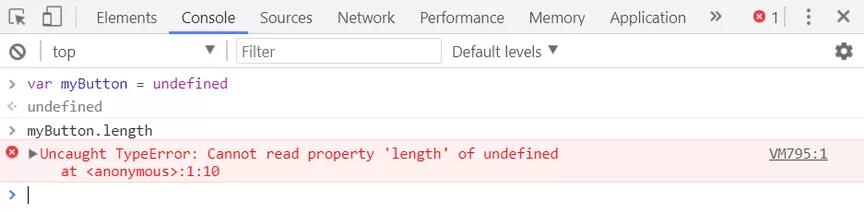
function fun(){ console.log(n); var n = 456; console.log(n); } var n = 123; fun(n);
猜一猜此题中输出的结果是?可能并不是你想的结果,why?
代码分析如下:
1-5行定义函数fun
6行定义变量 n
7行执行函数并传入变量 n
注意:fun函数内部有预解析。
预解析及执行步骤:
Fun函数开始执行前,将var n提前执行,初始化为undefined。
- 由于函数传入参数 n 并没有使用,忽略。
- 开始执行第2行,输出为
undefined。
- 执行第3行,此时即n = 456,即将n值重置为456。
- 执行第4行,输出改变后的n。
通过以上步骤分析,即可得知预解析的原理了(针对有var的变量提前赋初始值)
下面再看一题,看看函数预解析
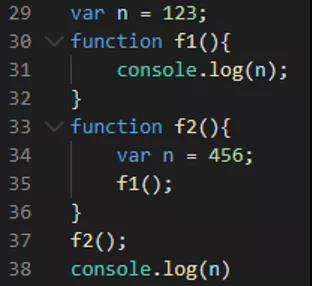
猜一猜此题中输出的结果是?可能并不是你想的结果,why?
代码分析如下:
29行定义一个全局变量
30-32行定义一个函数 f1
33-36行定义一个函数 f2
37行执行函数 f2
38行输出结果 n
预解析及执行步骤:
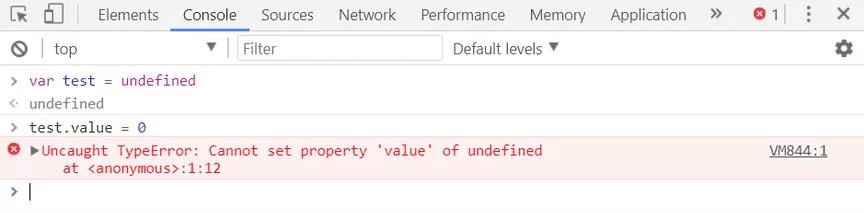
1.代码执行前,预解析先初始化变量 n, f1, f2,将它们都置为 undefined.
2.接着执行第29行,为变量n赋值
3.接着执行第30-32行,为函数变量 f1 赋值,即 f1 为函数了
4.接着执行第33-36行,为函数变量 f2 赋值
5.执行第37行,即执行 f2 函数。
- f2 函数执行前,同样预解析,先将 n 初始化为
undefined,接着把 n 赋值为456,接着调用f1函数执行。
- f1 在 f2 中执行,那 f1 的作用域应该是 f2 ,应该输出456?
8.35行执行 f1 函数时无调用者,即 f1 函数为全局作用域,输出全局 n 为 123
9.第38行直接输出全局变量 n ,即123
继续深入,再来一题:
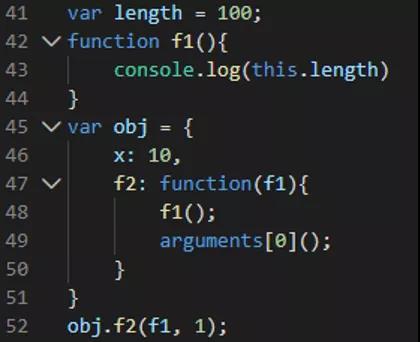
猜一猜此题中输出的结果是?可能并不是你想的结果,why?
代码分析如下:
预解析只针对var和function定义的变量
预解析及执行步骤:
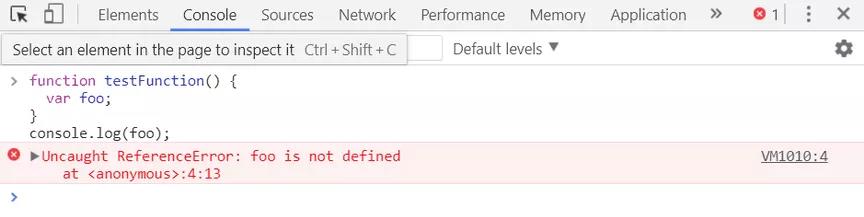
1.预解析先初始化变量length, obj, f1并赋值为undefined
2.接着为变量length赋值为 100
3.接着为函数变量 f1 赋值为函数
4.接着为变量`obj 赋值为对象
5.第52行,调用对象obj的 f2 函数执行,传入形参 f1 和1
6.第47行,f2 函数接收实参为 f1 , 接着执行 f1 函数
7.同上,f1 函数执行无调用者,作用域为全局,this指向window,输出全局变量length,即100
8.第47行,f2 函数接收实参 f1 ,若要取到所有实参则需要arguments对象,第一个参数arguments[0]==f1,第二个arguments[1]==1,依此类推。
9.第49行,arguments[0]()看上去是f1(),那也应该输出100?
10.注意arguments[0]作用域与f1的作用域并不相同,第48行直接执行f1,无调用者,作用域为全局作用域,但arguments[0]作用域为arguments对象,即this为arguments,则应输出 2,因为arguments对象的属性length为2。
2. 前端如何处理跨域
1、为什么会出现跨域问题
同源策略(Sameoriginpolicy)是一种约定,它是浏览器最核心也最基本的安全功能,如果缺少了同源策略,则浏览器的正常功能可能都会受到影响。可以说 Web 是构建在同源策略基础之上的,浏览器只是针对同源策略的一种实现。同源策略会阻止一个域的 javascript 脚本和另外一个域的内容进行交互。所谓同源(即指在同一个域)就是两个页面具有相同的协议(protocol),主机(host)和端口号(port)。
2、什么是跨域
当一个请求url的协议、域名、端口三者之间任意一个与当前页面url不同即为跨域。
| 当前页面url | 被请求页面url | 是否跨域 | 原因 |
|---|---|---|---|
| http://www.w3cschool.cn/ | http://www.w3cschool.cn/index.html | 否 | 同源 |
| http://www.w3cschool.cn/ | https://www.w3cschool.cn/index.html | 跨域 | 协议不同(http/https |
| http://www.w3cschool.cn | http://www.baidu.cn/ | 跨域 | 主域名不同(w3cschool/baidu |
| http://www.w3cschool.cn/ | http://123.w3cschool.cn | 跨域 | 子域名不同(www/123 |
| www.test.com:8080/ | www.test.com:7001 | 跨域 | 端口号不同 |
3、跨域解决方法
【1】设置document.domain解决无法读取非同源网页的 Cookie问题
【2】跨文档通信 API:window.postMessage()
【3】JSONP
【4】CORS
【5】Proxy
作为开发人员,最关心的跨域一般是2种交互的跨域,即Proxy和CORS,很多开发只图一时方便,使用了Proxy,在打包后就发现又有跨域了,不知道怎么解决,下面我们通过实例一点点给大家解析。
跨域出现
首先,需要重现跨域,先用node写一个简单的接口,如下

使用命令node启动这个服务,则搭建了一个最简单的后端服务接口,然后使用前端ajax来请求这个接口,如下
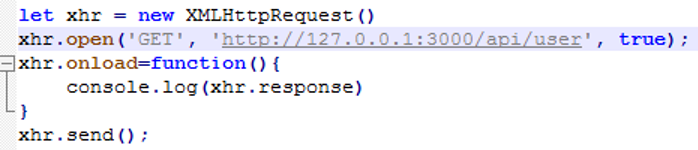
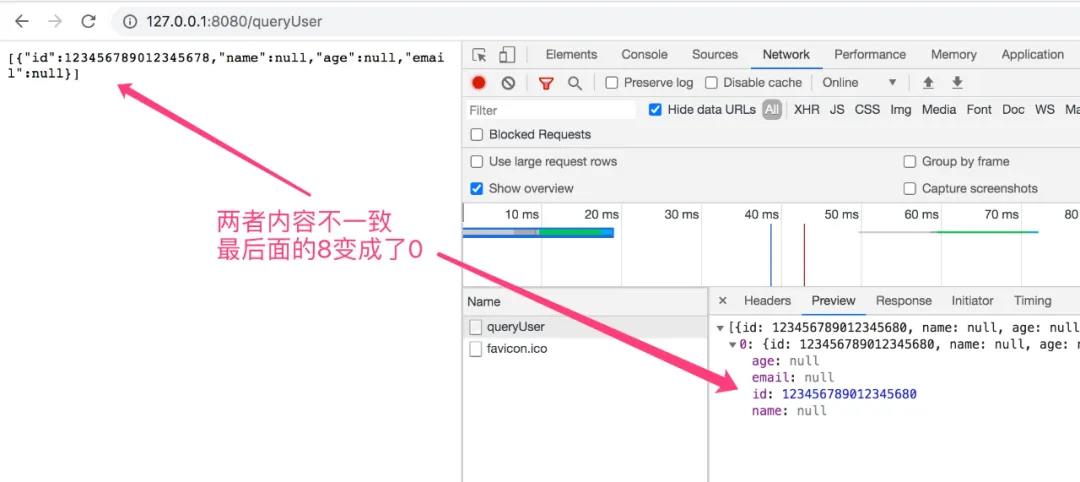
创建一个简单的html页面,再加上上面的简单ajax请求,在浏览器控制台就看到了跨域error了
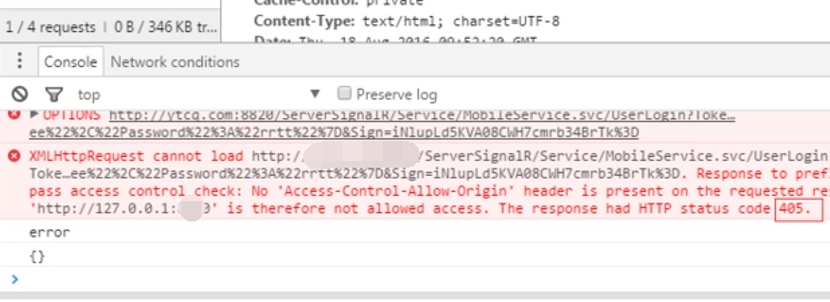
从日志上看出现了“Access-Control-Allow-Origin”,表示是访问源未被许可,即跨域了。
跨域解决之Proxy
现在项目一般都使用脚手架,即使用webpack,那可以使用webpack自带的proxy特性来处理跨域,下面我们来配置一个简单的webpack项目,如下
1.创建配置文件webpack.config.js
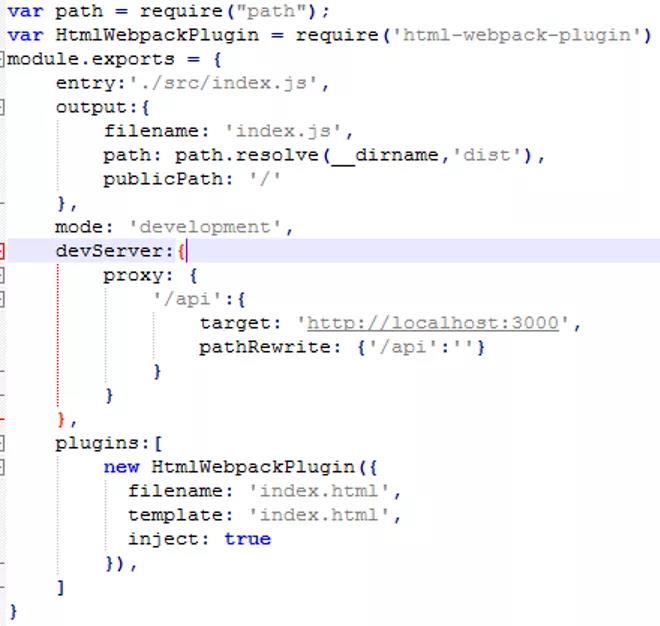
配置文件说明项目入口文件在src中index.js,打包输出目录为dist,使用proxy处理跨域,即前端所有请求会自动跳转到target指定的url
注意这里有一个前缀,若没有可以不写。
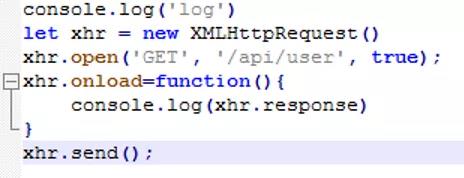
2.创建src目录及index.js
3.创建工程依赖文件package.json
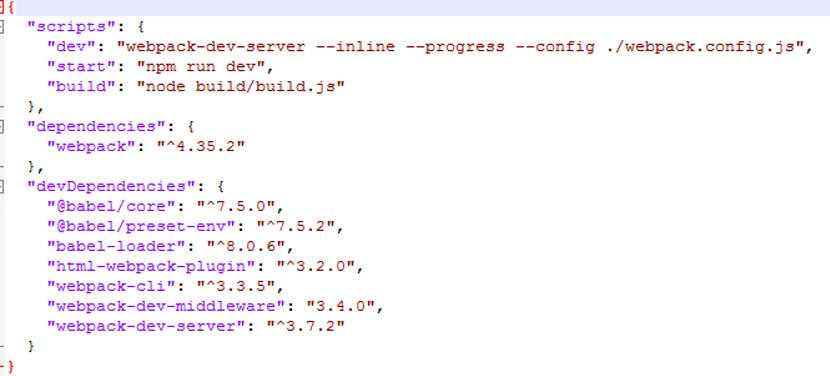
依赖文件中配置了webpack启动命令
Npm run dev 启动服务
Npm run start 启动服务
Npm run build 打包命令
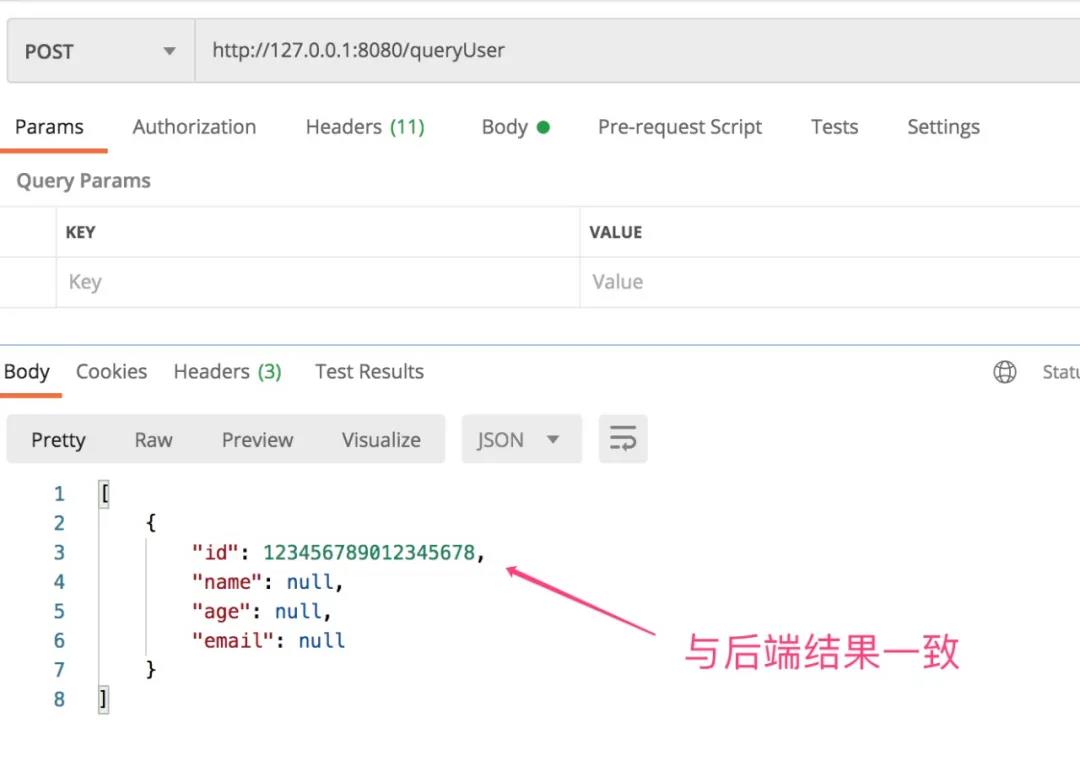
当启动服务后,打开浏览器输入 http://localhost:8080 ,即可看到一个空白页面,打开控制台可以看到ajax请求
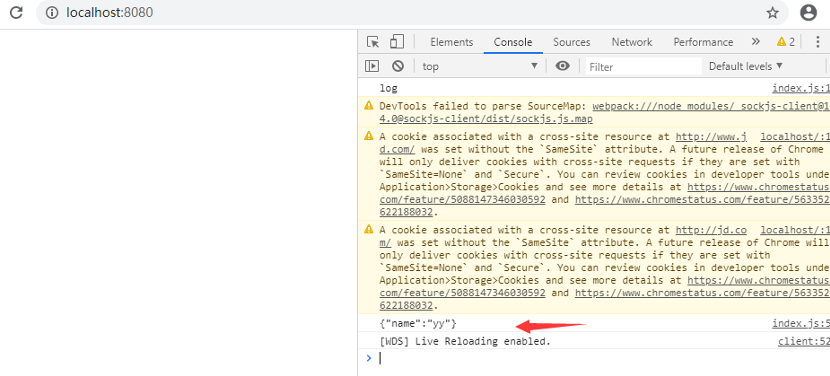
拿到交互的数据了。
这种方式是开发最常用的,但是打包后就有问题了,因为打包后就不存在proxy了,跨域还是会存在,那应该怎么解决?
跨域解决之CORS
这种方式是在后端配置,配置CORS后,前端无需任何处理即可访问后端的接口,无论是在开发时还是部署时都是OK的。
下面,我们把proxy注释掉,使用CORS方式处理,如下:
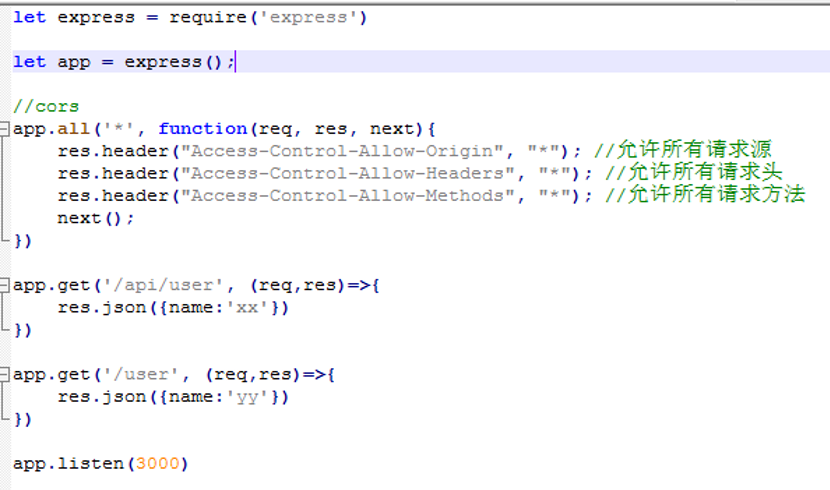
配置了cors后,接口就可以随便访问了。
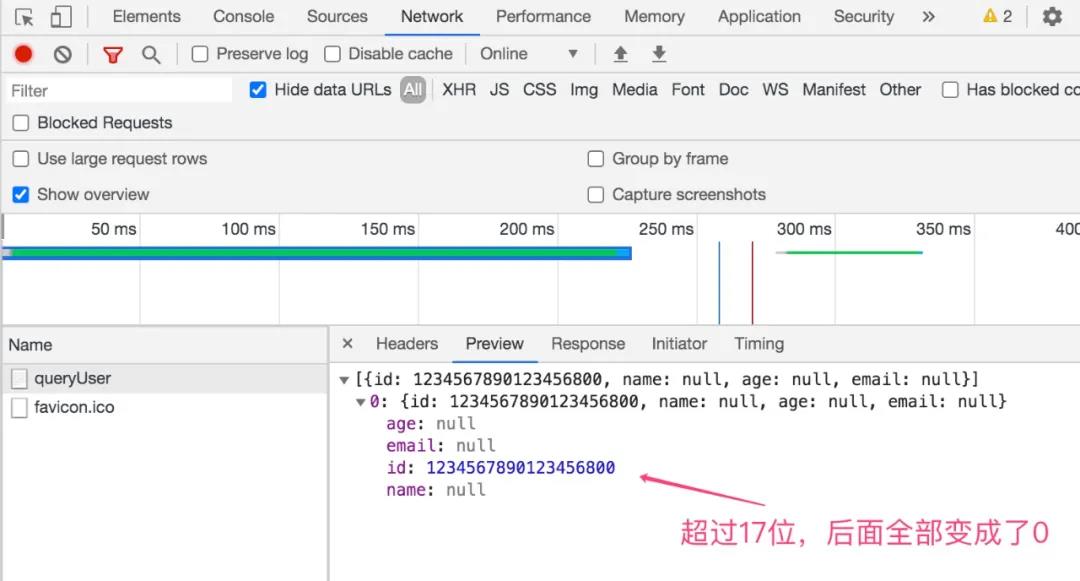
此时,还需要把前端请求地址改一下,改为直接请求后端接口,如下
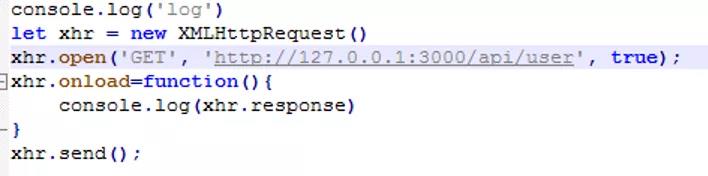
刷新页面,打开控制台可以看到请求地址为
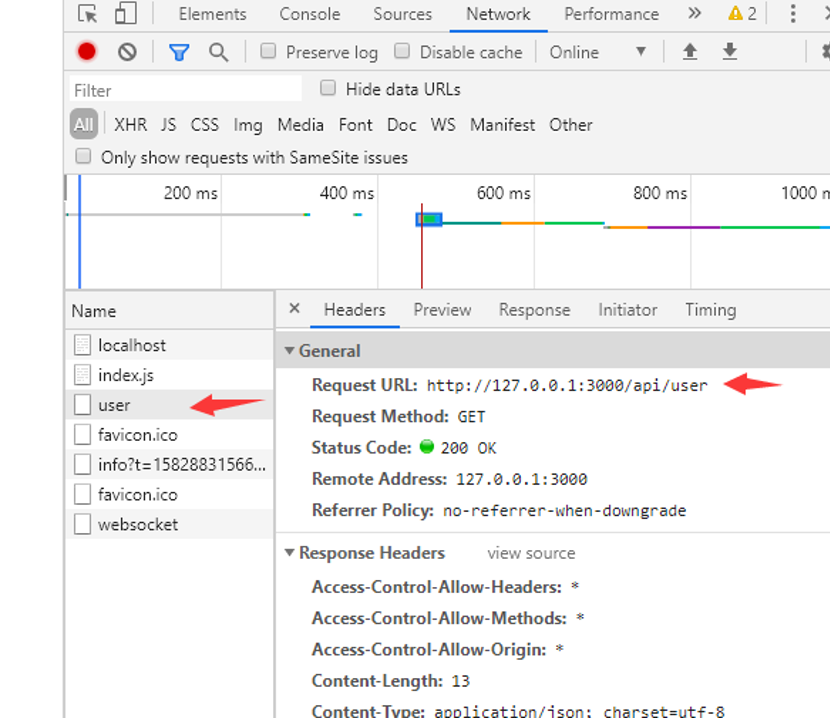
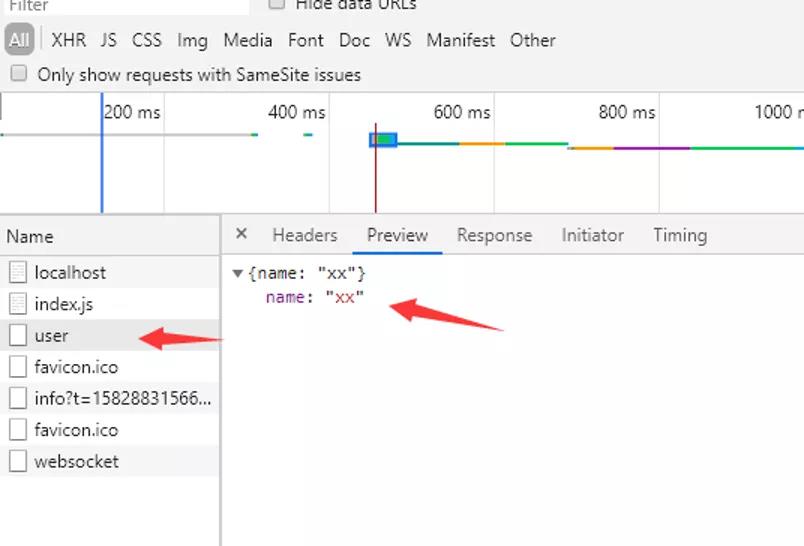
通过此种方式,在开发阶段或部署都没有问题,这也是开发中最常用的2种方式。
3. 什么是闭包?如何理解
闭包(closure)是javascript的一大难点,也是它的特色。很多高级应用都要依靠闭包来实现。
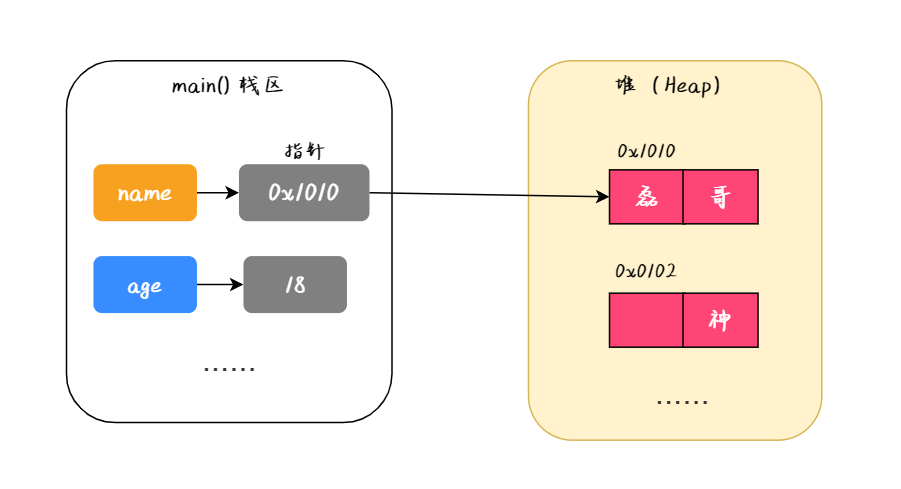
要理解闭包,首先要理解javascript的全局变量和局部变量。
javascript语言的特别之处就在于:函数内部可以直接读取全局变量,但是在函数外部无法读取函数内部的局部变量。
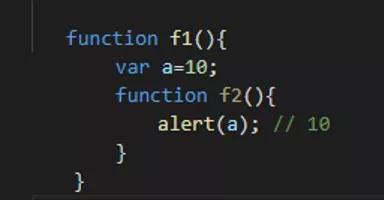
如何从外部读取函数内部的局部变量?
我们有时候需要获取到函数内部的局部变量,正常情况下,这是办不到的!只有通过变通的方法才能实现。那就是在函数内部,再定义一个函数。
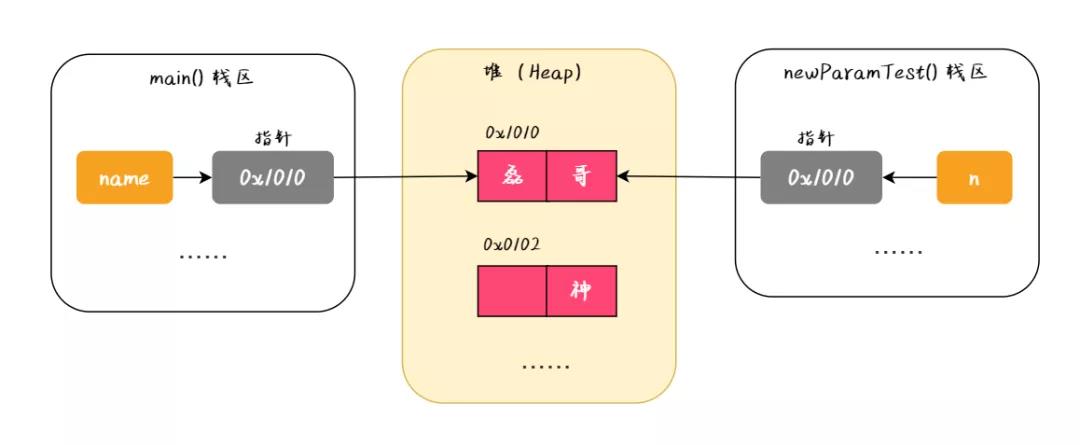
1、闭包的概念
上面代码中的 f2 函数,就是闭包。
各种专业文献的闭包定义都非常抽象,我的理解是: 闭包就是能够读取其他函数内部变量的函数。
由于在javascript中,只有函数内部的子函数才能读取局部变量,所以说,闭包可以简单理解成“定义在一个函数内部的函数“。
所以,在本质上,闭包是将函数内部和函数外部连接起来的桥梁。
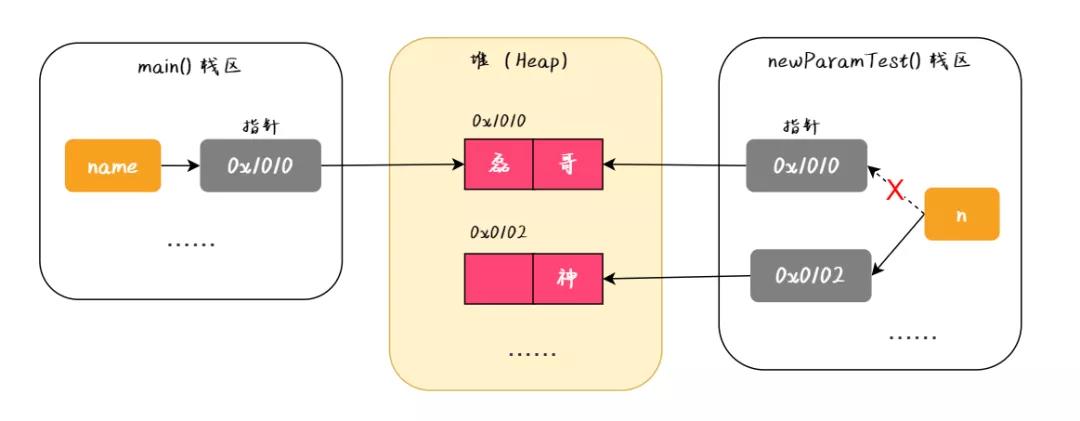
2、闭包的用途
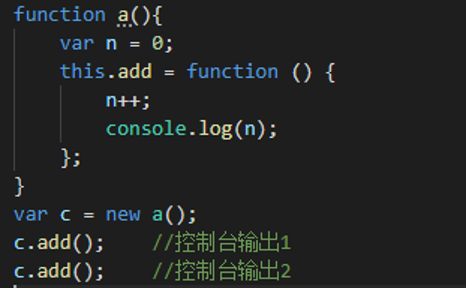
闭包可以用在许多地方。它的最大用处有两个,一个是前面提到的可以读取函数内部的变量,另一个就是让这些变量的值始终保持在内存中,不会在 f1 调用后被自动清除。
为什么会这样呢?原因就在于 f1 是 f2 的父函数,而 f2 被赋给了一个全局变量,这导致 f2 始终在内存中,而 f2 的存在依赖于 f1 ,因此 f1 也始终在内存中,不会在调用结束后,被垃圾回收机制(garbage collection)回收。
在我们平时的代码中经常会用到闭包,比如在构造函数中
//另一种写法
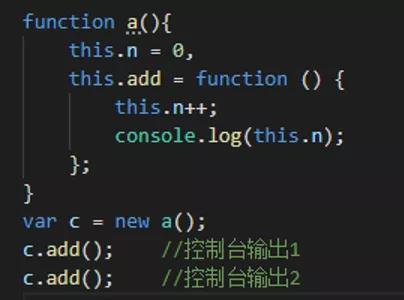
3、常见闭包的写法

另一种调用方法
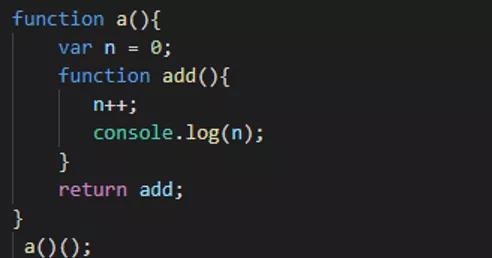
//定义函数并立即调用
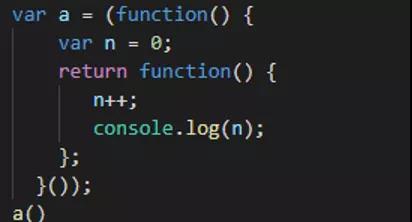
4、闭包的实际应用
使用闭包,我们可以做很多事情。比如模拟面向对象的代码风格;更优雅,更简洁的表达出代码;在某些方面提升代码的执行效率。
封装
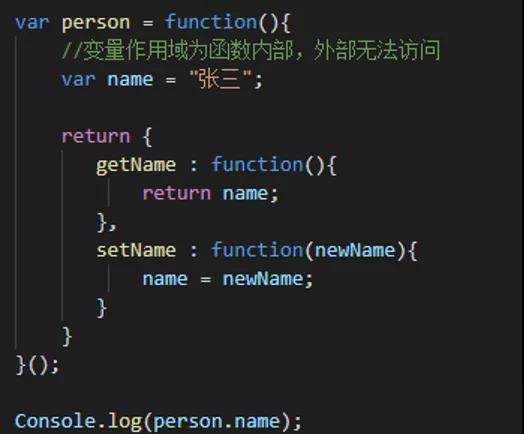
通过person.name是无法获取到name的值,如果要获取到name的值可以通过
Console.log(person.getName()); //直接获取到 张三 person.setName(“李四”); //重新设置新的名字 print(person.getName()); //获取 李四
继承
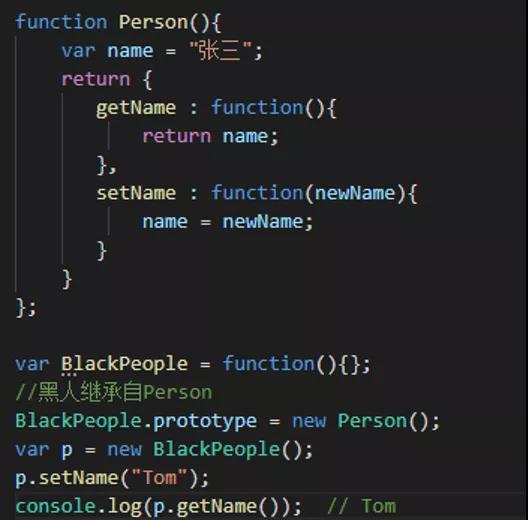
总结:闭包就是一个函数引用另外一个函数的变量,因为变量被引用着所以不会被回收,因此可以用来封装一个私有变量。这是优点也是缺点,不必要的闭包只会徒增内存消耗!
以上就是W3Cschool编程狮关于2020前端面试都会问啥?的相关介绍了,希望对大家有所帮助。