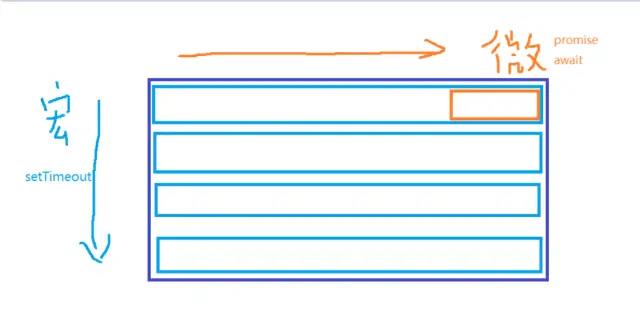
本文给大家分享一个强大的组件Nacos,它是微服务环境下必须要用到的组件。用了Nacos后,再也不用担心服务注册和发现以及配置管理混乱的问题了。
背景
Nacos 致力于帮助开发人员发现、配置和管理微服务,Nacos 提供了一组简单易用的特性集,快速实现动态服务发现、服务配置、服务元数据及流量管理。
目前主流的互联网服务都是基于微服务架构的,那服务与服务之间的交互是必不可少的,而且各个服务的上下线都是相互独立的,而且服务的配置信息也是会动态调整的,这就需要我们的服务更加灵活。Nacos 的出现就是帮助我们实现这些繁琐的功能。
详细的 Nacos 介绍和部署可以参考官方网站 Nacos.io。这里只介绍一下在 SpringBoot 项目中如何快速接入以及接入和使用过程中可能会遇到的坑。
接入
加入依赖
- 第一步在
pom配置文件中加入下面的依赖,用于实现服务注册发现和配置中心功能。
<!-- nacos 配置中心 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId></dependency>
<!-- nacos 注册发现 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId></dependency>增加配置
- 第二步在
SpringBoot项目的启动类上增加如下注解@EnableDiscoveryClient用于启动服务注册发现功能。
- 增加配置文件,对应的配置信息需要修改成适合自己的,为了方便管理,应用的分组名称,命名空间以及相关的配置都需要合理的设置。多个业务使用同一个
nacos集群的时候,需要根据各个的业务设定各自的命名空间。所有的配置文件都需要在对应的命名空间下设置,避免多个业务混用,另外业务需要根据用到的组件或者配置,设定独立的配置文件,例如数据库的配置,Redis的配置等都需要单独设定,这样是为了同一个应用其他的其他服务也可以使用,而且再有地址变更的时候可以只修改一个文件就好,不会忘记。
# 应用服务名称
spring.application.name=application-name
# 应用分组名称
spring.cloud.nacos.config.group=GROUP-NAME
# 配置文件的后缀名
spring.cloud.nacos.config.file-extension=properties
# nacos 对应的命名空间,在后台创建好命名空间后会自动生成
spring.cloud.nacos.config.namespace=xxxxxxxxxxxxxxxxxxxxxxxxx
# 对应的配置文件
# MySQL 相关配置
spring.cloud.nacos.config.ext-config[0].data-id=mysql.properties
spring.cloud.nacos.config.ext-config[0].group=GROUP-NAME
# Redis 相关配置
spring.cloud.nacos.config.ext-config[1].data-id=redis.properties
spring.cloud.nacos.config.ext-config[1].group=GROUP-NAME
# 其他配置等
spring.cloud.nacos.config.ext-config[2].data-id=other.properties
spring.cloud.nacos.config.ext-config[2].group=GROUP-NAME
# 配置中心地址,多个逗号分隔
spring.cloud.nacos.config.server-addr=xxx.xx.xx.xx:xxxx
# 服务注册发现地址,多个逗号分隔
spring.cloud.nacos.discovery.server-addr=xxx.xx.xx.xx:xxxx
# 集群名称
spring.cloud.nacos.discovery.cluster-name=CLUSTER-NAME- 代码中可以使用注解
@Value()来直接读取 Nacos 配置中的属性参数,也可以使用@ConfigurationProperties(prefix = "spring.datasource")读取批量参数。
spring.cloud.nacos.config.ext-config[0].refresh=true该参数表示是否开启自动更新,根据是否需要自动更新觉得是否配置,如果需要自动更新,加上这个配置后还需要在需要自动更新配置的 Bean 上面增加@RefreshScop注解。然后对应的 Bean 内部的属性就可以实现自动更新了。增加了spring.cloud.nacos.config.ext-config[0].refresh=true配置后在修改了 Nacos 中的配置过后日志会出现下面信息,会重新加载配置,并且输出变更的 key 信息。

服务调用
当所有的服务都接入 Nacos 过后,我们在 Nacos 的后台就可以看到每个服务的情况,如下图,可以看到服务状态。
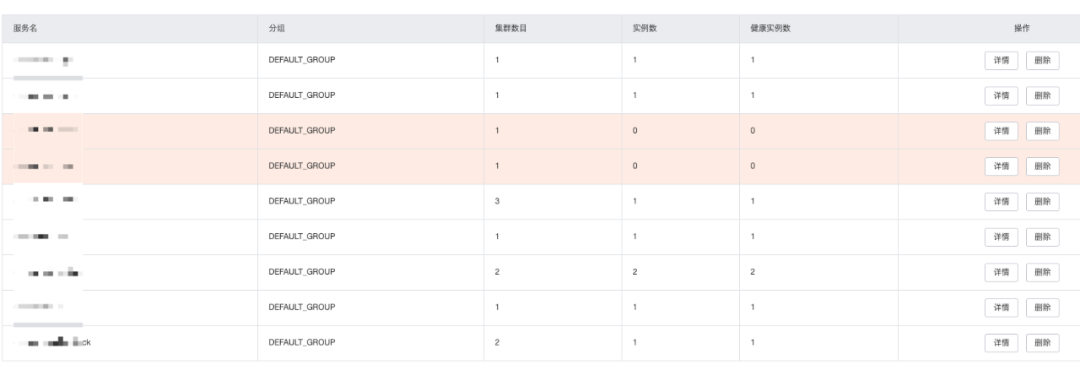
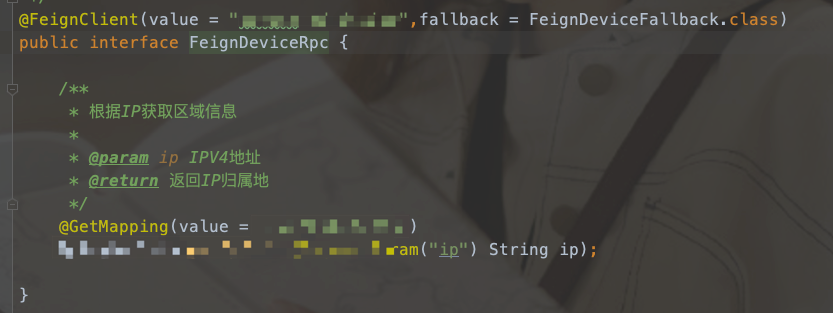
然后我们在服务 A 里面如果要调用服务 B 的时候,就可以直接在 FeginClient 中配置服务 B 的名称,不需要填写 URL 了。这样我们就不用考虑服务 B 是否地址和端口会不会变。服务 B 的实例增加还是减少,端口是否变了,对服务 A 来说都不关心,只要有个服务名称就可以了。
避坑
命名空间
Nacos 有一个默认的名为 public 的命名空间,这个命名空间是无法删除的,所有未指定命名空间的配置都会放在该命名空间下;同样的 Nacos 有一个默认的名为 DEFAULT_GROUP 的分组,在没有指定分组名称的时候默认的配置都是在该分组下。
对于我们应用程序来说,由于很多情况下一个 Nacos 集群是多个团队共同使用的,所以为了方便管理,我们需要根据自己的业务设置自己的命名空间,用于存放本业务的配置文件。本命名空间下的配置文件,根据各个的模块决定是否需要重新分组。
要知道在没有清晰的命名空间划分的时候,要想修改一个配置的内容,是很难受的一件事情。线上的配置调整,一个不小心就是事故。如果还是自动更新配置的话,那连后悔的机会都没有。
精细配置
配置文件应该专一,一个配置文件就设置一个内容,比如 MySQL 的数据源单独一个配置,Redis 的数据源单独一个配置,如果多个 Redis 服务,根据功能建议分开配置,因为并不是所有的服务都需要每个 Redis 的链接配置。各自的服务根据需要单独引用对应的配置文件即可。
将所有的配置独立成一个配置文件方便后续修改配置,只要修改一个配置文件就好,不用担心其他还有未修改的地方。
合理的规划配置文件的内容,往往很多时候可以事半功倍,极大的节约时间和减少出错的概率。
自动刷新
前面介绍了如何设置配置自动刷新,不过服务是否需要自动更新配置,这个根据自身的业务去决定。
我这里一般不建议设置自动更新,因为现在都是微服务部署,有时候我们上线一个新功能的时候都是灰度发布,如果配置自动更新,再调整配置过后,全部实例都会生效,这样会有风险。不设置自动更新的话,我们可以单独重启个别实例,观察线上情况,等稳定了再发布所有服务,这样会安全很多。
当然对于没有那么多服务,不需要灰度,影响不大的场景下,配置自动更新会方便很多,再修改配置后不需要重启服务。
(推荐教程:Spring Boot 那些事)
总结
Nacos 作为服务的注册发现和配置的统一管理确实十分出色,除了能快速接入 SpringBoot 项目之外,其他的框架都能快速的接入,更多使用可以参考官网。
文章来源:公众号–Java极客技术
以上就是W3Cschool编程狮关于你应该知道的 Nacos 接入和避坑指南的相关介绍了,希望对大家有所帮助。