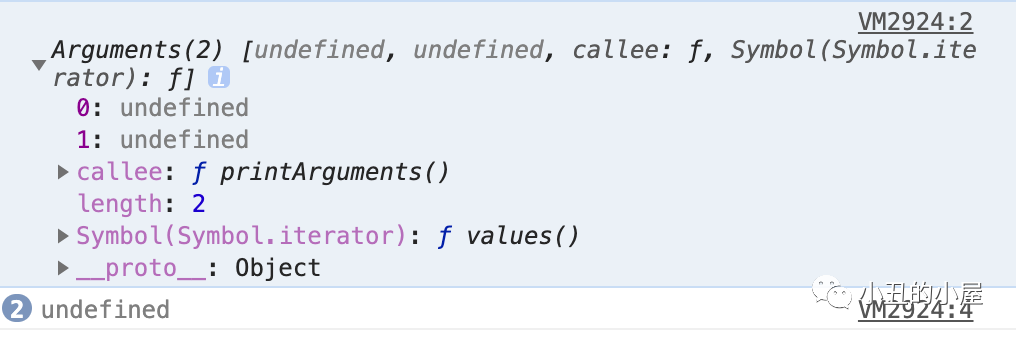
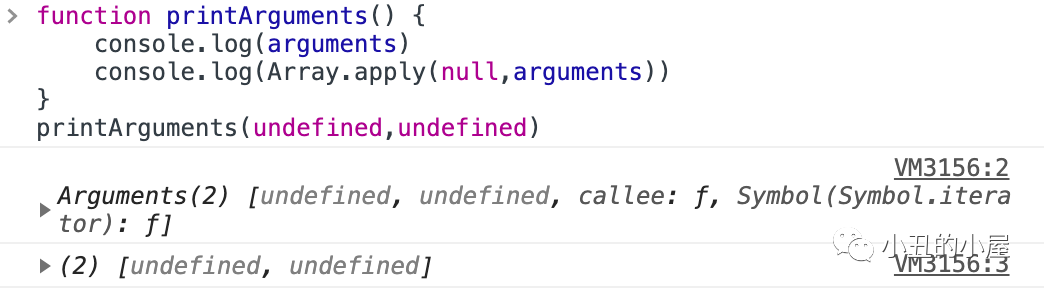
作为一名程序员,你面试的时候肯定被问过HashMap这个知识点,它的基本实现原理是每个面试者都该掌握的,当我们熟练的掌握了HashMap 的内部实现原理。面对面试官的询问,就能应答自如,接下来小编将带大家了解 JDK7 版本的 HashMap基础及其实现原理。
一、 HashMap介绍
HashMap简介: HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。 HashMap 继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口。 HashMap 的实现不是同步的,这意味着它不是线程安全的。它的key、value都可以为null。此外,HashMap中的映射不是有序的。 HashMap 的实例有两个参数影响其性能:“初始容量” 和 “加载因子”。容量 是哈希表中桶的数量,初始容量 只是哈希表在创建时的容量。加载因子 是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行rehash操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数。 通常,默认加载因子是 0.75, 这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查询成本(在大多数 HashMap 类的操作中,包括 get 和 put 操作,都反映了这一点)。在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少 rehash 操作次数。如果初始容量大于最大条目数除以加载因子,则不会发生 rehash 操作。
HashMap的继承关系:

HashMap与Map关系如下图:

HashMap的构造函数
HashMap共有4个构造函数,如下:
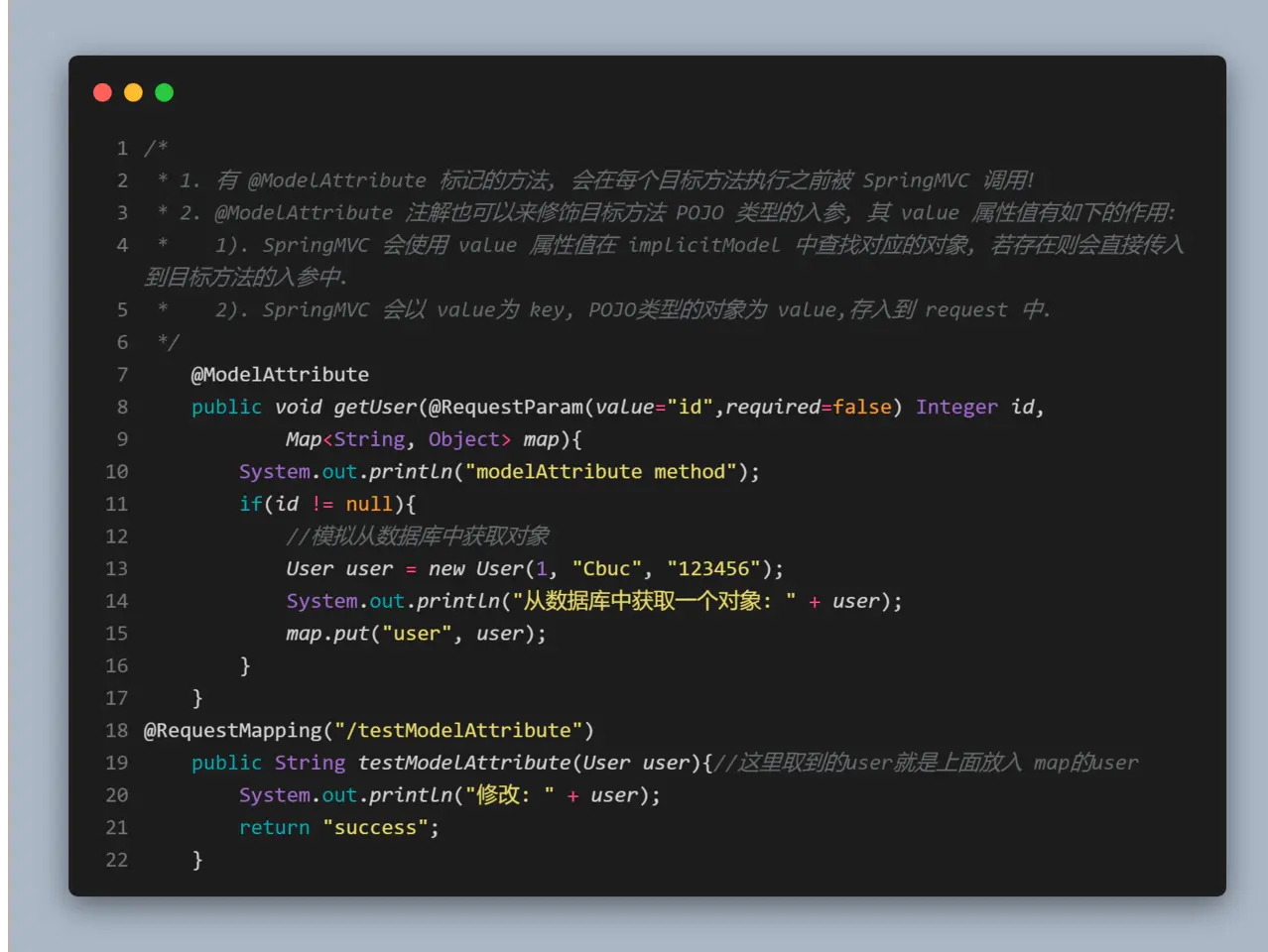
// 默认构造函数。
HashMap()
// 指定“容量大小”的构造函数
HashMap(int capacity)
// 指定“容量大小”和“加载因子”的构造函数
HashMap(int capacity, float loadFactor)
// 包含“子Map”的构造函数
HashMap(Map<? extends K, ? extends V> map)二、JDK7 中 HashMap 底层原理
HashMap 在 JDK7 或者 JDK8 中采用的基本存储结构都是数组+链表形式。本节主要是研究 HashMap 在 JDK7 中的底层实现,其基本结构图如下所示:
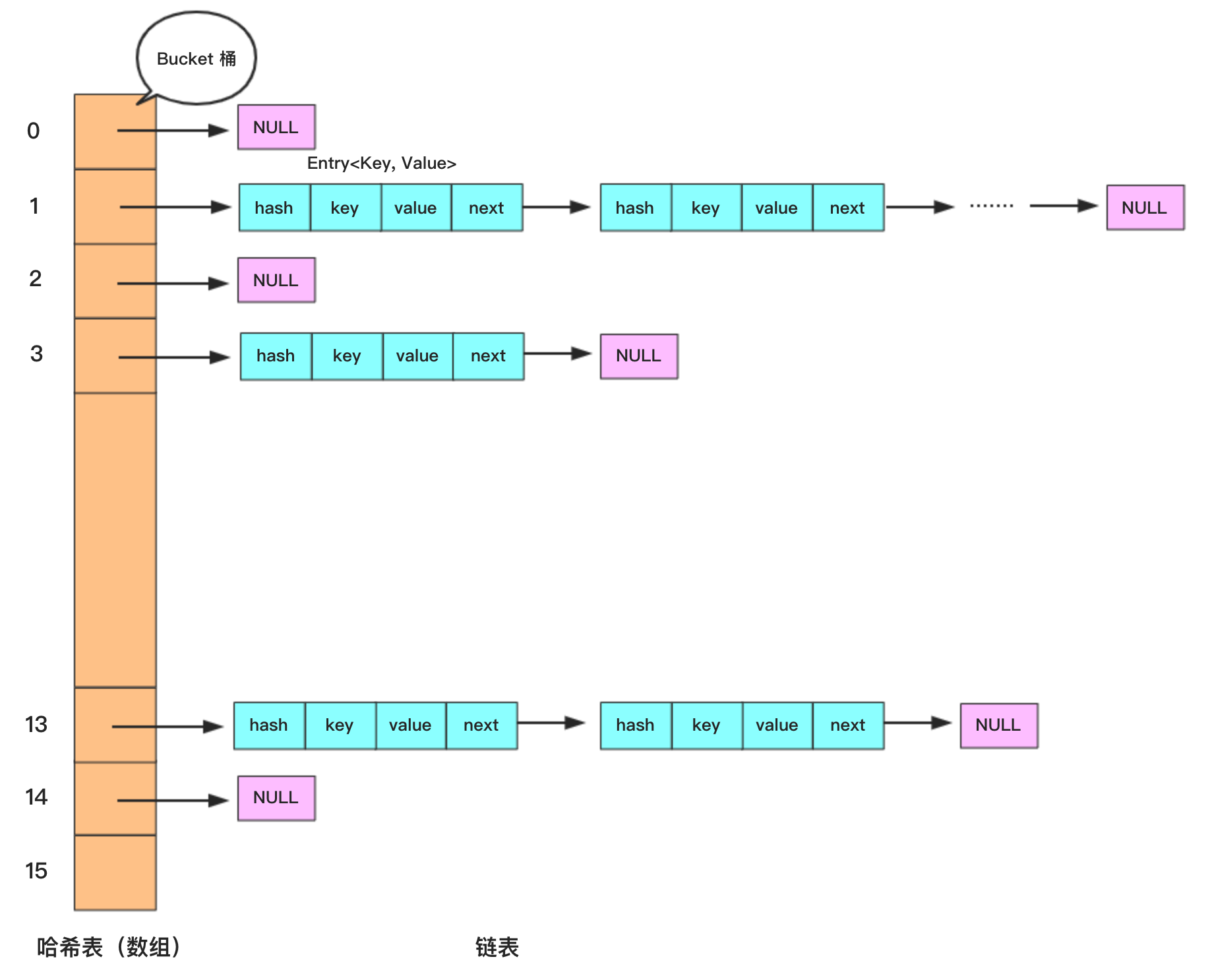
上图中左边橙色区域是哈希表,右边蓝色区域为链表,链表中的元素类型为 Entry,它包含四个属性分别是:
- K key
- V value
- int hash
- Entry next
那么为什么会出现数组+链表形式的存储结构呢?这里简单地阐述一下,后续将以源码的形式详细介绍。 我们在使用 HashMap.put("Key", "Value")方法存储数据的时候,底层实际是将key 和 value 以 Entry的形式存储到哈希表中,哈希表是一个数组,那么它是如何将一个 Entry 对象存储到数组中呢?是如何确定当前 key 和 value 组成的 Entry 该存到数组的哪个位置上,换句话说是如何确定 Entry 对象在数组中的索引的呢?通常情况下,我们在确定数组的时候,都是在数组中挨个存储数据,直到数组全满,然后考虑数组的扩容,而 HashMap 并不是这么操作的。在 Java 及大多数面向对象的编程语言中,每个对象都有一个整型变量 hashcode,这个 hashcode 是一个很重要的标识,它标识着不同的对象,有了这个 hashcode,那么就很容易确定 Entry 对象的下标索引了,在 Java 语言中,可以理解 hashcode 转化为数组下标是按照数组长度取模运算的,基本公式如下所示:
int index = HashCode(key) % Array.length 实际上,在 JDK 中哈希函数并没有直接采取取模运算,而是利用了位运算的方式来提高性能,在这里我们理解为简单的取模运算。 我们知道了对 Key 进行哈希运算然后对数组长度进行取模就可以得到当前 Entry 对象在数组中的下标,那么我们可以一直调用 HashMap 的put 方法持续存储数据到数组中。但是存在一种现象,那就是根据不同的 Key 计算出来的结果有可能会完全相同,这种现象叫作“哈希冲突”。既然出现了哈希冲突,那么发生冲突的这个数据该如何存储呢?哈希冲突其实是无法避免的一个事实,既然无法避免,那么就应该想办法来解决这个问题,目前常用的方法主要是两种,一种是开放寻址法,另外一种是链表法。 开放寻址法是原理比较简单,就是在数组里面“另谋高就”,尝试寻找下一个空档位置。而链表法则不是寻找下一个空档位置,而是继续在当前冲突的地方存储,与现有的数据组成链表,以链表的形式进行存储。HashMap 的存储形式是数组+链表就是采用的链表法来解决哈希冲突问题的。具体的详细说明请继续往下看。 在日常开发中,开发者对于 HashMap 使用的最多的就是它的构造方法、put 方法以及get 方法了,下面就开始详细地从这三个方法出发,深入理解HashMap 的实现原理。
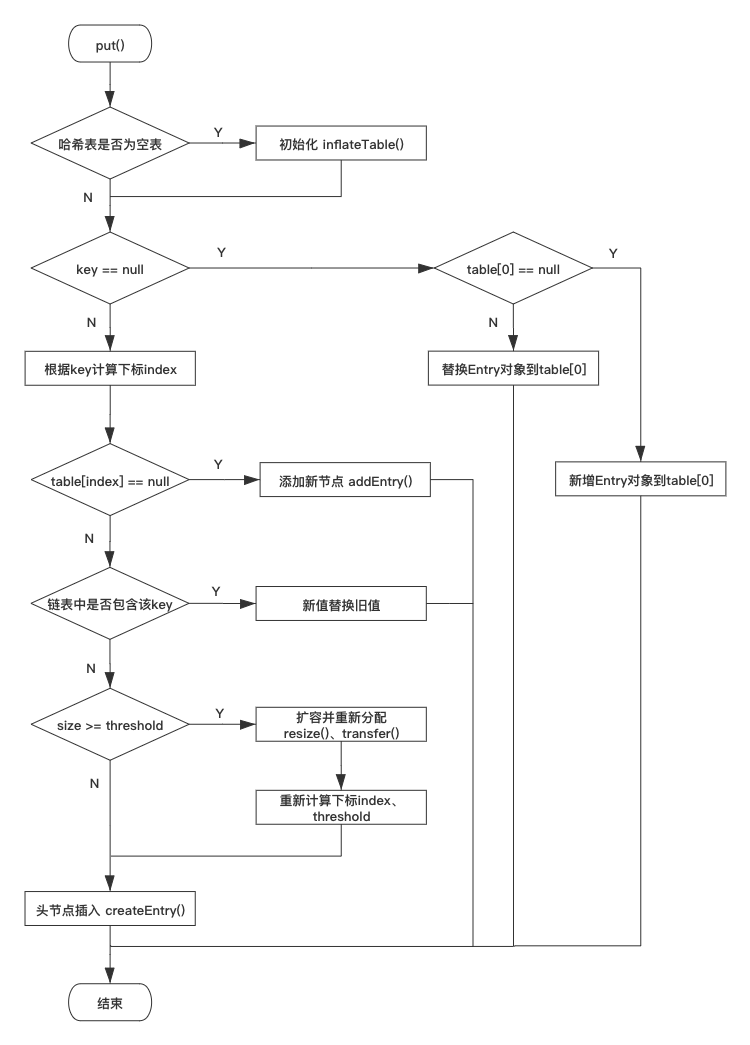
三、HashMap put、get 方法流程图
这里提供一个 HashMap 的 put 方法存储数据的流程图供读者参考:
这里提供一个 HashMap 的 get 方法获取数据的流程图供读者参考:
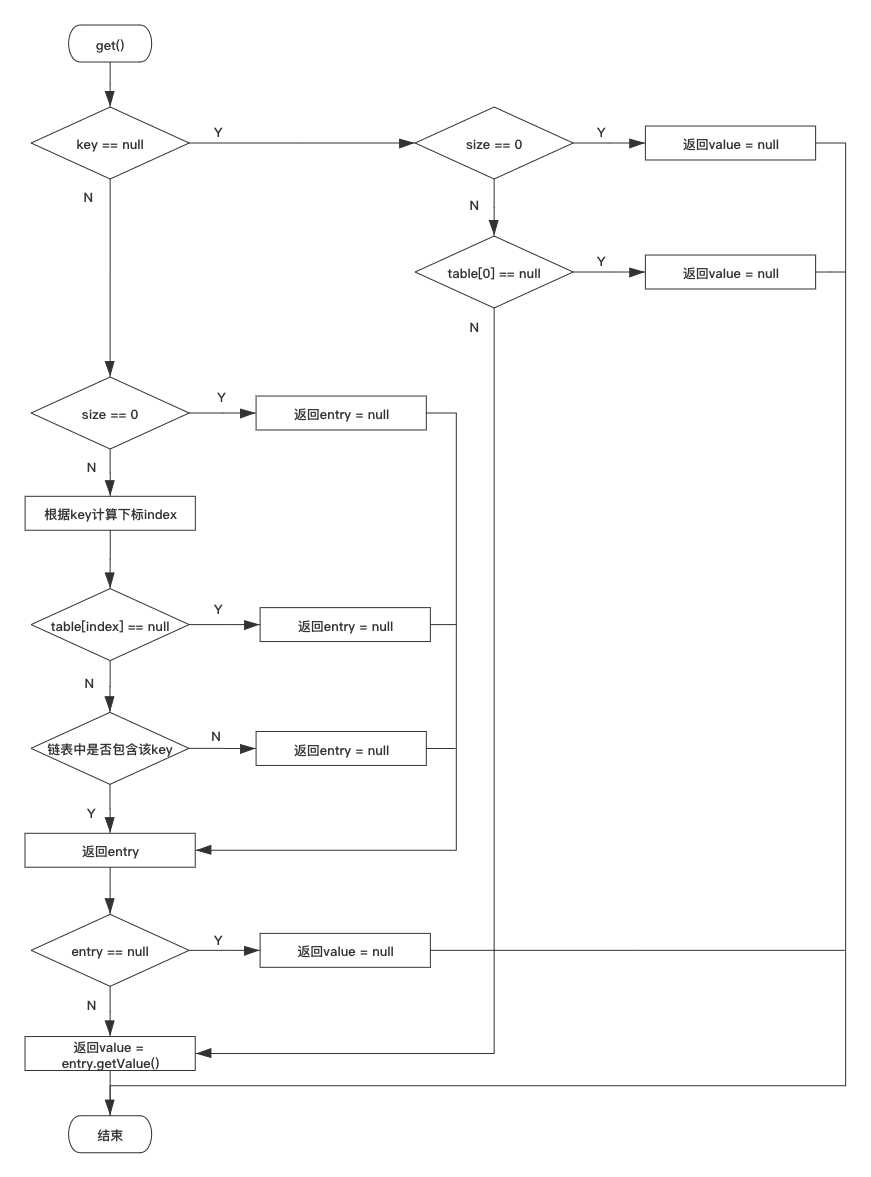
上面中 get 流程图画得稍微比正常的要复杂一些,只是为了描述流程更加清晰。
四、常见的 HashMap 的迭代方式
在实际开发过程中,我们对于 HashMap 的迭代遍历也是常见的操作,HashMap 的迭代遍历常用方式有如下几种:
- 方式一:迭代器模式
Map<String, String> map = new HashMap<>(16);
Iterator<Map.Entry<String, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, String> next = iterator.next();
System.out.println(next.getKey() + ":" + next.getValue());
}- 方式二:遍历 Set>方式
Map<String, String> map = new HashMap<>(16);
for (Map.Entry<String, String> entry : map.entrySet()) {
System.out.println(entry.getKey() + ":" + entry.getValue());
}- 方式三:forEach 方式(JDK8 特性,lambda)
Map<String, String> map = new HashMap<>(16);
map.forEach((key, value) -> System.out.println(key + ":" + value));- 方式四:keySet 方式
Map<String, String> map = new HashMap<>(16);
Iterator<String> keyIterator = map.keySet().iterator();
while (keyIterator.hasNext()) {
String key = keyIterator.next();
System.out.println(key + ":" + map.get(key));
}(推荐微课:Java微课)
把这四种方式进行比较,前三种其实属于同一种,都是迭代器遍历方式,如果要同时使用到 key 和 value,推荐使用前三种方式,如果仅仅使用到 key,那么推荐使用第四种。
文章来源:www.toutiao.com/a6862688709423137294/
以上就是W3Cschool编程狮关于hashmap底层原理的相关介绍了,希望对大家有所帮助。