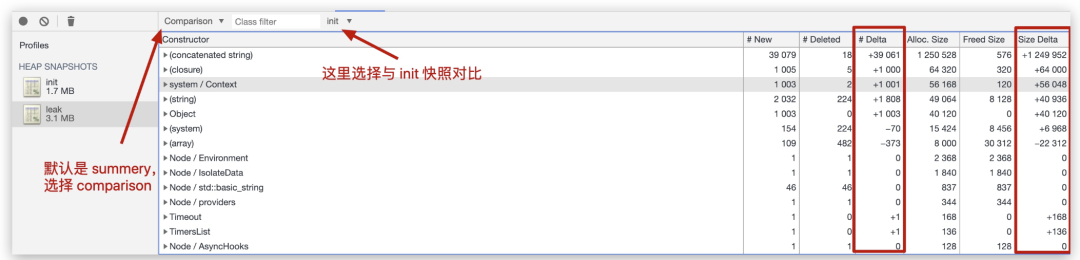
在日常工作中,我们难免会碰到对象属性复制的时候,下面就一个常见的三层 MVC 架构举例。
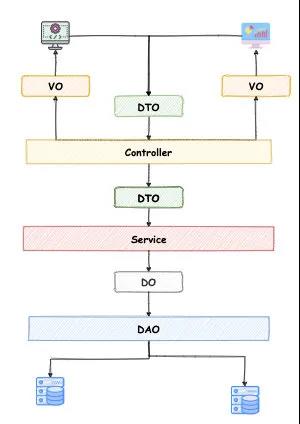
当我们在上面的架构下编程时,我们通常需要经历对象转化,比如业务请求流程经历三层机构后需要把 DTO 转为DO然后在数据库中保存。
当需要从数据查询数据页面展示时,查询数据经过三层架构将会从 DO 转为 DTO,最后再转为 VO,然后在页面中展示。
当业务简单的时候,我们手写代码,通过 getter/setter复制对象属性,十分简单。但是一旦业务变的复杂,对象属性变得很多,那么手写代码就会成为程序员的噩梦。
不但手写十分繁琐,非常耗时间,并且还可能容易出错。
小编之前就经历过一个项目,一个对象中大概有四五十个字段属性,那时候小编还刚入门,什么都不太懂,写了半天 getter/setter复制对象属性。
话外音:一个对象属性这么多,显然是不太合理的,我们设计过程应该将其拆分。
直到后来,小编了解到了对象属性复制工具类,使用之后,发现是真香,再也不用手写代码。再后来,碰到越来越多工具类,虽然核心功能都是一样的,但是还是存在很多差异。新手看到可能会一脸懵逼,不知道如何选择。
所以小编今天这篇介绍一下市面上常用的工具类:
- Apache BeanUtils
- Spring BeanUtils
- Cglib BeanCopier
- Dozer
- orika
- MapStruct
工具类特性
在介绍这些工具类之前,我们来看下一个好用的属性复制工具类,需要有哪些特性:
- 基本属性复制,这个是基本功能
- 不同类型的属性赋值,比如基本类型与其包装类型等
- 不同字段名属性赋值,当然字段名应该尽量保持一致,但是实际业务中,由于不同开发人员,或者笔误拼错单词,这些原因都可能导致会字段名不一致的情况
- 浅拷贝/深拷贝,浅拷贝会引用同一对象,如果稍微不慎,同时改动对象,就会踩到意想不到的坑
下面我们开始介绍工具类。
(推荐教程:Java教程)
Apache BeanUtils
首先介绍是第一位应该是 Java 领域属性复制的最有名的工具类「Apache BeanUtils」,这个工具类想必很多人或多或少用过或则见过。
没用过也没关系,我们来展示这个类的用法,用法非常简单。
首先我们引入依赖,这里使用最新版本:
<dependency>
<groupId>commons-beanutils</groupId>
<artifactId>commons-beanutils</artifactId>
<version>1.9.4</version>
</dependency>
假设我们项目中有如下类:
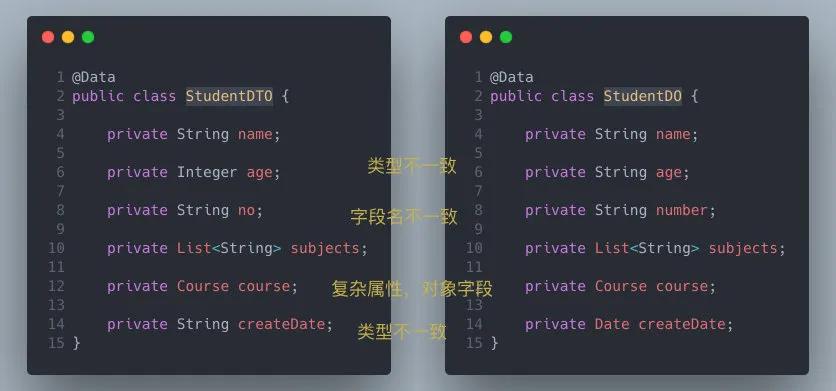
此时我们需要完成 DTO 对象转化到 DO 对象,我们只需要简单调用BeanUtils#copyProperties 方法就可以完成对象属性的复制。
StudentDTO studentDTO = new StudentDTO();
studentDTO.setName("小编");
studentDTO.setAge(18);
studentDTO.setNo("6666");
List<String> subjects = new ArrayList<>();
subjects.add("math");
subjects.add("english");
studentDTO.setSubjects(subjects);
studentDTO.setCourse(new Course("CS-1"));
studentDTO.setCreateDate("2020-08-08");
StudentDO studentDO = new StudentDO();
BeanUtils.copyProperties(studentDO, studentDTO);
不过,上面的代码如果你这么写,我们会碰到第一个问题,BeanUtils默认不支持 String转为 Date 类型。

为了解决这个问题,我们需要自己构造一个 Converter 转换类,然后使用 ConvertUtils注册,使用方法如下:
ConvertUtils.register(new Converter() {
@SneakyThrows
@Override
public <Date> Date convert(Class<Date> type, Object value) {
if (value == null) {
return null;
}
if (value instanceof String) {
String str = (String) value;
return (Date) DateUtils.parseDate(str, "yyyy-MM-dd");
}
return null;
}
}, Date.class);
此时,我们观察 studentDO与 studentDTO对象属性值:
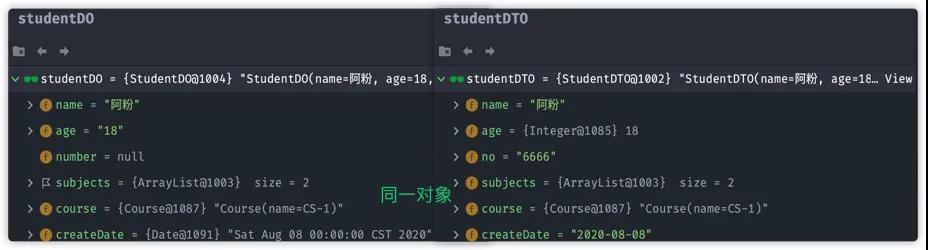
从上面的图我们可以得出BeanUtils一些结论:
- 普通字段名不一致的属性无法被复制
- 嵌套对象字段,将会与源对象使用同一对象,即使用浅拷贝
- 类型不一致的字段,将会进行默认类型转化。
虽然 BeanUtils 使用起来很方便,不过其底层源码为了追求完美,加了过多的包装,使用了很多反射,做了很多校验,所以导致性能较差,所以并阿里巴巴开发手册上强制规定避免使用 Apache BeanUtils。

Spring BeanUtils
Spring 属性复制工具类类名与 Apache 一样,基本用法也差不多。我先来看下 Spring BeanUtils 基本用法。
同样,我们先引入依赖,从名字我们可以看出,BeanUtils 位于 Spring-Beans 模块,这里我们依然使用最新模块。
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
<version>5.2.8.RELEASE</version>
</dependency>
这里我们使用 DTO 与 DO 复用上面的例子,转换代码如下:
// 省略上面赋值代码,与上面一致
StudentDO studentDO = new StudentDO();
BeanUtils.copyProperties(studentDTO, studentDO);
从用法可以看到,Spring BeanUtils 与 Apache 有一个最大的不同,两者源对象与目标对象参数位置不一样,小编之前没注意,用了 Spring 工具类,但是却是按照 Apache 的用法使用。
此时对比studentDO与 studentDTO对象:
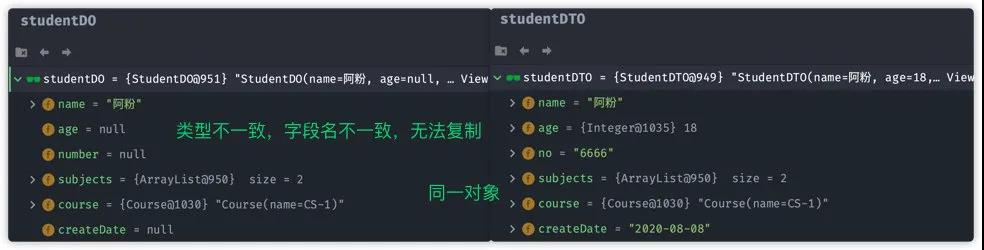
从上面的对比图我们可以得到一些结论:
- 字段名不一致,属性无法复制
- 类型不一致,属性无法复制。但是注意,如果类型为基本类型以及基本类型的包装类,这种可以转化
- 嵌套对象字段,将会与源对象使用同一对象,即使用浅拷贝
除了这个方法之外,Spring BeanUtils 还提供了一个重载方法:
public static void copyProperties(Object source, Object target, String... ignoreProperties)
使用这个方法,我们可以忽略某些不想被复制过去的属性:
BeanUtils.copyProperties(studentDTO, studentDO,"name");
这样,name 属性就不会被复制到 DO 对象中。
虽然 Spring BeanUtils 与 Apache BeanUtils 功能差不多,但是在性能上 Spring BeanUtils 还是完爆 Apache BeanUtils。主要原因还是在于 Spring 并没有与 Apache 一样使用反射做了过多校验,另外 Spring BeanUtils 内部使用了缓存,加快转换的速度。
所以两者选择,还是推荐使用 Spring BeanUtils。
Cglib BeanCopier
上面两个是小编日常工作经常使用,而下面的这些都是小编最近才开始接触的,比如 Cglib BeanCopier。这个使用方法,可能比上面两个类稍微复杂一点,下面我们来看下具体用法:
首先我们引入 Cglib 依赖:
<dependency>
<groupId>cglib</groupId>
<artifactId>cglib</artifactId>
<version>3.3.0</version>
</dependency>
画外音:如果你工程内还有 Spring-Core 的话,如果查找BeanCopier 这个类,可以发现两个不同的包的同名类。
一个属于 Cglib,另一个属于 Spring-Core。
其实 Spring-Core 内BeanCopier 实际就是引入了 Cglib 中的类,这么做的目的是为包了保证 Spring 使用长度 Cglib 相关类的稳定性,防止外部 Cglib 依赖不一致,导致 Spring 运行异常。
转换代码如下:
// 省略赋值语句
StudentDO studentDO = new StudentDO();
BeanCopier beanCopier = BeanCopier.create(StudentDTO.class, StudentDO.class, false);
beanCopier.copy(studentDTO, studentDO, null);
使用方法相比 BeanUtils, BeanCopier 稍微多了一步。 对比studentDO与 studentDTO对象:
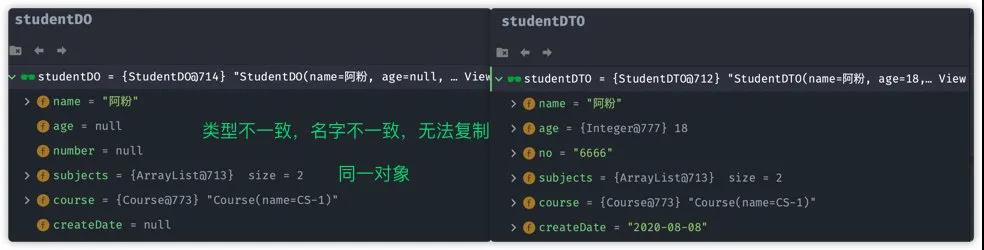
从上面可以得到与 Spring Beanutils 基本一致的结论:
- 字段名不一致,属性无法复制
- 类型不一致,属性无法复制。不过有点不一样,如果类型为基本类型/基本类型的包装类型,这两者无法被拷贝。
- 嵌套对象字段,将会与源对象使用同一对象,即使用浅拷贝
上面我们使用 Beanutils,遇到这种字段名,类型不一致的这种情况,我们没有什么好办法,只能手写硬编码。
不过在 BeanCopier 下,我们可以引入转换器,进行类型转换。
// 注意最后一个属性设置为 true
BeanCopier beanCopier = BeanCopier.create(StudentDTO.class, StudentDO.class, true);
// 自定义转换器
beanCopier.copy(studentDTO, studentDO, new Converter() {
@Override
public Object convert(Object source, Class target, Object context) {
if (source instanceof Integer) {
Integer num = (Integer) source;
return num.toString();
}
return null;
}
});
不过吐槽一下这个转换器,一旦我们自己打开使用转换器,所有属性复制都需要我们自己来了。比如上面的例子中,我们只处理当源对象字段类型为 Integer,这种情况,其他都没处理。我们得到 DO 对象将会只有 name 属性才能被复制。
Cglib BeanCopier 的原理与上面两个 Beanutils 原理不太一样,其主要使用 字节码技术动态生成一个代理类,代理类实现get 和 set方法。生成代理类过程存在一定开销,但是一旦生成,我们可以缓存起来重复使用,所有 Cglib 性能相比以上两种 Beanutils 性能比较好。
Dozer
Dozer ,中文直译为挖土机 ,这是一个「重量级」属性复制工具类,相比于上面介绍三个工具类,Dozer 具有很多强大的功能。
画外音:重量级/轻量级其实只是一个相对的说法,由于 Dozer 相对 BeanUtils 这类工具类来说,拥有许多高级功能,所以相对来说这是一个重量级工具类。
小编刚碰到这个工具类,就被深深折服,真的太强大了,上面我们期望的功能,Dozer 都给你实现了。
下面我们来看下使用方法,首先我们引入 Dozer 依赖:
<dependency>
<groupId>net.sf.dozer</groupId>
<artifactId>dozer</artifactId>
<version>5.4.0</version>
</dependency>
使用方法如下:
// 省略属性的代码
DozerBeanMapper mapper = new DozerBeanMapper();
StudentDO studentDO =
mapper.map(studentDTO, StudentDO.class);
System.out.println(studentDO);
Dozer 需要我们新建一个DozerBeanMapper,这个类作用等同与 BeanUtils,负责对象之间的映射,属性复制。
画外音:下面的代码我们可以看到,生成 DozerBeanMapper实例需要加载配置文件,随意生成代价比较高。在我们应用程序中,应该使用单例模式,重复使用DozerBeanMapper。
如果属性都是一些简单基本类型,那我们只要使用上面代码,可以快速完成属性复制。
不过很不幸,我们的代码中有字符串与 Date 类型转化,如果我们直接使用上面的代码,程序运行将会抛出异常。
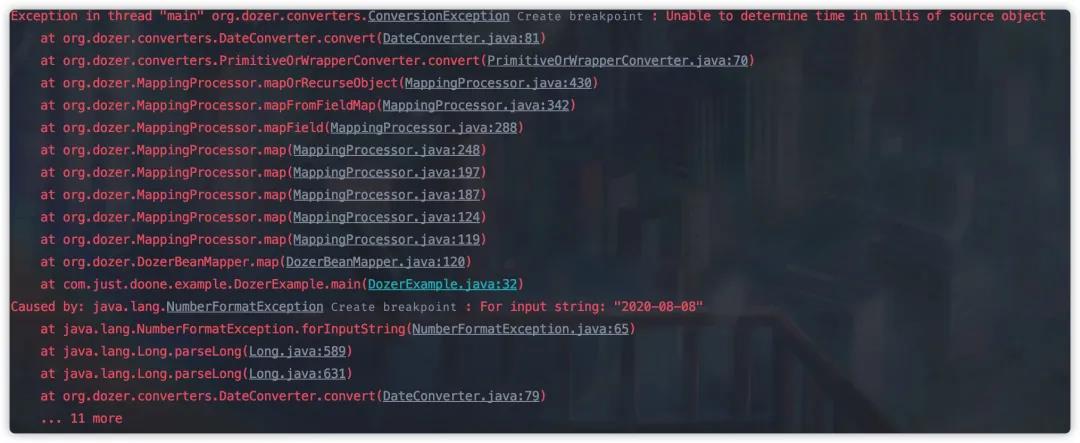
所以这里我们要用到 Dozer 强大的配置功能,我们总共可以使用下面三种方式:
其中,API 的方式比较繁琐,目前大部分使用 XML 进行,另外注解功能的是在 Dozer 5.3.2 之后增加的新功能,不过功能相较于 XML 来说较弱。
XML 使用方式
下面我们使用 XML 配置方式,配置 DTO 与 DO 关系,首先我们新建一个dozer/dozer-mapping.xml 文件:
<?xml version="1.0" encoding="UTF-8"?>
<mappings xmlns="http://dozer.sourceforge.net" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://dozer.sourceforge.net
http://dozer.sourceforge.net/schema/beanmapping.xsd">
<!-- 类级别的日期转换,默认使用这个格式转换 -->
<mapping date-format="yyyy-MM-dd HH:mm:ss">
<class-a>com.just.doone.example.domain.StudentDTO</class-a>
<class-b>com.just.doone.example.domain.StudentDO</class-b>
<!-- 在下面指定字段名不一致的映射关系 -->
<field>
<a>no</a>
<b>number</b>
</field>
<field>
<!-- 字段级别的日期转换,将会覆盖字段上的转换 -->
<a date-format="yy-MM-dd">createDate</a>
<b>createDate</b>
</field>
</mapping>
</mappings>
然后修改我们的 Java 代码,增加读取 Dozer 的配置文件:
DozerBeanMapper mapper = new DozerBeanMapper();
List<String> mappingFiles = new ArrayList<>();
// 读取配置文件
mappingFiles.add("dozer/dozer-mapping.xml");
mapper.setMappingFiles(mappingFiles);
StudentDO studentDO = mapper.map(studentDTO, StudentDO.class);
System.out.println(studentDO);
运行之后,对比studentDO与 studentDTO对象:
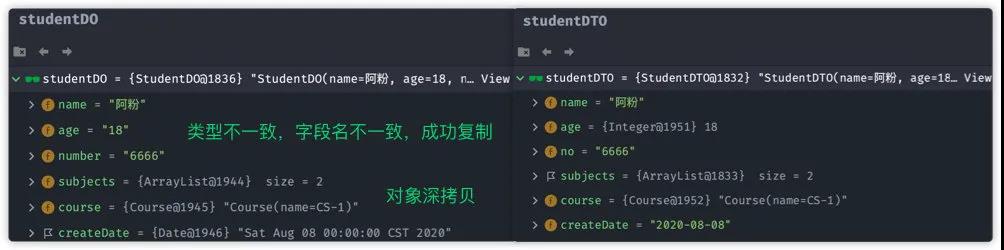
从上面的图我们可以发现:
- 类型不一致的字段,属性被复制
- DO 与 DTO 对象字段不是同一个对象,也就是深拷贝
- 通过配置字段名的映射关系,不一样字段的属性也被复制
除了上述这些相对简单的属性以外,Dozer 还支持很多额外的功能,比如枚举属性复制,Map 等集合属性复制等。
有些小伙伴刚看到 Dozer 的用法,可能觉得这个工具类比较繁琐,不像 BeanUtils 工具类一样一行代码就可以解。
其实 Dozer 可以很好跟 Spring 框架整合,我们可以在 Spring 配置文件提前配置,后续我们只要引用 Dozer 的相应的 Bean ,使用方式也是一行代码。
Dozer 与 Spring 整合,我们可以使用其 DozerBeanMapperFactoryBean,配置如下:
<bean class="org.dozer.spring.DozerBeanMapperFactoryBean">
<property name="mappingFiles"
value="classpath*:/*mapping.xml"/>
<!--自定义转换器-->
<property name="customConverters">
<list>
<bean class=
"org.dozer.converters.CustomConverter"/>
</list>
</property>
</bean>
DozerBeanMapperFactoryBean支持设置属性比较多,可以自定义设置类型转换,还可以设置其他属性。
另外还有一种简单的方法,我们可以在 XML 中配置DozerBeanMapper:
<bean id="org.dozer.Mapper" class="org.dozer.DozerBeanMapper">
<property name="mappingFiles">
<list>
<value>dozer/dozer-Mapperpping.xml</value>
</list>
</property>
</bean>
Spring 配置完成之后,我们在代码中可以直接注入:
@Autowired
Mapper mapper;
public void objMapping(StudentDTO studentDTO) {
// 直接使用
StudentDO studentDO =
mapper.map(studentDTO, StudentDO.class);
}
注解方式
Dozer 注解方式相比 XML 配置来说功能很弱,只能完成字段名不一致的映射。
上面的代码中,我们可以在 DTO 的 no 字段上使用 @Mapping 注解,这样我们在使用 Dozer 完成转换时,该字段属性将会被复制。
@Data
public class StudentDTO {
private String name;
private Integer age;
@Mapping("number")
private String no;
private List<String> subjects;
private Course course;
private String createDate;
}
虽然目前注解功能有点薄弱,不过后看版本官方可能增加新的注解功能,另外 XML 与注解可以一起使用。
最后 Dozer 底层本质上还是使用了反射完成属性的复制,所以执行速度并不是那么理想。
orika
orika也是一个跟 Dozer 类似的重量级属性复制工具类,也提供诸如 Dozer 类似的功能。但是 orika 无需使用繁琐 XML 配置,它自身提供一套非常简洁的 API 用法,非常容易上手。
首先我们引入其最新的依赖:
<dependency>
<groupId>ma.glasnost.orika</groupId>
<artifactId>orika-core</artifactId>
<version>1.5.4</version>
</dependency>
基本使用方法如下:
// 省略其他设值代码
// 这里先不要设值时间
// studentDTO.setCreateDate("2020-08-08");
MapperFactory mapperFactory = new DefaultMapperFactory.Builder().build();
MapperFacade mapper = mapperFactory.getMapperFacade();
StudentDO studentDO = mapper.map(studentDTO, StudentDO.class);
这里我们引入两个类 MapperFactory 与 MapperFacade,其中 MapperFactory 可以用于字段映射,配置转换器等,而 MapperFacade 的作用就与 Beanutils 一样,用于负责对象的之间的映射。
上面的代码中,我们故意注释了 DTO 对象中的 createDate 时间属性的设值,这是因为默认情况下如果没有单独设置时间类型的转换器,上面的代码将会抛错。
另外,上面的代码中,对于字段名不一致的属性,是不会复制的,所以我们需要单独设置。
下面我们就设置一个时间转换器,并且指定一下字段名:
MapperFactory mapperFactory = new DefaultMapperFactory.Builder().build();
ConverterFactory converterFactory = mapperFactory.getConverterFactory();
converterFactory.registerConverter(new DateToStringConverter("yyyy-MM-dd"));
mapperFactory.classMap(StudentDTO.class, StudentDO.class)
.field("no", "number")
// 一定要调用下 byDefault
.byDefault()
.register();
MapperFacade mapper = mapperFactory.getMapperFacade();
StudentDO studentDO = mapper.map(studentDTO, StudentDO.class);
上面的代码中,首先我们需要在 ConverterFactory 注册一个时间类型的转换器,其次我们还需要再 MapperFactory 指定不同字段名的之间的映射关系。
这里我们要注意,在我们使用 classMap 之后,如果想要相同字段名属性默认被复制,那么一定调用 byDefault方法。
简单对比一下 DTO 与 DO 对象:
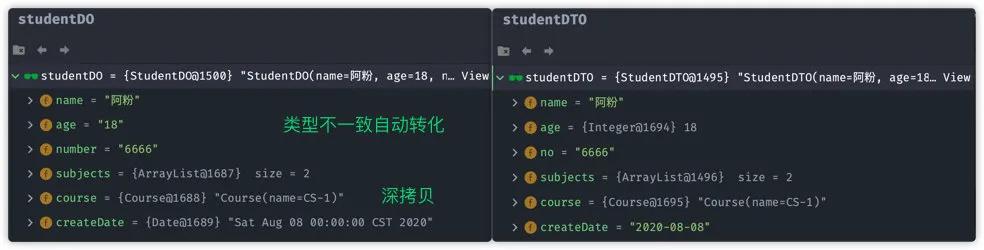
上图可以发现 orika 的一些特性:
- 默认支持类型不一致(基本类型/包装类型)转换
- 支持深拷贝
- 指定不同字段名映射关系,属性可以被成功复制。
另外 orika 还支持集合映射:
MapperFactory mapperFactory = new DefaultMapperFactory.Builder().build();
List<Person> persons = new ArrayList<>();
List<PersonDto> personDtos = mapperFactory.getMapperFacade().mapAsList(persons, PersonDto.class);
最后聊下 orika 实现原理,orika 与 dozer 底层原理不太一样,底层其使用了 javassist 生成字段属性的映射的字节码,然后直接动态加载执行字节码文件,相比于 Dozer 的这种使用反射原来的工具类,速度上会快很多。
MapStruct
不知不觉,一口气已经写了 5 个属性复制工具类,小伙伴都看到这里,那就不要放弃了,坚持看完,下面将介绍一个与上面这些都不太一样的工具类「MapStruct」。
上面介绍的这些工具类,不管使用反射,还是使用字节码技术,这些都需要在代码运行期间动态执行,所以相对于手写硬编码这种方式,上面这些工具类执行速度都会慢很多。
那有没有一个工具类的运行速度与硬编码这种方式差不多那?
这就要介绍 MapStruct 这个工具类,这个工具类之所以运行速度与硬编码差不多,这是因为他在编译期间就生成了 Java Bean 属性复制的代码,运行期间就无需使用反射或者字节码技术,所以确保了高性能。
另外,由于编译期间就生成了代码,所以如果有任何问题,编译期间就可以提前暴露,这对于开发人员来讲就可以提前解决问题,而不用等到代码应用上线了,运行之后才发现错误。
下面我们来看下,怎么使用这个工具类,首先我们先引入这个依赖:
<dependency>
<groupId>org.mapstruct</groupId>
<artifactId>mapstruct</artifactId>
<version>1.3.1.Final</version>
</dependency>
其次,由于 MapStruct 需要在编译器期间生成代码,所以我们需要 maven-compiler-plugin插件中配置:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>1.8</source> <!-- depending on your project -->
<target>1.8</target> <!-- depending on your project -->
<annotationProcessorPaths>
<path>
<groupId>org.mapstruct</groupId>
<artifactId>mapstruct-processor</artifactId>
<version>1.3.1.Final</version>
</path>
<!-- other annotation processors -->
</annotationProcessorPaths>
</configuration>
</plugin>
接下来我们需要定义映射接口,代码如下:
@Mapper
public interface StudentMapper {
StudentMapper INSTANCE = Mappers.getMapper(StudentMapper.class);
@Mapping(source = "no", target = "number")
@Mapping(source = "createDate", target = "createDate", dateFormat = "yyyy-MM-dd")
StudentDO dtoToDo(StudentDTO studentDTO);
}
我们需要使用 MapStruct 注解 @Mapper 定义一个转换接口,这样定义之后,StudentMapper 的功能就与 BeanUtils 等工具类一样了。
其次,由于我们 DTO 与 DO 对象中存在字段名不一致的情况,所以我们还在在转换方法上使用 @Mapping 注解指定字段映射。另外我们 createDate 字段类型不一致,这里我们还需要指定时间格式化类型。
上面定义完成之后,我们就可以直接使用 StudentMapper 一行代码搞定对象转换。
// 忽略其他代码
StudentDO studentDO = StudentMapper.INSTANCE.dtoToDo(studentDTO);
如果我们对象使用 Lombok 的话,使用 @Mapping指定不同字段名,编译期间可能会抛出如下的错误:

这个原因主要是因为 Lombok 也需要编译期间自动生成代码,这就可能导致两者冲突,当 MapStruct 生成代码时,还不存在 Lombok 生成的代码。
解决办法可以在 maven-compiler-plugin插件配置中加入 Lombok,如下:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>1.8</source> <!-- depending on your project -->
<target>1.8</target> <!-- depending on your project -->
<annotationProcessorPaths>
<path>
<groupId>org.mapstruct</groupId>
<artifactId>mapstruct-processor</artifactId>
<version>1.3.1.Final</version>
</path>
<path>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.12</version>
</path>
<!-- other annotation processors -->
</annotationProcessorPaths>
</configuration>
</plugin>
输出 DO 与 DTO 如下:
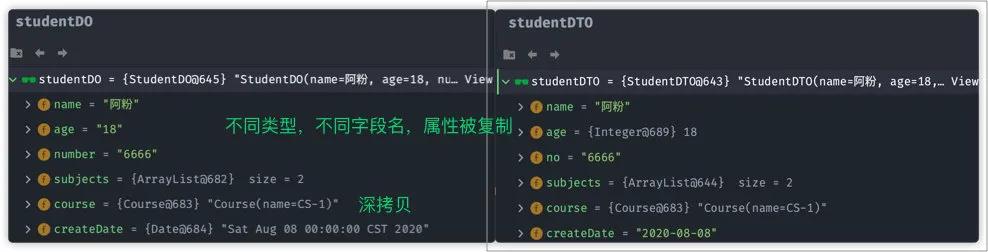
从上图中我们可以得到一些结论:
-
- 基本类型与包装类型
- 基本类型的包装类型与 String
上面介绍的例子介绍一些简单字段映射,如果小伙伴在工作总共还碰到其他的场景,可以先查看一下这个工程,查看一下有没有结局解决办法:github.com/mapstruct/mapstruct-examples
上面我们已经知道 MapStruct 在编译期间就生成了代码,下面我们来看下自动生成代码:
public class StudentMapperImpl implements StudentMapper {
public StudentMapperImpl() {
}
public StudentDO dtoToDo(StudentDTO studentDTO) {
if (studentDTO == null) {
return null;
} else {
StudentDO studentDO = new StudentDO();
studentDO.setNumber(studentDTO.getNo());
try {
if (studentDTO.getCreateDate() != null) {
studentDO.setCreateDate((new SimpleDateFormat("yyyy-MM-dd")).parse(studentDTO.getCreateDate()));
}
} catch (ParseException var4) {
throw new RuntimeException(var4);
}
studentDO.setName(studentDTO.getName());
if (studentDTO.getAge() != null) {
studentDO.setAge(String.valueOf(studentDTO.getAge()));
}
List<String> list = studentDTO.getSubjects();
if (list != null) {
studentDO.setSubjects(new ArrayList(list));
}
studentDO.setCourse(studentDTO.getCourse());
return studentDO;
}
}
}
从生成的代码来看,里面并没有什么黑魔法,MapStruct 自动生成了一个实现类 StudentMapperImpl,里面实现了 dtoToDo,方法里面调用getter/setter设值。
从这个可以看出,MapStruct 作用就相当于帮我们手写getter/setter设值,所以它的性能会很好。
(推荐微课:Java微课)
总结
看文这篇文章,我们一共学习了 7 个属性复制工具类,这么多工具类我们该如何选择那?小编讲讲自己的一些见解:
第一,首先我们直接抛弃 Apache Beanutils ,这个不用说了,阿里巴巴规范都这样定了,我们就不要使用好了。
第二,当然是看工具类的性能,这些工具类的性能,网上文章介绍的比较多,小编就复制过来,大家可以比较一下。
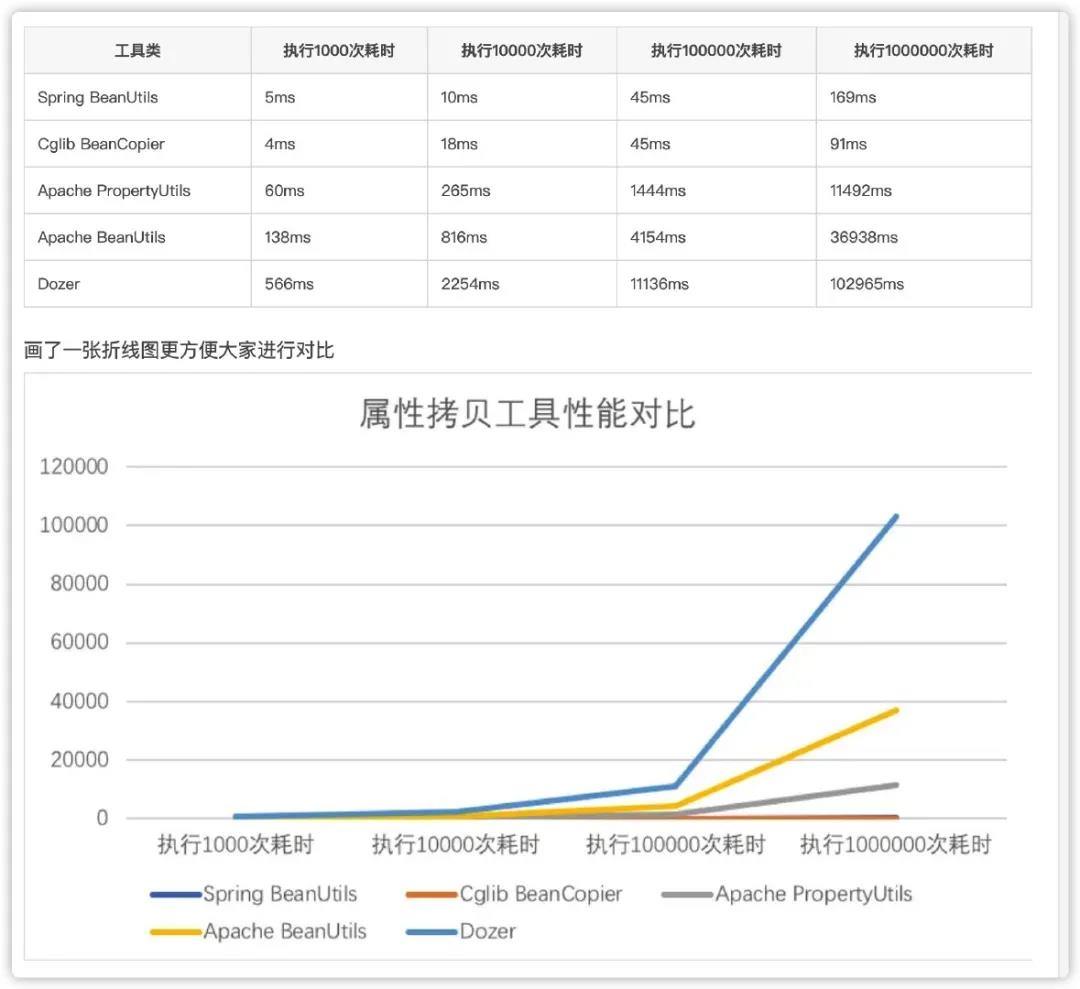
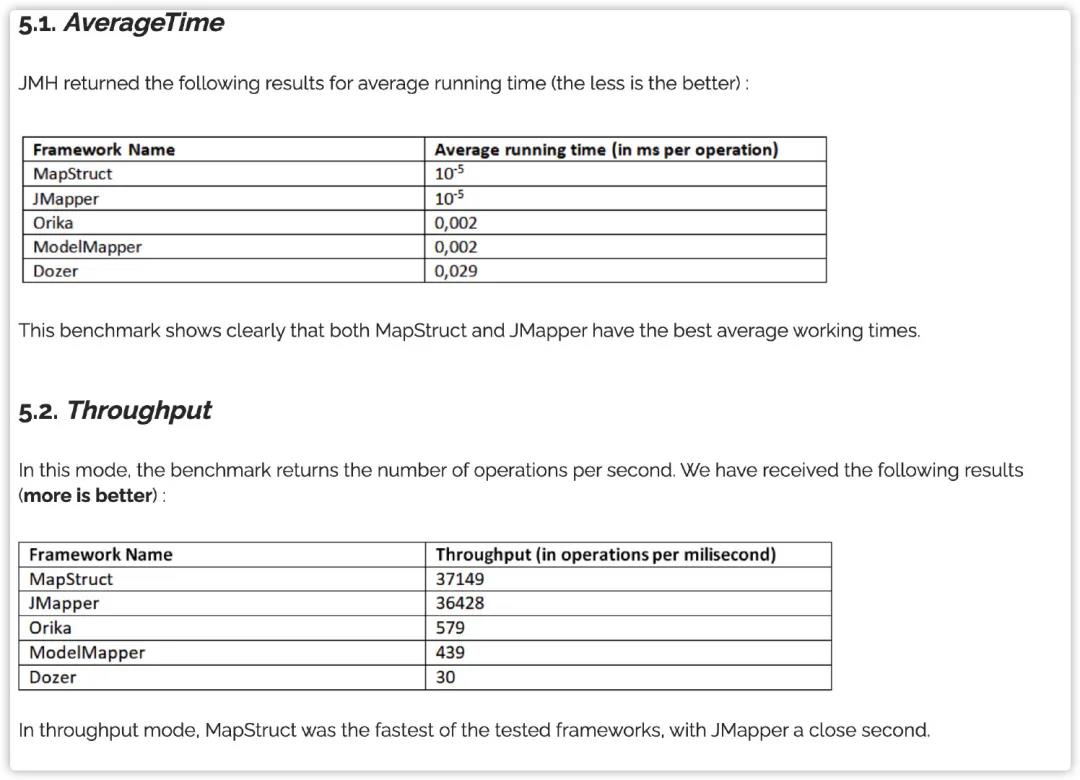
可以看到 MapStruct 的性能可以说还是相当优秀。那么如果你的业务对于性能,响应等要求比较高,或者你的业务存在大数据量导入/导出的场景,而这个代码存在对象转化,那就切勿使用 Apache Beanutils, Dozer 这两个工具类。
第三,其实很大一部分应用是没有很高的性能的要求,只要工具类能提供足够的便利,就可以接受。如果你的业务中没有很复杂的的需求,那么直接使用 Spring Beanutils 就好了,毕竟 Spring 的包大部分应用都在使用,我们都无需导入其他包了。
那么如果业务存在不同类型,不同的字段名,那么可以考虑使用 orika 等这种重量级工具类。
文章来源:公众号–Java极客技术 作者:鸭血粉丝
以上就是W3Cschool编程狮关于 6种对象复制工具类,该如何选择呢?的相关介绍了,希望对大家有所帮助。