三天前,React团队发布了React17的第一个RC版本,这个版本最大的特性就是“无新特性”。
那么,从v16到v17这一年多时间React团队究竟在做什么?
遥想从v15到v16,React团队花了两年时间将源码架构中的Stack Reconciler重构为Fiber Reconciler,事情一定没有这么简单。
事实上,这次版本更迭确实有“新特性” —— 替换了内部使用的启发式更新算法。
只不过这个特性对开发者是无感知的。
本文接下来将讲述如下内容:
- 起源:为什么会出现启发式更新算法?
- 现状:React16的启发式更新算法及他的不足
- 未来:React17的启发式更新算法
为什么会出现启发式更新算法
框架的运行性能是框架设计者在设计框架时需要重点关注的点。
Vue使用模版语法,可以在编译时对确定的模版作出优化。
而React纯JS写法太过灵活,使他在编译时优化方面先天不足。
所以,React的优化主要在运行时。
React15的痛点
在运行时优化方面,React一直在努力。
比如,React15实现了batchedUpdates(批量更新)。
即同一事件回调函数上下文中的多次setState只会触发一次更新。
但是,如果单次更新就很耗时,页面还是会卡顿(这在一个维护时间很长的大应用中是很常见的)。
这是因为React15的更新流程是同步执行的,一旦开始更新直到页面渲染前都不能中断。
为了解决同步更新长时间占用线程导致页面卡顿的问题,也为了探索运行时优化的更多可能,React开始重构并一直持续至今。
重构的目标是实现Concurrent Mode(并发模式)。
(推荐教程:React教程)
Concurrent Mode
Concurrent Mode的目的是实现一套可中断/恢复的更新机制。
其由两部分组成:
其中,协程架构就是React16中实现的Fiber Reconciler。
我们可以将Fiber Reconciler理解为React自己实现的Generator。
Fiber Reconciler从理念到源码的详细介绍见这里
协程架构使更新可以在需要的时机被中断,这样浏览器就有时间完成样式布局与样式绘制,减少卡顿(掉帧)的出现。
当浏览器进入下一次事件循环,协程架构可以恢复中断或者抛弃之前的更新,重新开始新的更新流程。
启发式更新算法就是控制协程架构工作方式的算法。
React16的启发式更新算法
启发式更新算法的启发式指什么呢?
启发式指不通过显式的指派,而是通过优先级调度更新。
其中优先级来源于人机交互的研究成果。
比如:
人机交互的研究成果表明:
- 当用户在输入框输入内容时,希望输入的内容能实时响应在输入框
- 当异步请求数据后,即使等待一会儿再显示内容,用户也是可以接受的
基于此,在React16中
输入框输入内容触发的更新优先级 > 请求数据返回后触发更新优先级
算法实现 在React16、17中,在组件内执行this.setState后会在该组件对应的fiber节点内产生一种链表数据结构update。
其中,update.expirationTimes为类似时间戳的字段,表示优先级。
expirationTimes从字面意义理解为过期时间。
该值离当前时间越接近,该update 优先级越高。
当update.expirationTimes超过当前时间,则代表该update过期,优先级变为最高(即同步)。
一棵fiber树的多个fiber节点可能存在多个update。
每次Fiber Reconciler调度更新时,会在所有fiber节点的所有update.expirationTimes中选择一个expirationTimes(一般选择最大的),作为本次更新的优先级。
并从根fiber节点开始向下构建新的fiber树。
构建过程中如果某个fiber节点包含update,且
update.expirationTimes >= expirationTimes
则该update对应的state变化会体现在本次更新中。
可以理解为:每次更新,都会选定一个优先级(expirationTimes),最终页面会渲染为该优先级对应update的快照。
举个例子,我们有如图所示fiber树,当前还没有更新产生,所以没有构建中的fiber树。
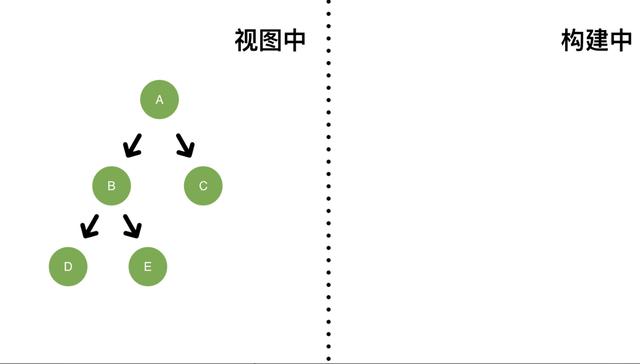
当在 C 创建一个低优先级update,调度更新,本次更新选择的优先级为低优先级。
开始构建新的fiber树(图右侧)。
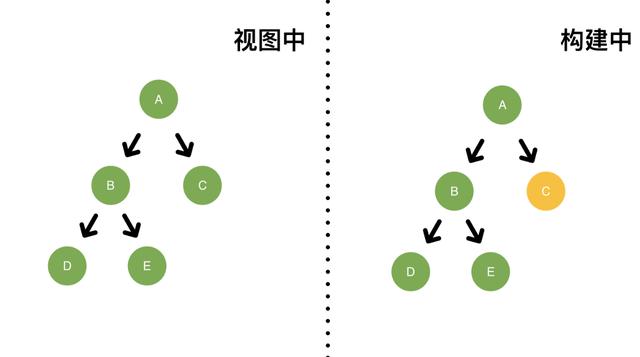
此时,我们在 D 创建一个高优先级update。
这会中断进行中的低优先级更新,重新开始以高优先级生成一棵fiber树。
由于之前的更新被中断,还没有任何渲染操作,此时视图中(左图)还没有任何变化。
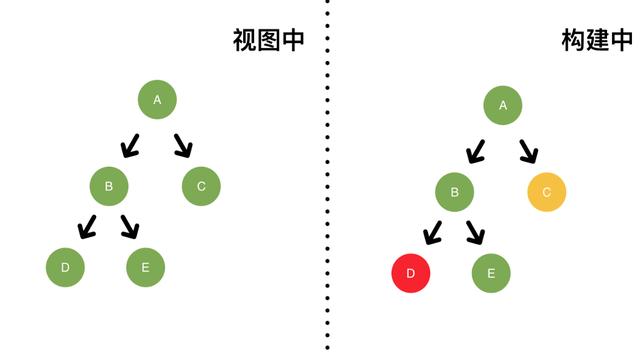
本次更新选定的优先级为高优先级,C 的update(低优先级)会被跳过。
更新完成后新的fiber树会被渲染到视图中。
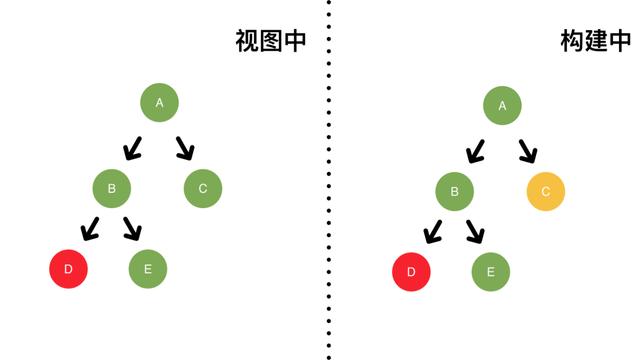
由于 C 被跳过,所以不会在视图(左图)中体现。
接下来我们在 E 触发一次高优先级update。
C 虽然包含低优先级update,但随着时间的推移,他的expirationTimes已经过期,变为高优先级。
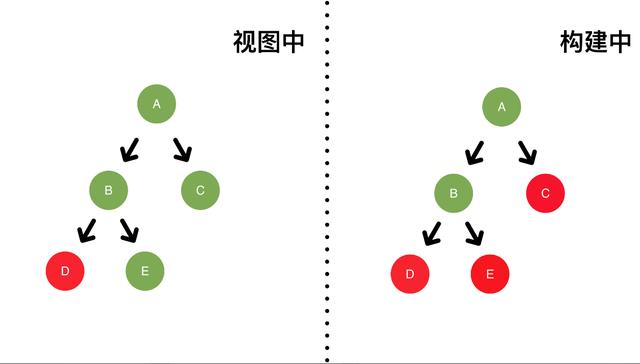
所以本次更新会有 C E 两个fiber节点产生变化。
最终完成更新后,视图如下:
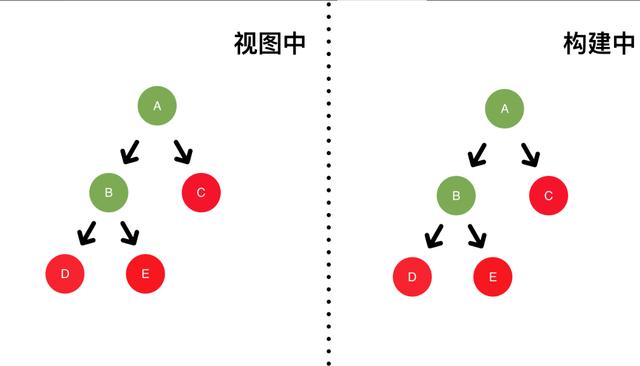
算法缺陷
如果只考虑中断/继续这样的 CPU 操作,以expirationTimes大小作为衡量优先级依据的模型可以很好工作。
但是expirationTimes模型不能满足 IO 操作(Suspense)。
在该模型下,高优先级 IO 任务(Suspense)会中断低优先级 CPU 任务。
还记得么,每次更新,都是以某一优先级作为整棵树的优先级更新标准,而不仅仅是某一组件,即使更新的源头(update)确实是某个组件产生的。
expirationTimes模型只能区分是否>=expirationTimes这种情况。
为了拓展Concurrent Mode能力边界,需要一种更细粒度的启发式优先级更新算法。
(推荐教程:React入门实例教程)
React17启发式更新算法
最理想的模型是:可以指定任意几个优先级,更新会以这些优先级对应update生成页面快照。
但是现有架构下,该方案实现上有瓶颈。
妥协之下,React17的解决方案是:指定一个连续的优先级区间,每次更新都会以区间内包含的优先级生成对应页面快照。
这种优先级区间模型被称为lanes(车道模型)。
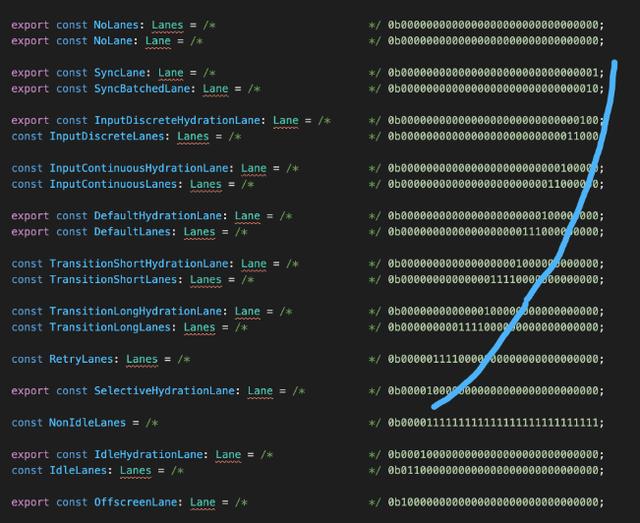
具体做法是:使用一个31位的二进制代表31种可能性。
- 其中每个
bit被称为一个lane(车道),代表优先级
- 某几个
lane组成的二进制数被称为一个lanes,代表一批优先级
可以从源码中看到,从蓝线一路划下去,每个bit都对应一个lane或lanes。
当update产生,会根据React16同样的启发式方式,获得如下优先级的一种:
export const SyncLanePriority: LanePriority = 17; export const SyncBatchedLanePriority: LanePriority = 16; export const InputDiscreteLanePriority: LanePriority = 14; export const InputContinuousLanePriority: LanePriority = 12; export const DefaultLanePriority: LanePriority = 10; export const TransitionShortLanePriority: LanePriority = 8; export const TransitionLongLanePriority: LanePriority = 6;
其中值越高,优先级越大。
比如:
- 点击事件回调中触发
this.setState产生的update会获得InputDiscreteLanePriority。
- 同步的
update会获得SyncLanePriority。
接下来,update会以priority为线索寻找没被占用的lane。
如果当前fiber树已经存在更新且更新的lanes包含了该lane,则update需要寻找其他lane。
比如,InputDiscreteLanePriority对应的lanes为InputDiscreteLanes。
// 第4、5位为1 const InputDiscreteLanes: Lanes = 0b0000000000000000000000000011000;
该lanes包含第4、5位 2 个 bit位。
如果其中
// 第五位为1 0b0000000000000000000000000010000
第五位的lane已经被占用,则该update可以尝试占有后一个,即
// 第四位为1 0b0000000000000000000000000001000
如果InputDiscreteLanes的两个lane都被占用,则该update的优先级会下降到InputContinuousLanePriority并继续寻找空余的lane。
这个过程就像:购物中心每一层(不同优先级)都有一个露天停车场(lanes),停车场有多个车位(lane)。
我们先开车到顶楼找车位(lane),如果没有车位就下一楼继续找。
直到找到空余车位。
由于lanes可以包含多个lane,可以很方便的区分 IO 操作(Suspense)与 CPU 操作。
当构建fiber树进入构建Suspense子树时,会将Suspense的lane插入本次更新选定的lanes中。
当构建离开Suspense子树时,会将Suspense lane从本次更新的lanes中移除。
(推荐微课:React微课)
总结
React16的expirationTimes模型只能区分是否>=expirationTimes决定节点是否更新。
React17的lanes模型可以选定一个更新区间,并且动态的向区间中增减优先级,可以处理更细粒度的更新。
以上就是关于React17的新特性–启发式更新算法的相关介绍了,希望对大家有所帮助。