想成为一名合格的程序员,那么代码优化是相当重要的一部分,一份高质量的代码,可以让人一目了然,既方便自己,也方便他人。
if else、switch case 是日常开发中最常见的条件判断语句,这种看似简单的语句,当遇到复杂的业务场景时,如果处理不善,就会出现大量的逻辑嵌套,可读性差并且难以扩展。
编写高质量可维护的代码,我们先从最小处入手,一起来看看在前端开发过程中,可以从哪些方面来优化逻辑判断?
下面我们会分别从 JavaScript 语法和 React JSX 语法两个方面来分享一些优化的技巧。
JavaScript 语法篇
嵌套层级优化
function supply(fruit, quantity) {
const redFruits = ['apple', 'strawberry', 'cherry', 'cranberries'];
// 条件 1: 水果存在
if(fruit) {
// 条件 2: 属于红色水果
if(redFruits.includes(fruit)) {
console.log('红色水果');
// 条件 3: 水果数量大于 10 个
if (quantity > 10) {
console.log('数量大于 10 个');
}
}
} else {
throw new Error('没有水果啦!');
}
} 分析上面的条件判断,存在三层 if 条件嵌套。
如果提前 return 掉无效条件,将 if else的多重嵌套层次减少到一层,更容易理解和维护。
function supply(fruit, quantity) {
const redFruits = ['apple', 'strawberry', 'cherry', 'cranberries'];
if(!fruit) throw new Error('没有水果啦'); // 条件 1: 当 fruit 无效时,提前处理错误
if(!redFruits.includes(fruit)) return; // 条件 2: 当不是红色水果时,提前 return
console.log('红色水果');
// 条件 3: 水果数量大于 10 个
if (quantity > 10) {
console.log('数量大于 10 个');
}
}多条件分支的优化处理
当需要枚举值处理不同的业务分支逻辑时, 第一反应是写下 if else ?我们来看一下:
function pick(color) {
// 根据颜色选择水果
if(color === 'red') {
return ['apple', 'strawberry'];
} else if (color === 'yellow') {
return ['banana', 'pineapple'];
} else if (color === 'purple') {
return ['grape', 'plum'];
} else {
return [];
}
}在上面的实现中:
if else分支太多if else更适合于条件区间判断,而switch case更适合于具体枚举值的分支判断
使用 switch case 优化上面的代码后:
function pick(color) {
// 根据颜色选择水果
switch (color) {
case 'red':
return ['apple', 'strawberry'];
case 'yellow':
return ['banana', 'pineapple'];
case 'purple':
return ['grape', 'plum'];
default:
return [];
}
} switch case 优化之后的代码看上去格式整齐,思路很清晰,但还是很冗长。继续优化:
- 借助
Object的{ key: value }结构,我们可以在Object中枚举所有的情况,然后将key作为索引,直接通过Object.key或者Object[key]来获取内容
const fruitColor = {
red: ['apple', 'strawberry'],
yellow: ['banana', 'pineapple'],
purple: ['grape', 'plum'],
}
function pick(color) {
return fruitColor[color] || [];
}- 使用
Map数据结构,真正的 (key,value) 键值对结构 ;
const fruitColor = new Map()
.set('red', ['apple', 'strawberry'])
.set('yellow', ['banana', 'pineapple'])
.set('purple', ['grape', 'plum']);
function pick(color) {
return fruitColor.get(color) || [];
}优化之后,代码更简洁、更容易扩展。
为了更好的可读性,还可以通过更加语义化的方式定义对象,然后使用 Array.filter 达到同样的效果。
const fruits = [
{ name: 'apple', color: 'red' },
{ name: 'strawberry', color: 'red' },
{ name: 'banana', color: 'yellow' },
{ name: 'pineapple', color: 'yellow' },
{ name: 'grape', color: 'purple' },
{ name: 'plum', color: 'purple' }
];
function pick(color) {
return fruits.filter(f => f.color == color);
}(推荐教程:JavaScript教程)
使用数组新特性简化逻辑判断
巧妙的利用 ES6 中提供的数组新特性,也可以让我们更轻松的处理逻辑判断。
多条件判断
编码时遇到多个判断条件时,本能的写下下面的代码(其实也是最能表达业务逻辑的面向过程编码)。
function judge(fruit) {
if (fruit === 'apple' || fruit === 'strawberry' || fruit === 'cherry' || fruit === 'cranberries' ) {
console.log('red');
}
} 但是当 type 未来到 10 种甚至更多时, 我们只能继续添加 || 来维护代码么 ?
试试 Array.includes ~
// 将判断条件抽取成一个数组
const redFruits = ['apple', 'strawberry', 'cherry', 'cranberries'];
function judge(type) {
if (redFruits.includes(fruit)) {
console.log('red');
}
}判断数组中是否所有项都满足某条件
const fruits = [
{ name: 'apple', color: 'red' },
{ name: 'banana', color: 'yellow' },
{ name: 'grape', color: 'purple' }
];
function match() {
let isAllRed = true;
// 判断条件:所有的水果都必须是红色
for (let f of fruits) {
if (!isAllRed) break;
isAllRed = (f.color === 'red');
}
console.log(isAllRed); // false
}上面的实现中,主要是为了处理数组中的所有项都符合条件。
使用 Array.every 可以很容的实现这个逻辑:
const fruits = [
{ name: 'apple', color: 'red' },
{ name: 'banana', color: 'yellow' },
{ name: 'grape', color: 'purple' }
];
function match() {
// 条件:所有水果都必须是红色
const isAllRed = fruits.every(f => f.color == 'red');
console.log(isAllRed); // false
}判断数组中是否有某一项满足条件
Array.some ,它主要处理的场景是判断数组中是否有一项满足条件。
如果想知道是否有红色水果,可以直接使用 Array.some 方法:
const fruits = [
{ name: 'apple', color: 'red' },
{ name: 'banana', color: 'yellow' },
{ name: 'grape', color: 'purple' }
];
// 条件:是否有红色水果
const isAnyRed = fruits.some(f => f.color == 'red'); 还有许多其他数组新特性,比如 Array.find、Array.slice、Array.findIndex、Array.reduce、Array.splice 等,在实际场景中可以根据需要选择使用。
函数默认值
使用默认参数
const buyFruit = (fruit,amount) => {
if(!fruit){
return
}
amount = amount || 1;
console.log(amount)
}我们经常需要处理函数内部的一些参数默认值,上面的代码大家都不陌生,使用函数的默认参数,可以很好的帮助处理这种场景。
const buyFruit = (fruit,amount = 1) => {
if(!fruit){
return
}
console.log(amount,'amount')
} 我们可以通过 Babel 的转译来看一下默认参数是如何实现的。
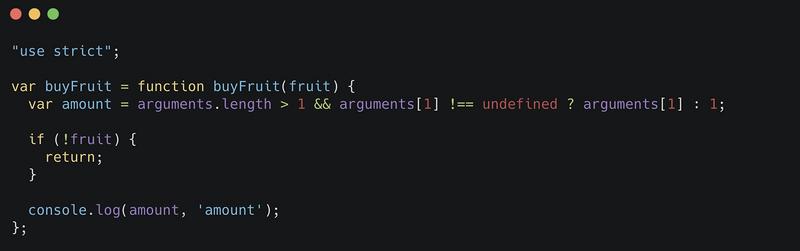
从上面的转译结果可以发现,只有参数为 undefined 时才会使用默认参数。
测试的执行结果如下:
buyFruit('apple',''); // amount
buyFruit('apple',null); //null amount
buyFruit('apple'); //1 amount 所以使用默认参数的情况下,我们需要注意的是默认参数 amount=1 并不等同于 amount || 1。
使用解构与默认参数
当函数参数是对象时,我们可以使用解构结合默认参数来简化逻辑。
Before:
const buyFruit = (fruit,amount) => {
fruit = fruit || {};
if(!fruit.name || !fruit.price){
return;
}
...
amount = amount || 1;
console.log(amount)
}After:
const buyFruit = ({ name,price }={},amount) => {
if(!name || !prices){
return;
}
console.log(amount)
}复杂数据解构
当处理比较简的对象时,解构与默认参数的配合是非常好的,但在一些复杂的场景中,我们面临的可能是更复杂的结构。
const oneComplexObj = {
firstLevel:{
secondLevel:[{
name:"",
price:""
}]
}
}这个时候如果再通过解构去获取对象里的值。
const {
firstLevel:{
secondLevel:[{name,price]=[]
}={}
} = oneComplexObj; 可读性就会比较差,而且需要考虑多层解构的默认值以及数据异常情况。
这种情况下,如果项目中使用 lodash 库,可以使用其中的 lodash/get 方法。
import lodashGet from 'lodash/get';
const { name,price} = lodashGet(oneComplexObj,'firstLevel.secondLevel[0]',{});策略模式优化分支逻辑处理
策略模式:定义一系列的算法,把它们一个个封装起来, 并且使它们可相互替换。
使用场景:策略模式属于对象行为模式,当遇到具有相同行为接口、行为内部不同逻辑实现的实例对象时,可以采用策略模式;或者是一组对象可以根据需要动态的选择几种行为中的某一种时,也可以采用策略模式;这里以第二种情况作为示例:
Before:
const TYPE = {
JUICE:'juice',
SALAD:'salad',
JAM:'jam'
}
function enjoy({type = TYPE.JUICE,fruits}){
if(!fruits || !fruits.length) {
console.log('请先采购水果!');
return;
}
if(type === TYPE.JUICE) {
console.log('榨果汁中...');
return '果汁';
}
if(type === TYPE.SALAD) {
console.log('做沙拉中...');
return '拉沙';
}
if(type === TYPE.JAM) {
console.log('做果酱中...');
return '果酱';
}
return;
}
enjoy({type:'juice',fruits});使用思路:定义策略对象封装不同行为、提供策略选择接口,在不同的规则时调用相应的行为。
After:
const TYPE = {
JUICE:'juice',
SALAD:'salad',
JAM:'jam'
}
const strategies = {
[TYPE.JUICE]: function(fruits){
console.log('榨果汁中...');
return '果汁';
},
[TYPE.SALAD]:function(fruits){
console.log('做沙拉中...');
return '沙拉';
},
[TYPE.JAM]:function(fruits){
console.log('做果酱中...');
return '果酱';
},
}
function enjoy({type = TYPE.JUICE,fruits}) {
if(!type) {
console.log('请直接享用!');
return;
}
if(!fruits || !fruits.length) {
console.log('请先采购水果!');
return;
}
return strategies[type](fruits);
}
enjoy({type:'juice',fruits});(推荐微课:JavaScript微课)
框架篇之 React JSX 逻辑判断优化
JSX 是一个看起来很像 XML 的 JavaScript 语法扩展。一般在 React 中使用 JSX 来描述界面信息,ReactDOM.render() 将 JSX 界面信息渲染到页面上。
在 JSX 中支持 JavaScript 表达式,日常很常见的循环输出子组件、三元表达式判断、再复杂一些直接抽象出一个函数。
在 JSX 中写这么多 JavaScript 表达式,整体代码看起来会有点儿杂乱。试着优化一下!
JSX-Control-Statements
JSX-Control-Statements 是一个 Babel 插件,它扩展了 JSX 的能力,支持以标签的形式处理条件判断、循环。
If 标签
<If> 标签内容只有在 condition 为 true 时才会渲染,等价于最简单的三元表达式。
Before:
{ condition() ? 'Hello World!' : null }After:
<If condition={ condition() }>Hello World!</If> 注意:<Else /> 已被废弃,复杂的条件判断可以使用 <Choose> 标签。
Choose 标签
<Choose> 标签下包括至少一个 <When> 标签、可选的 <Otherwise> 标签。
<When> 标签内容只有在 condition 为 true 时才会渲染,相当于一个 if 条件判断分支。
<Otherwise> 标签则相当于最后的 else分支。
Before:
{ test1 ? <span>IfBlock1</span> : test2 ? <span>IfBlock2</span> : <span>ElseBlock</span> }After:
<Choose>
<When condition={ test1 }>
<span>IfBlock1</span>
</When>
<When condition={ test2 }>
<span>IfBlock2</span>
</When>
<Otherwise>
<span>ElseBlock</span>
</Otherwise>
</Choose>For 标签
<For> 标签需要声明 of、each 属性。
of 接收的是可以使用迭代器访问的对象。
each 代表迭代器访问时的当前指向元素。
Before:
{
(this.props.items || []).map(item => {
return <span key={ item.id }>{ item.title }</span>
})
}After:
<For each="item" of={ this.props.items }>
<span key={ item.id }>{ item.title }</span>
</For> 注意:<For> 标签不能作为根元素。
With 标签
<With> 标签提供变量传参的功能。
Before:
renderFoo = (foo) => {
return <span>{ foo }</span>;
}
// JSX 中表达式调用
{
this.renderFoo(47)
}After:
<With foo={ 47 }>
<span>{ foo }</span>
</With> 使用这几种标签优化代码,可以减少 JSX 中存在的显式 JavaScript 表达式,使我们的代码看上去更简洁,但是这些标签封装的能力,在编译时需要转换为等价的 JavaScript 表达式。
总结
以上就是一些常见的逻辑判断优化技巧总结。当然,编写高质量可维护的代码,除了逻辑判断优化,还需要有清晰的注释、含义明确的变量命名、合理的代码结构拆分、逻辑分层解耦、以及更高层次的贴合业务的逻辑抽象等等,相信各位在这方面也有自己的一些心得。