这是一篇简短的文章,描述了描述了linux内核的首选代码风格。目的是为了分享,作为一名linux内核或者驱动开发工程师,很有必要了解这些内核开发规范。
- 这些约定或者规范对我们阅读
linux内核源码、了解设计思路有很大帮助。
- 我们基于
linux内核做开发,也要往内核里添加代码,遵守开发规范,有助于别人阅读和理解我们的代码。
linux内核代码规范约定如下:
1.强烈推荐单行的宽度为八十列。
任何一行超过八十列宽度的语句都应该拆分成多个行,除非超过八十列的部分可以提高可读性且不会隐藏信息。但是,千万不要把用户可见的字符串,比如 printk 的信息,拆分成多行,因为这样会导致使用 grep 的时候找不到这些信息。
2.关于大括号
c语言里的if,do, while, for语句都会使用到大括号,内核代码倾向于把左括号放在行末,把右括号放在行首,并且大括号和前面的语句,以及if和后面的语句,都保留一个空格,例如:
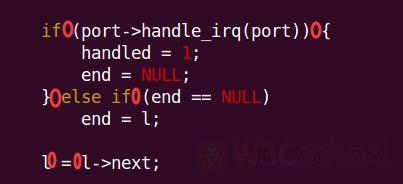
以上红圈标注都代表一个空格。
3.关于空格
这个还是单独列出来说明一下吧,因为内核代码里用到空格的地方太多了。
Linux 内核风格的空格主要用在一些关键字上,即在关键字之后添一个空格。值得关注的例外是一些长得像函数的关键字,比如:sizeof, typeof, alignof, attribute,在 Linux 中,这些关键字的使用都会带上一对括号,比如sizeof(int)。
所以在下面这些关键字后面需要添加一个空格:
if, switch, case, for, do, while
但是, sizeof, typeof, alignof, attribute 之后则不需要添加空格:
s = sizeof(struct file);
在声明指针或者返回值为指针的函数时,星号的位置应该紧靠着变量名或函数名,而不是类型名,例如:
char linux_banner; unsigned long long memparse(char ptr, char *retptr); char match_strdup(substring_t *s);
在二元操作符和三元操作符周围添加一个空格,例如:
= + – < > * / % | & ^ <= >= == != ? :
但是不要在一元操作符之后添加空格:
& * + – ~ ! sizeof typeof alignof attribute defined
4.变量命名
C 是一种简洁粗旷的语言,因此,你的命名也应该是简洁的。linux内核里的变量定义应该尽可能简单,在不产生歧义的情况下,越简单越好。可以用下划线,但是绝对不推荐使用大写字母。所以,内核里的变量和函数定义不要使用驼峰命名法。
5.函数
函数应该短小精悍,一个函数只干一件事。几百行代码组成一个函数是不被推荐的。
关键函数的前面最好留有注释。这样其他人可以快速看懂你的代码意图:
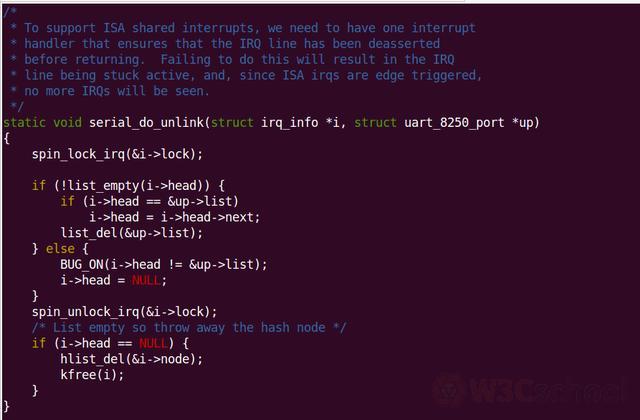
6.注释
多行注释推荐格式如下:
/*
- To support ISA shared interrupts, we need to have one interrupt
- handler that ensures that the IRQ line has been deasserted
- before returning. Failing to do this will result in the IRQ
- line being stuck active, and, since ISA irqs are edge triggered,
- no more IRQs will be seen. */
7.推荐使用函数自注释
所谓函数自注释,就是从你的函数名就可以猜到你要干什么,比如内核的:
wait_event(), wait_event_interruptible(), wait_event_interruptible_timeout()等。

注意,写代码不只是写给现在的自己,也是写给以后的自己,也是写给其他人看的。如果你回看你一年前写的代码都很陌生,那说明你的代码规范是有问题的。
8.常量宏和枚举的命名都是大写的:

9.打印内核或者驱动信息
编写好的调试信息是一项巨大的挑战,一旦你完成了,这些信息会对远程调试产生巨大帮助
很多子系统在对应的 makefile 里都有 Kconfig 调试选项来打开 -DDEBUG,或者是在文件里定义宏 #define DEBUG。当调试信息可以被无条件打印,或者说已经编译了和调试有关的 #ifdef 段,那么 printk(KERN_DEBUG …) 就可以用来打印调试信息。
10.内联函数(inline)
Inline关键字会让编译器将指定的函数体插入并取代每一处调用该函数的地方(上下文),从而节省了每次调用函数带来的额外时间开支。然而,inline 关键字的泛滥,会使内核变大,从而使整个系统运行速度变慢,因为大内核会占用更多的CPU高速缓存,同时会导致可用内存页缓存减少。想象一下,一次页缓存未命中就会导致一次磁盘寻址,这至少耗费5毫秒。5毫秒足够CPU运行很多很多的指令。
好了,以上就是我们在阅读linux内核源码的时候的一些代码规范的约定。linux源码作为世界上最规范、最严谨的代码,确实有很多值得我们学习的地方。有时候欣赏内核代码的时候总有一种赏心悦目的感觉,这可能跟它们的良好的代码规范有关系吧。 希望这个对大家有所帮助,然后对Linux感兴趣的同学可以看一下教程
Linux教程:https://www.w3cschool.cn/linux/
Linux微课:https://www.w3cschool.cn/minicourse/play/linuxcourse
Linux就该这么学:https://www.w3cschool.cn/linuxprobe/