这是一篇关于CSS基础跟选择器的笔记,毕竟自己的记性没有笔记本好用,所以记录一下,以后忘了也好有地方翻一下,复习重温。
CSS介绍
我们可以使用HTML构建稳定的结构基础,而页面的风格样式控制则交给CSS来完成。网页的样式包括各种元素的颜色、大小、线形、间距等等,这对于设计或维护一个数据较多的网站来说,工作量是巨大的。好在可以使用CSS来控制这些样式,这将大大提高网页设计和维护的效率,并且使网页的整体风格很容易做到统一。
CSS概述
CSS是英文Cascading Style Sheet的缩写,中文译为层叠样式表,也有人翻译为级联样式表,简称样式表。它是一种用来定义网页外观样式的技术,在网页中引入CSS规则,可以快捷高效地对页面进行布局设计,可以精确的控制HTML标记对象的宽度、高度、位置、字体、背景等外观效果。 CSS是一种标识性语言,不仅可以有效的控制网页的样式,更重要的是实现了网页内容与样式的分离,并允许将CSS规则单独存放于一个文档中, CSS文件的扩展名为“css”。
CSS3
CSS3标准早在1995年就开始制订, 2001年提上W3C研究议程,但是,10年来CSS3可以说是基本上没有什么很大的变化,一直到2011年6月才发布了全新版本的CSS3,目前,许多浏览器都广泛支持CSS3。 CSS3是CSS技术的一个升级版本,CSS3语言将CSS划分为更小的模块,在朝着模块化的方向发展。以前的版本是一个比较庞大而且比较复杂模块,所以,把它分解成为一个个小的简单的模块,同时也加入了更多新的模块。在CSS3中有字体、颜色、布局、背景、定位、边框、多列、动画、用户界面等等多个模块。
CSS的基本用法
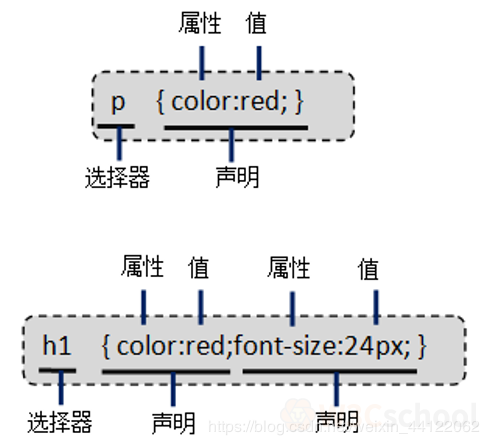
CSS的使用规则由两部分组成:选择器和一条或多条声明。其基本基本语法如下:
选择器{
属性1: 值;
属性2: 值;
…
属性n: 值;
} 
CSS属性
CSS的属性按照相关功能进行了分组,包含了字体、文本、背景、列表、动画等多个分组,这些属性的具体使用方法和示例将会在后续中提到。
在HTML文档中使用CSS的方法
根据CSS在HTML文档中的使用方法和作用范围不同,CSS样式表的使用方法分为三大类:行内样式、内部样式表和外部样式表,而外部样式表又可分为链入外部样式表和导入外部样式表。本节我们从四个分类来认识在HTML中使用CSS的方法。
- 行内样式
- 内部样式表
- 外部样式表
- 链入外部样式表
- 导入外部样式表
行内样式
行内样式(inline style),也叫内联样式,它是CSS四种使用方法中最为直接的一种,它的实现借用HTML元素的全局属性style,把CSS代码直接写入其中即可。 严格意义上行内样式是一种不严谨的使用方式,它不需要选择器,这种方式下CSS代码和HTML代码混合在一起,因此不推荐使用行内样式。行内样式的基本语法如下:
<标记 style="属性:值; 属性:值; …">内部样式表
当单个文档需要特殊的样式时,应该使用内部样式表。内部样式表是将样式放在页面的head区里,这样定义的样式就应用到本页面中了,内部样式表使用style标记进行声明,是较为常用的一种使用方法。其基本语法如下:
<head>
<meta charset="utf-8" />
<title></title>
<style type="text/css">
选择器1{属性:值;…}
选择器2{属性:值;…}
……
选择器n{属性:值;…}
</style>
</head> style标记定义HTML文档的样式信息,规定的是HTML元素如何在浏览器中呈现,其中type用来指定元素中的内容类型。
链入外部样式表
当为了保证站点的风格统一,或当定义样式内容较多,且需要多个页面共享样式时,可使用外部样式表。链入外部样式表是把样式表保存为一个外部样式表文件,然后在页面中用link标记链接到这个样式表文件,link标记放在页面的head区内。其基本语法为:
<head>
<meta charset="utf-8" />
<title></title>
<link href="样式表路径" rel="stylesheet" type="text/css" />
</head>其中:
href:指出样式表存放的路径。
rel:用来定义链接的文件与HTML之间的关系,rel="stylesheet"是指在页面中使用这个外部的样式表。
type属性用于指定文件类型,“text/css”指文件的类型是样式表文本。
导入外部样式表
导入外部样式表是指在HTML文件头部的style元素里导入一个外部样式表,导入外部样式表采用import方式。导入外部样式表和链入样式表的方法很相似,但导入外部样式表的样式实质上相当于存在网页内部。其基本语法为:
<head>
<meta charset="utf-8" />
<title></title>
<style type="text/css">
@import url("样式表路径");
</style>
</head>CSS基本选择器
选择器是CSS中很重要的概念,它可以大幅度提高开发人员编写或修改样式表的工作效率。CSS3提供了大量的选择器,大体上可以分为基本选择器、组合选择器、属性选择器、伪类选择器和伪对象选择器等。由于浏览器支持情况,很多选择器在实际开发中很少用到,本篇主要记录最基本又最常用的几种选择器。 基本选择器包括标记选择器、类选择器、id选择器和通用选择器。
标记选择器
HTML文档中最基本的构成是HTML标记,如果要对文档中的所有同类标记都使用同一个CSS样式时,就应使用标记选择器。其基本语法为:
标记名{ 属性1:值1; 属性2:值2;…} 例如要使所有P标签的文本居中时,语法如下:
p{
text-align: center;
}类选择器
类选择器的基本语法为:
标记名.类名{属性1:值1;属性2:值2;…} 类选择器针对标记的全局属性class,引用方式为:
<标记名 class="类名"> 值得注意的是,这里的类名可以是任何合法的字符,由设计者定义。如果对所有的标记均可使用,则采用*.类名的形式,这里的*表示全部,当然,也可以省略。
下面举几个例子:
<style type="text/css">
p.text1{color:brown;font-size:14px;}
/* 该形式下只允许<p>标记中类名为"text1"的标签引用该样式 */
*.text1{ color:brown;font-size:14px; }
或
.text1{ color:brown;font-size:14px; }
/* 表示所有类名为"text1"的标签都可引用该样式 */
</style>id选择器
id选择器和类选择器大致相同,不同的是定义时不使用“.”而使用“#”,作用于HTML标记的全局属性是“id”而不是“class”。 id选择器的基本语法为:
标记名#id名{ 属性1: 值1;属性2: 值2;…} id选择器针对标记的全局属性id,引用方式为:
<标记名 id="id名"> 当然,与类选择器一样,如果对所有的标记均使用时,则采用*#id名的形式,这里*表示全部,也可以省略。
通用选择器
通用选择器是一种特殊的选择器,用 * 表示,匹配网页中的所有元素,除非使用更为具体的选择器指定某一元素中对应的相同属性应使用其它值。通用选择器和对body元素设定样式稍有不同,因为通用选择器应用于每一个元素,而不依赖从应用于body元素的规则中继承的属性。其基本用法如下:
<style type="text/css">
*{
属性1: 值1;
属性2: 值2;
…
}
</style>其它CSS选择器
除了CSS基本选择器外,CSS还有许多其它选择器。
组合选择器
CSS中组合选择器,可以算作是基础选择器的升级版,也就是组合去使用基础选择器的意思。组合选择器主要有五个类别:多元素选择器、后代选择器、子选择器、相邻选择器和兄弟选择器。

多元素选择器
多元素选择器的基本语法为:
E, F {属性1:值1;属性2:值2;… } 这个很好理解,就是同时选中多个元素,中间用“,”隔开。
后代元素选择器
后代元素选择器的基本语法为:
E F {属性1:值1;属性2:值2;… } 这个也很好理解,就是匹配所有属于E元素后代的F元素,E元素与F元素用空格隔开,例如:
table b{color:red; } 就表示将表格中的所有b元素文字设置为红色。
子元素选择器
子元素选择器的基本语法为:
E>F{属性1:值1;属性2:值2;…}子元素选择器只能选择某元素的子元素,其中E为父元素,F为直接子元素,E>F所表示的是选择了E元素下的所有子元素F,其间用>连接。这和后代元素选择器不一样,在后代元素选择器中F是E的所有后代元素,而子元素选择器中F必须是E的子元素。
相邻兄弟选择器
相邻兄弟选择器的基本语法为:
E+F{属性1:值1;属性2:值2;…}相邻兄弟选择器可以选择紧接在另一元素后的元素,而且它们具有相同的父元素,其间用+号链接,换句话说,E和F具有同一个父元素,而且F元素在E元素后面并且紧紧相邻。
一般兄弟选择器
一般兄弟选择器的基本语法为:
E~F{属性1:值1;属性2: 值2;…}一般兄弟选择器将选择某元素后面的所有兄弟元素,其间用~号链接,它和相邻兄弟选择器类似,需要在同一个父元素之中,并且F元素在E元素之后。区别在于E ~ F 选择器匹配所有E元素后面的F元素,E+F仅匹配紧跟在E元素后边的F元素。
属性选择器
属性选择器是在标记后面加一个中括号,中括号中列出各种属性或者表达式。属性选择器的形式很多,我们这里通过示例简单介绍几个。
存在属性匹配
通过匹配存在的属性来控制元素的样式,一般要把匹配的属性包含在中括号中。 例如将任何带有href属性的a标记设置为综色:
a[href]{color:brown;} 精确属性匹配 只有当属性值完全匹配指定的属性值时才会应用样式,id选择器和类选择器本质上就是精确属性匹配选择器。 例如将指向网址“http://www.w3cschool.cn” 的链接a标记设置为棕色:
a[href="http://www.w3cschool.cn"]{color:brown;}前缀匹配
只要属性值的开始字符串匹配指定字符串,即可对元素应用样式。前缀匹配使用[^=]形式实现,如:
[id^="user"]{color:brown;}那么下列的标签均可以变为棕色:
<p id="userName">小明</p>
<p id="userWeight">体重</p>
<p id="userAge">年龄</p>后缀匹配
与前缀匹配相反,只要属性值的结尾字符匹串配指定字符串,即可对元素应用样式。后缀匹配使用[$=]形式实现,如:
[id$="Name"]{color:brown;}那么下列的标签均可以变为棕色:
<p id="JackName">杰克</p>
<p id="RoseName">萝丝</p> 子字符串匹配
只要属性中存在指定字符串即应用样式,使用[*=]形式实现,如:
[id*="test"]{color:brown;}那么下列的标签均可以变为棕色:
<p id="Rosetest">段落1</p>
<p id="testY">段落2</p>
<p id="xtesty">段落3</p> 以上就是CSS的学习笔记了,希望对大家有所帮助。然后对CSS感兴趣的同学可以看一下教程: