文章转载自公众号:程序新视界
本篇文章基于字符串常量池的存储及在使用 intern方法 时所引起的内存变化进行一步深层次的讲解。
重点内容:当字符串调用 intern方法 方法后,再进行字符串的比较,会发生什么变化?
本文内容均以HotSpot虚拟机为基础讲解。
面试题
先通过一个面试题形象的了解一下我们本篇文章要讲的内容的呈现形式:
String s1 = new String("he") + new String("llo");
String s2 = new String("h") + new String("ello");
String s3 = s1.intern();
String s4 = s2.intern();
System.out.println(s1 == s3);
System.out.println(s1 == s4); 执行上面的代码,会发现打印的结果都是 true 。那么,为什么本来不相等的字符串,调用了intern方法之后便相等了呢?下面我们就来逐步分析这其中的底层实现。
intern方法的作用
intern()方法的功能定义:
(1)如果当前字符串内容存在于字符串常量池(即equals()方法为true,也就是内容一样),那直接返回此字符串在常量池的引用;
(2)如果当前字符串不在字符串常量池中,那么在常量池创建一个引用并指向堆中已存在的字符串,然后返回常量池中的引用。
简单说intern方法就是判断并将字符串是否存在于字符串常量池,如果不存在则创建,存在则返回。
字符串常量池
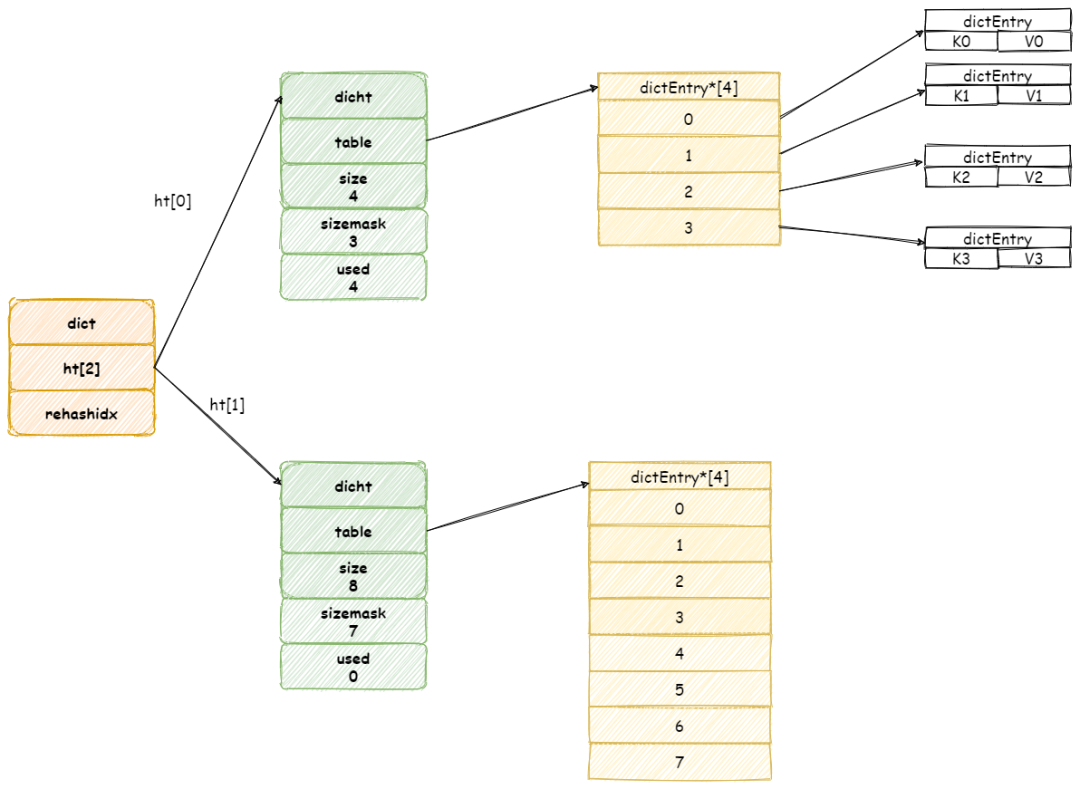
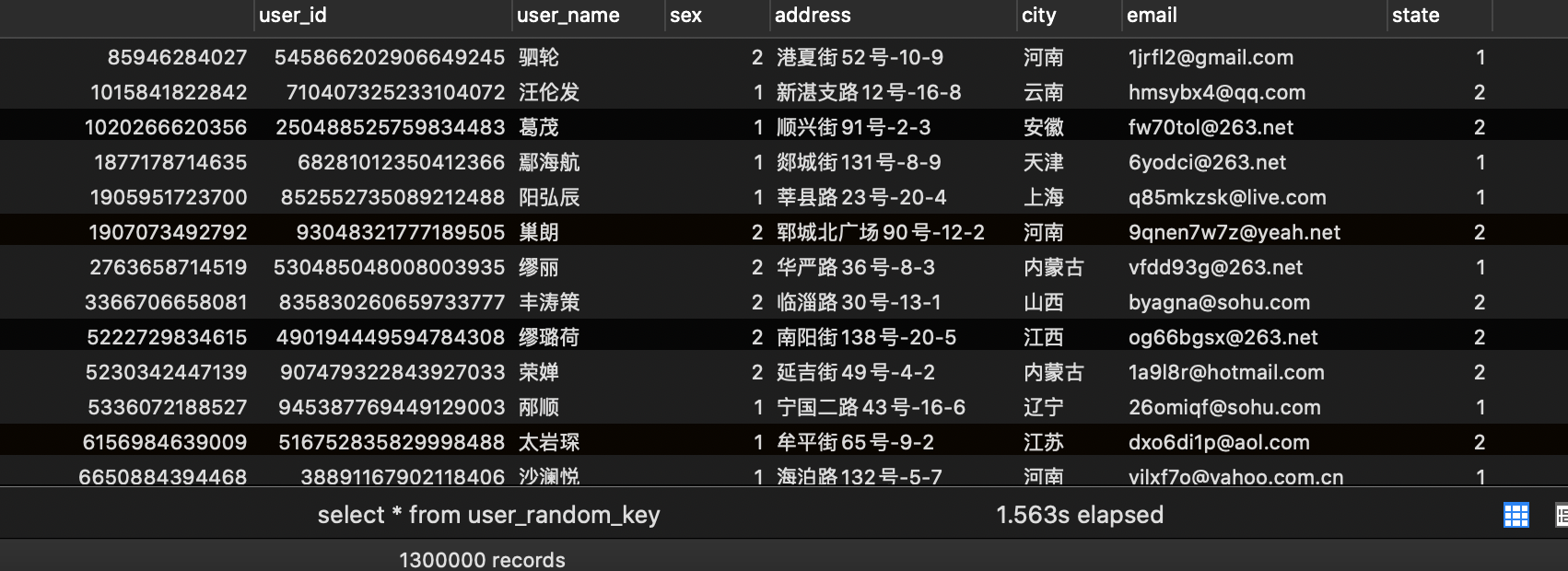
在HotSpot中实现字符串常量池功能的是一个StringTable类,它是一个Hash表,默认值大小长度是1009。在每个HotSpot虚拟机的实例中只有一份,被所有的类共享。字符串常量由一个个字符组成,放在了StringTable上。
JDK6及之前版本,字符串常量池是放在Perm Gen区(方法区)中。StringTable的长度是固定的,长度是1009,当String字符串过多时会造成hash冲突,导致链表过长,性能大幅度下降。此时字符串常量池里面放的全部是字符串常量(字面值)。
由于永久代的空间有限且固定,JDK6的存储模式很容易造成OutOfMemoryError。
而JDK7时正在着手去永久代的工作,因此字符串常量池被放在了堆中。此时,即使堆的大小也是固定的,但对于应用调优工作,只需要调整堆大小就行了。
在JDK7中字符串常量池不仅仅可以存放字符串常量,还可以存放字符串的引用。也就是说,堆中的字符串的引用可以作为常量池的值而存在。
字符串池化流程分析
在了解了上面的基础理论,我们下面以图文相结合的形式来逐步演示字符串池化的流程和分类。以下实例以JDK8版本为基础来进行分析讲解。
当我们通过双引号声明一个字符串:
String wechat = "程序新视界";此时,双引号内的字符串会被直接存储在字符串常量池中。
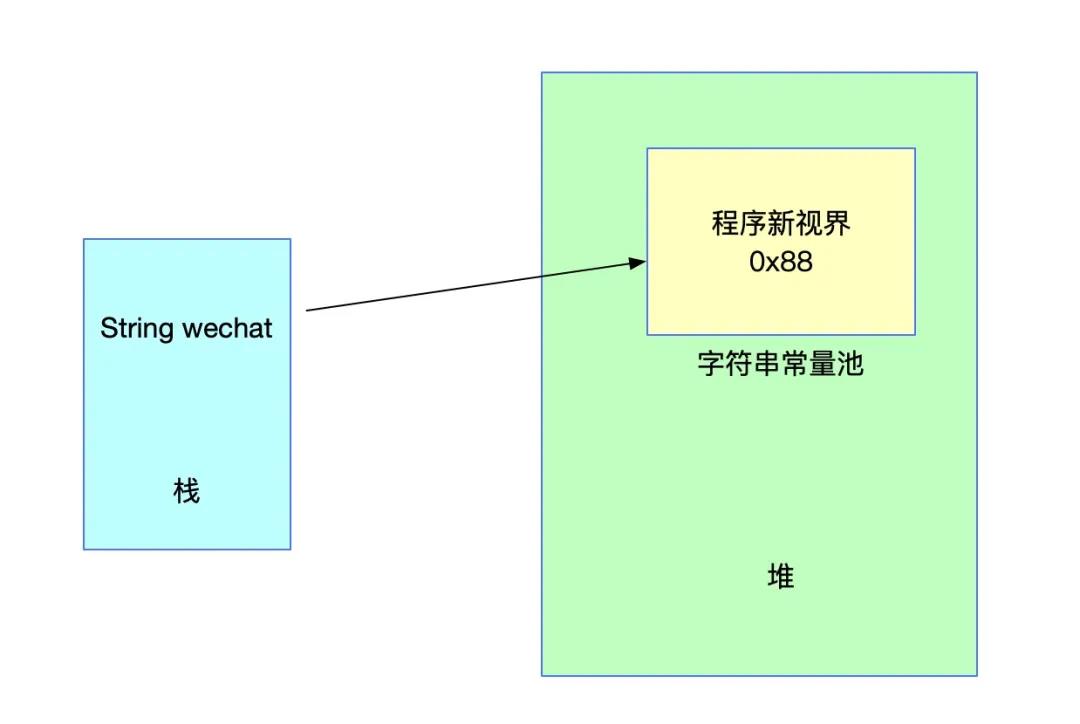
关于上面的存储结构,我们已经在之前文章中提到,不再过多解释。下面如果我们再声明同样的字符串看看会有什么样的变化。
String wechat = "程序新视界";
String wechat1 = "程序新视界"; 上述代码中声明wechat1时,会发现常量池中已经存在了对应的字符串,则不会再重新创建,只是把对应的引用返回给wechat1。对应结构图如下:
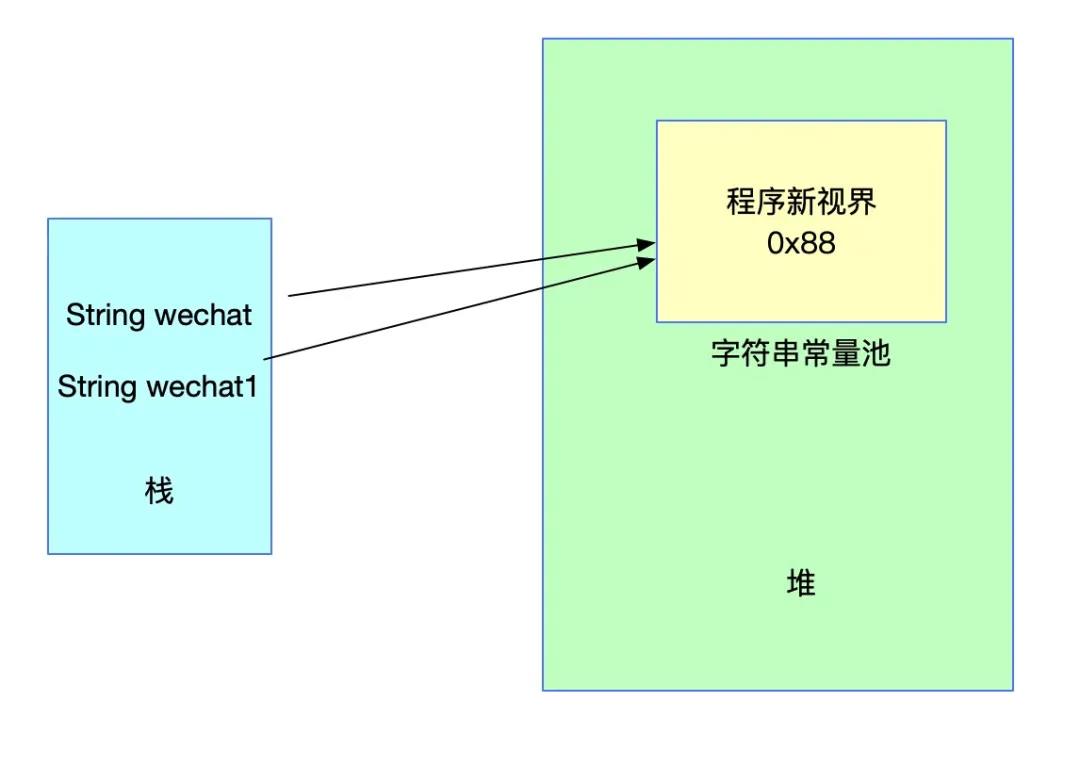
此时,如果直接用双等号比较wechat和wechat1肯定是相等的,因为它们的引用和字面值都是相同的。
上面是直接双引号赋值的情况,那么如果通过 new 的形式创建字符串对应的流程又是如何呢?前面文章已经讲到这分两种情况:常量池存在对应的值和不存在对应的值。
String wechat2 = new String("程序新视界"); 如果存在对应的值,此时会先在堆中创建一个针对wechat2变量的对象引用,然后将这个对象引用指向字符串常量池中已经存在的常量。
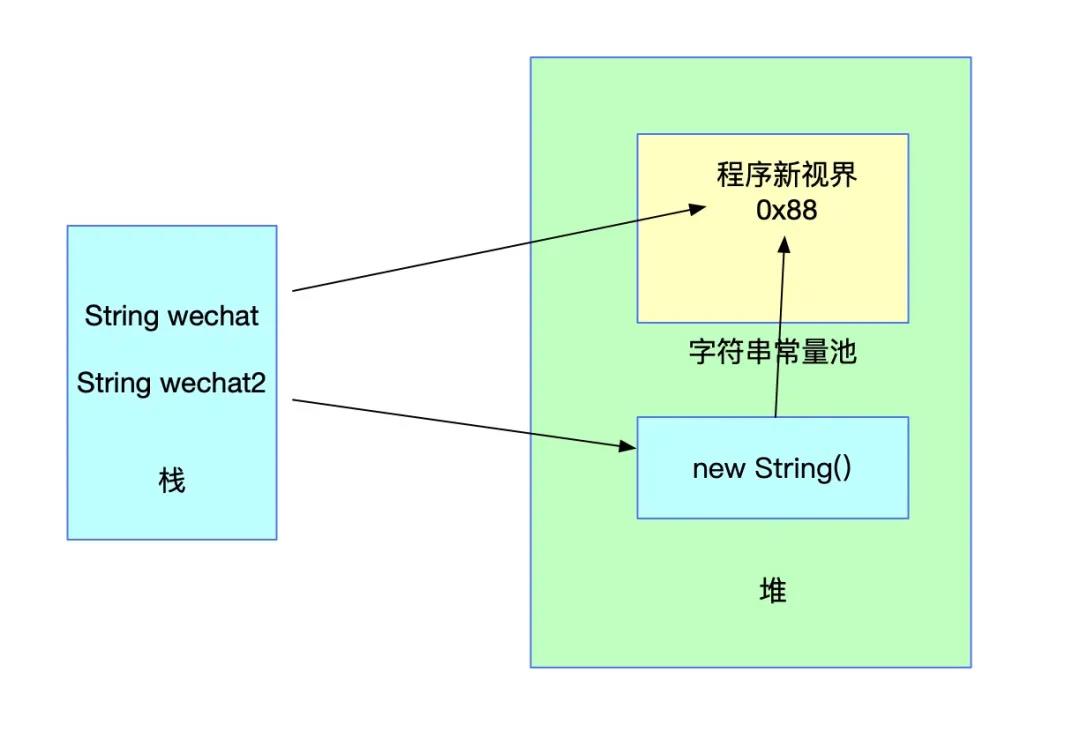
此时直接使用双等号比较wechat和wechat2变量肯定是不相等的,而通过equals方法进行对比字面值则是相等的。
另外一种情况就是通过 new 创建时,字符串常量池中并不存在对应的常量。这种情况会现在字符串常量池中创建一个字符串常量,然后再在堆中创建一个字符串,持有常量池中对应字符串的引用。并把堆中对象的地址返回给wechat2。最终效果图依旧如上图。
在此时,如果不是直接new字符串赋值,而是通过+号操作,情况就有所不同。
String s1 = "程序";
String wechat3 = new String(s1 + "新视界"); 上述代码 s1 会存入常量池,而wechat3的值则由于JVM编译时采用了StringBuilder进行加号的拼接,只会在堆中创建一个String对象,并不会在常量池中存储对应的字符串。
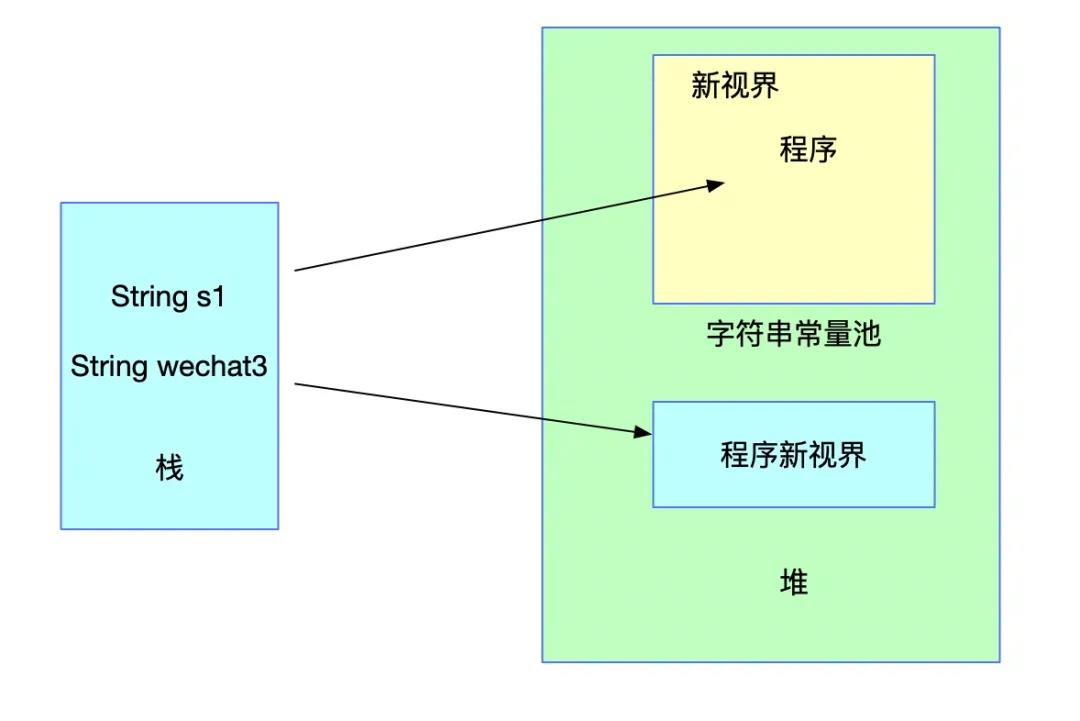
此时的情况已经涉及到我们面试题中创建字符串的情况了。那么,下面我们就通过intern方法进行池化操作,看看字符串常量池的具体变化。
还以上面的代码为例,此时wechat、wechat1、wechat2三个变量和wechat3直接用双等号比较肯定是不相等的。下面对wechat3进行intern池化处理。
String s1 = "程序";
String wechat3 = new String(s1 + "新视界");
wechat3 = wechat3.intern(); 此时会发现wechat、wechat1两个变量与wechat3的值相等了。由于wechat和wechat1其实是一个,这里只以wechat和wechat3的比较为例来分析一下这个流程。
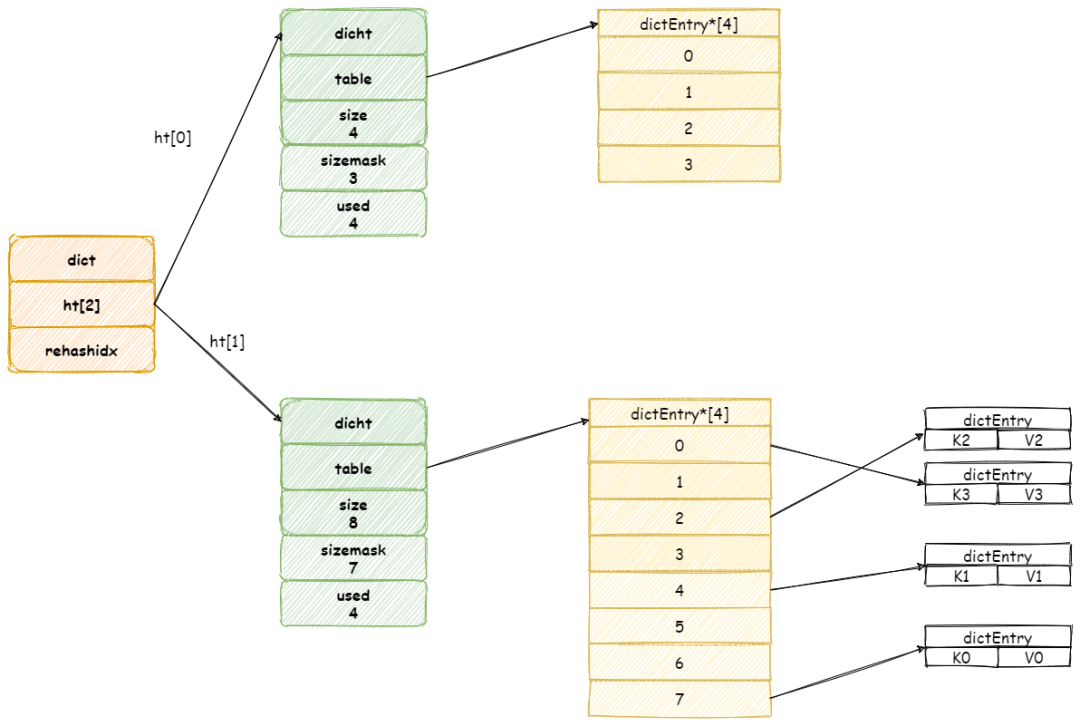
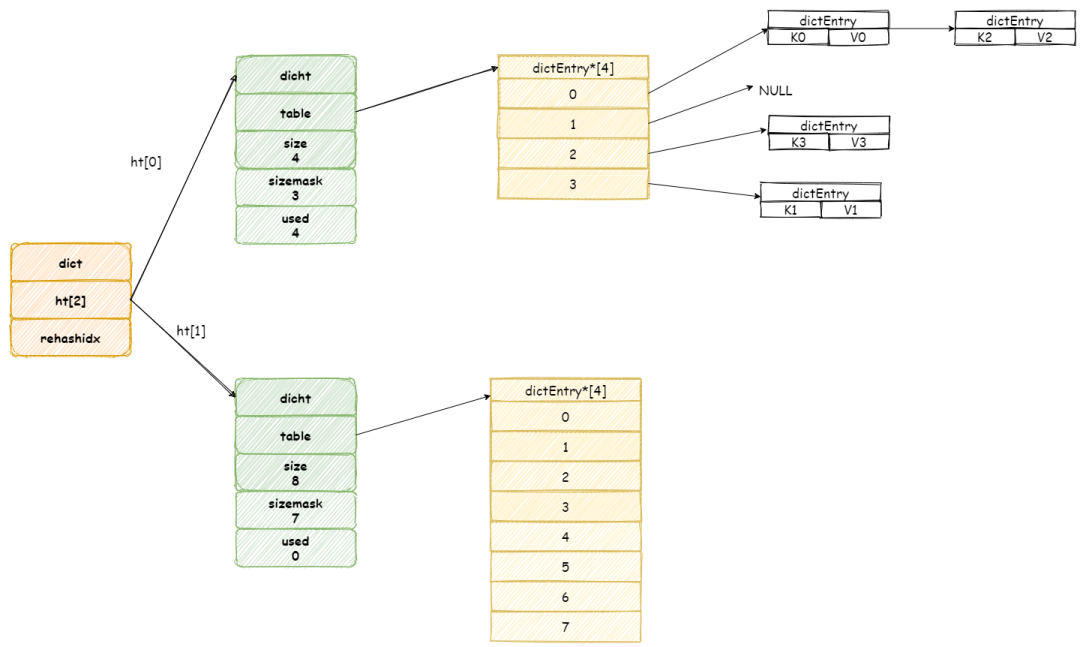
在没有调用intern方法之前内存的状态是下图(忽略掉s1部分)这样的:
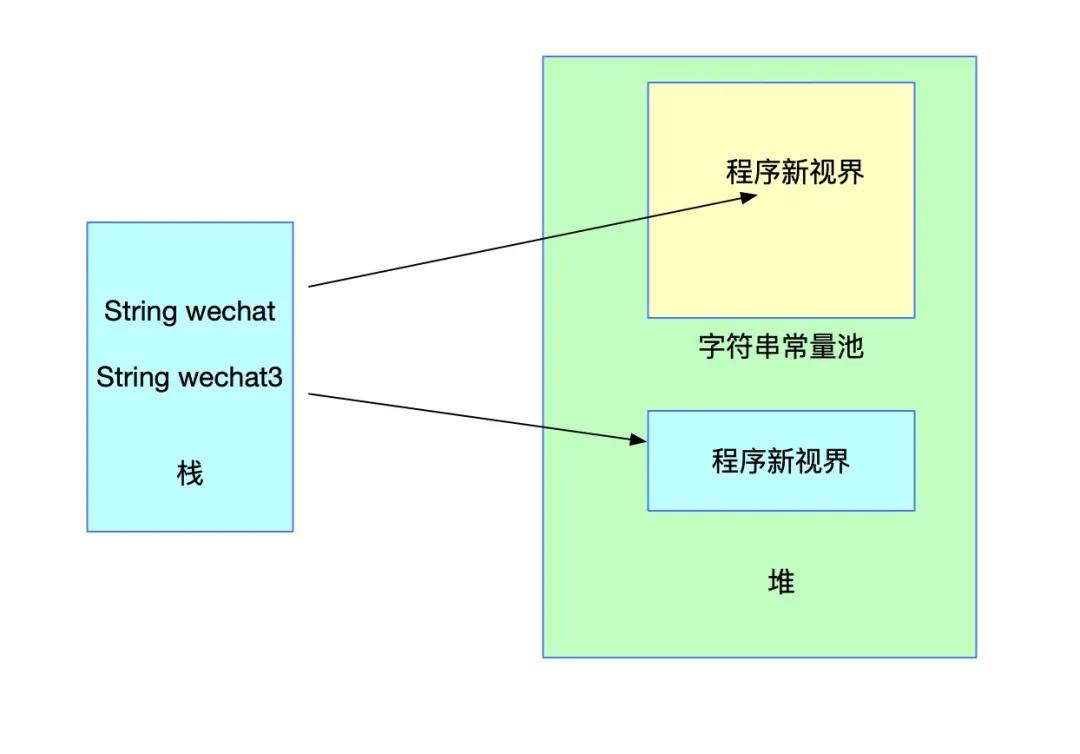
看上图它们的值不相等也就不奇怪了。下面对wechat3进行池化处理,并把池化的结果赋值给wechat3,就是上面的代码。内存结构会发生如下变化:
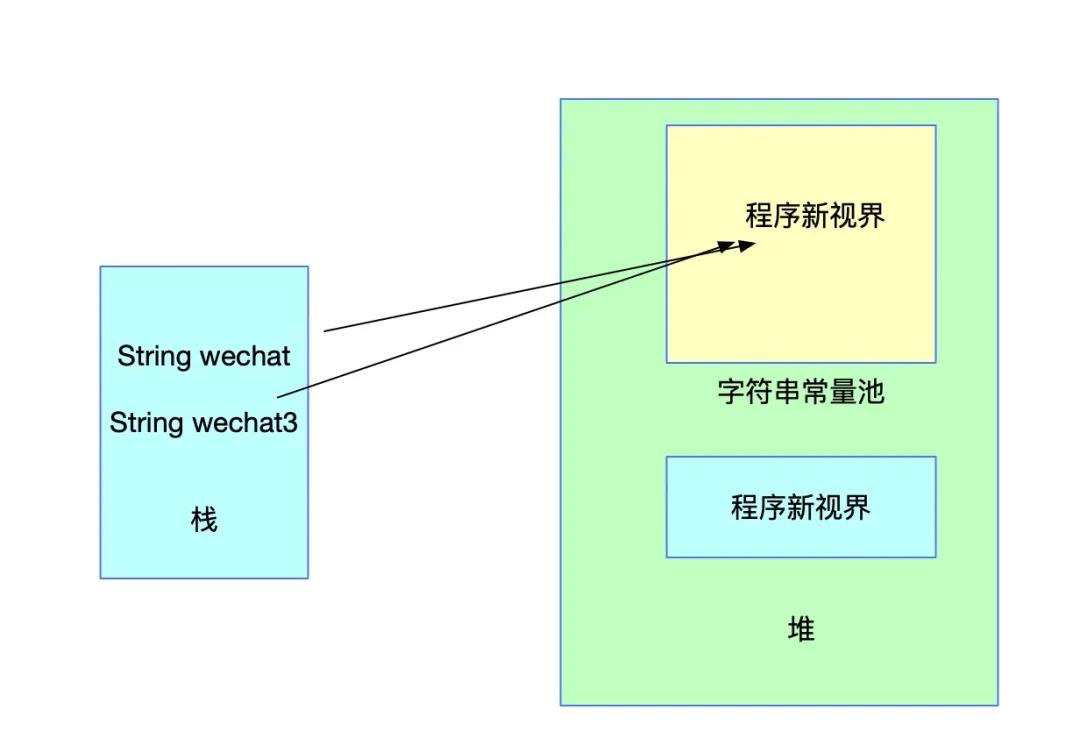
此时,再判断对应的两个值,因为引用和字面值全部相同,因此便相等了。具体intern的判断规则我们上面已经知道,如果常量池中存在对应的值,则直接返回引用。
那还有另外一种情况,就是常量池中不存在对应的值会是如何处理的呢?先看如下代码:
String s2 = "关注";
String wechat4 = new String(s2 + "公众号");
wechat4 = wechat4.intern();在调用intern之前的操作我们前面已经说过,会在堆中创建一个String对象,而常量池中并不会存储一份,与wechat3的图一样。
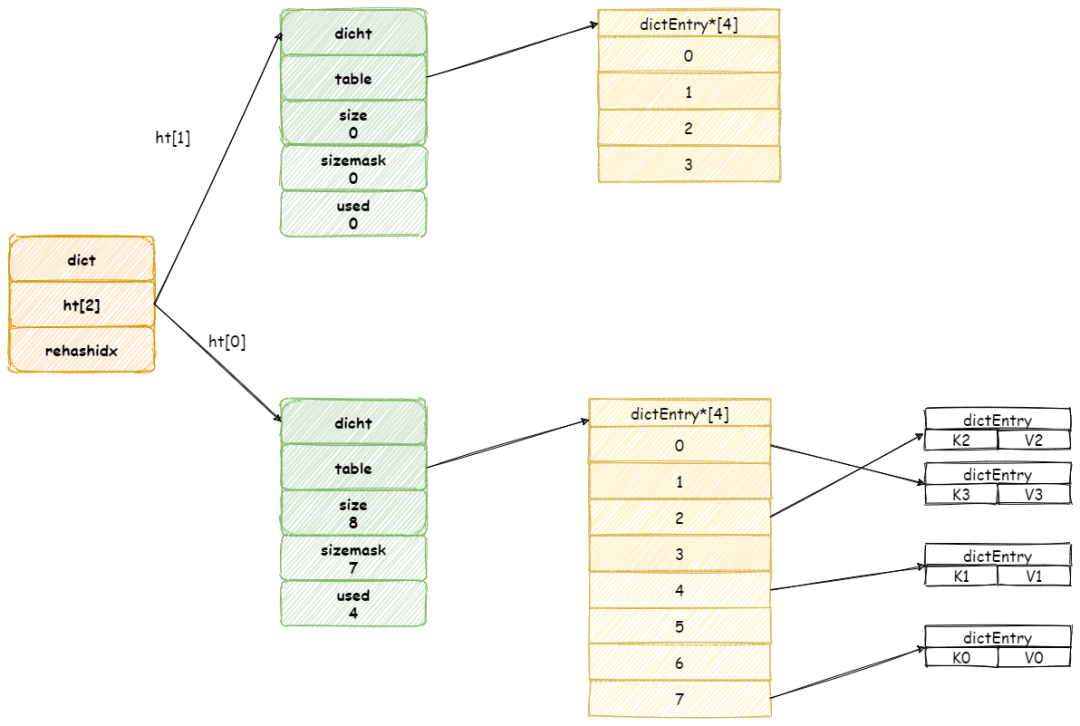
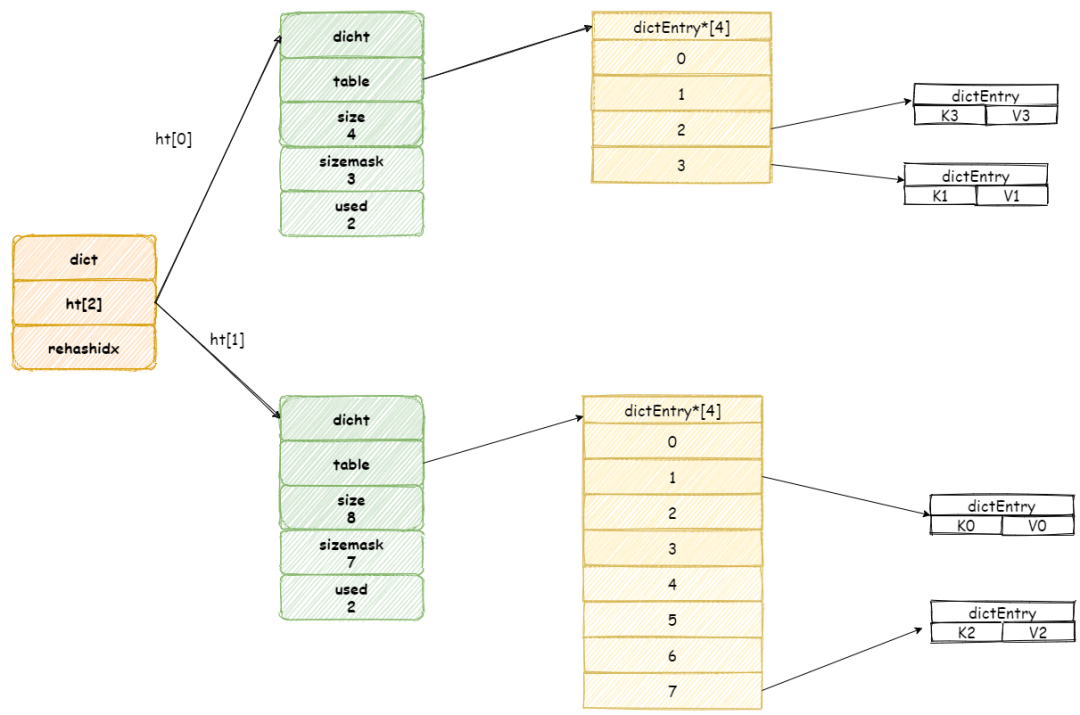
此时常量池中并未存在对应的字符串,此时调用intern方法之后,内存结构如下:
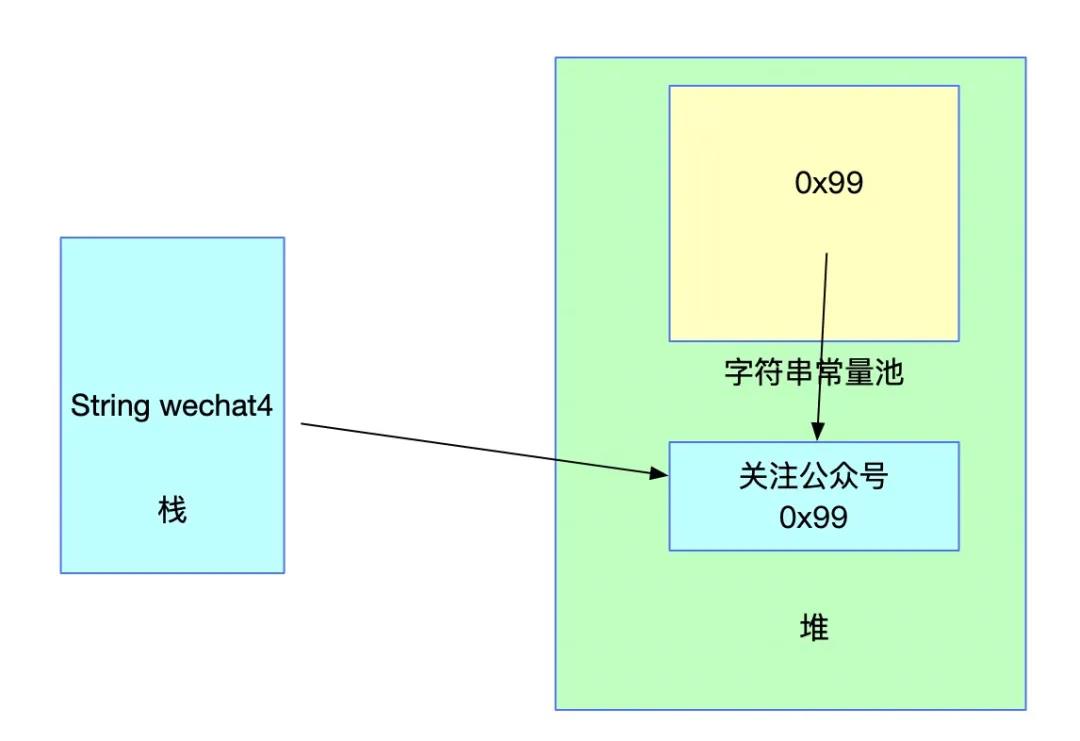
经intern方法之后,常量池中存了堆中对应字符串的引用。对照上面说的,JDK7及之后字符串常量池中可以存储引用了。
需要注意的是,当字符串常量池中并不存在对应字符串时,调用intern方法返回的地址为堆中的地址,对应图中的0x99。而wechat4本来地址指向的就是堆中的地址,因此不会发生变化。
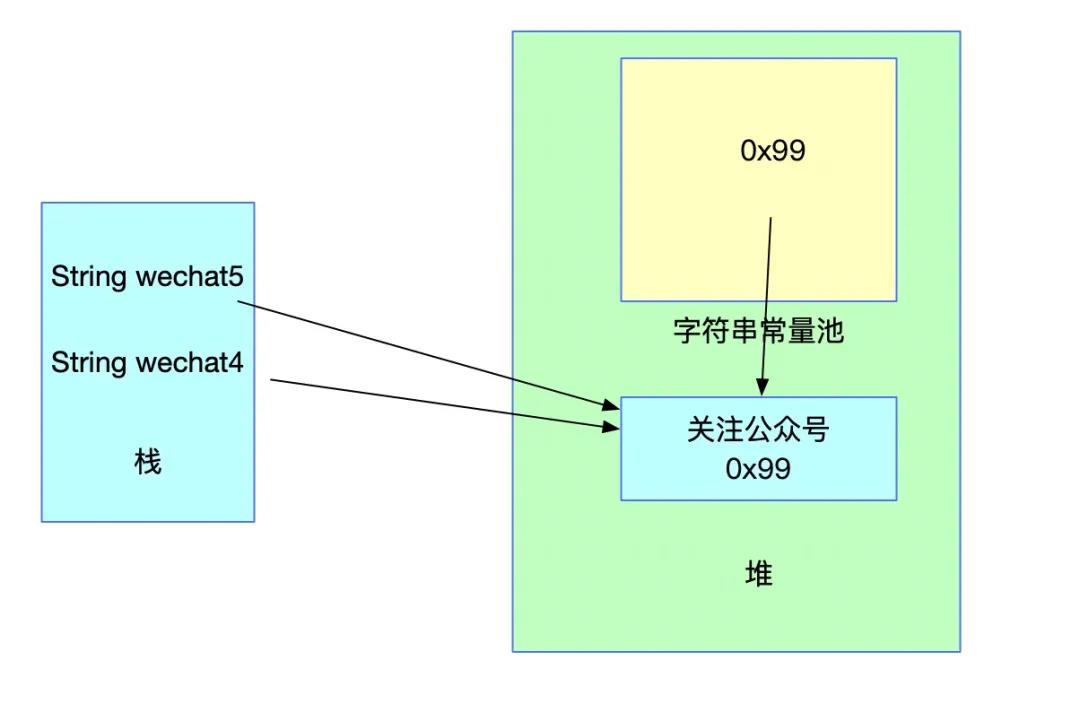
此时如果再定义一个双引号赋值的wechat5,如下代码:
String s2 = "关注";
String wechat4 = new String(s2 + "公众号");
wechat4 = wechat4.intern();
String wechat5 = "关注公众号";
System.out.println(wechat4 == wechat5); 变量wechat5初始化时发现字符串常量池中已经存在了一个引用,那么wechat5会直接指向这个引用,也就是wechat5和wechat4一样,都指向内存中的String对象。
小结
上面这个演示实例时需要注意的重点是intern方法返回的引用地址。如果字符串常量池中已经存在对应的字符串时,此时返回的是字符串常量的地址【常量池中存储的是字符串】,如果字符串常量池中不存在对应的字符串,此时会把堆中的引用放在常量池对应的位置【常量池中存储的是堆中字符串的引用】,此时intern返回的是堆中字符串对应的引用。
搞清楚了上面的返回逻辑再看最初的代码:
String s1 = new String("he") + new String("llo");
String s2 = new String("h") + new String("ello");
String s3 = s1.intern();
String s4 = s2.intern();
System.out.println(s1 == s3);
System.out.println(s1 == s4); 其中 s1 为堆中字符串“hello”的地址;s2 为堆中另外一个“hello”字符串的地址。当s1.intern(),常量池中存储了 s1 的地址,此时s1.intern()返回的也是 s1 的地址,因此s1=s3,都是同一个地址嘛。
然后执行s2.intern(),此时常量池中已经有 hello 字符串,类型为引用且指向 s1 的地址,执行之后返回的便是 s1 的地址,赋值给 s4 ,因此 s1 和 s4 也指向同一个地址,因此相等。
通过上面的更深层次的分析,想必大家对字符串常量、字符串常量池以及intern方法有了更加深刻的理解。相关的面试题如果按照这个思路分析,基本上都可以进行准确解答了。
以上就是W3Cschool编程狮关于JVM字符串常量池及String的intern方法详解?的相关介绍了,希望对大家有所帮助。