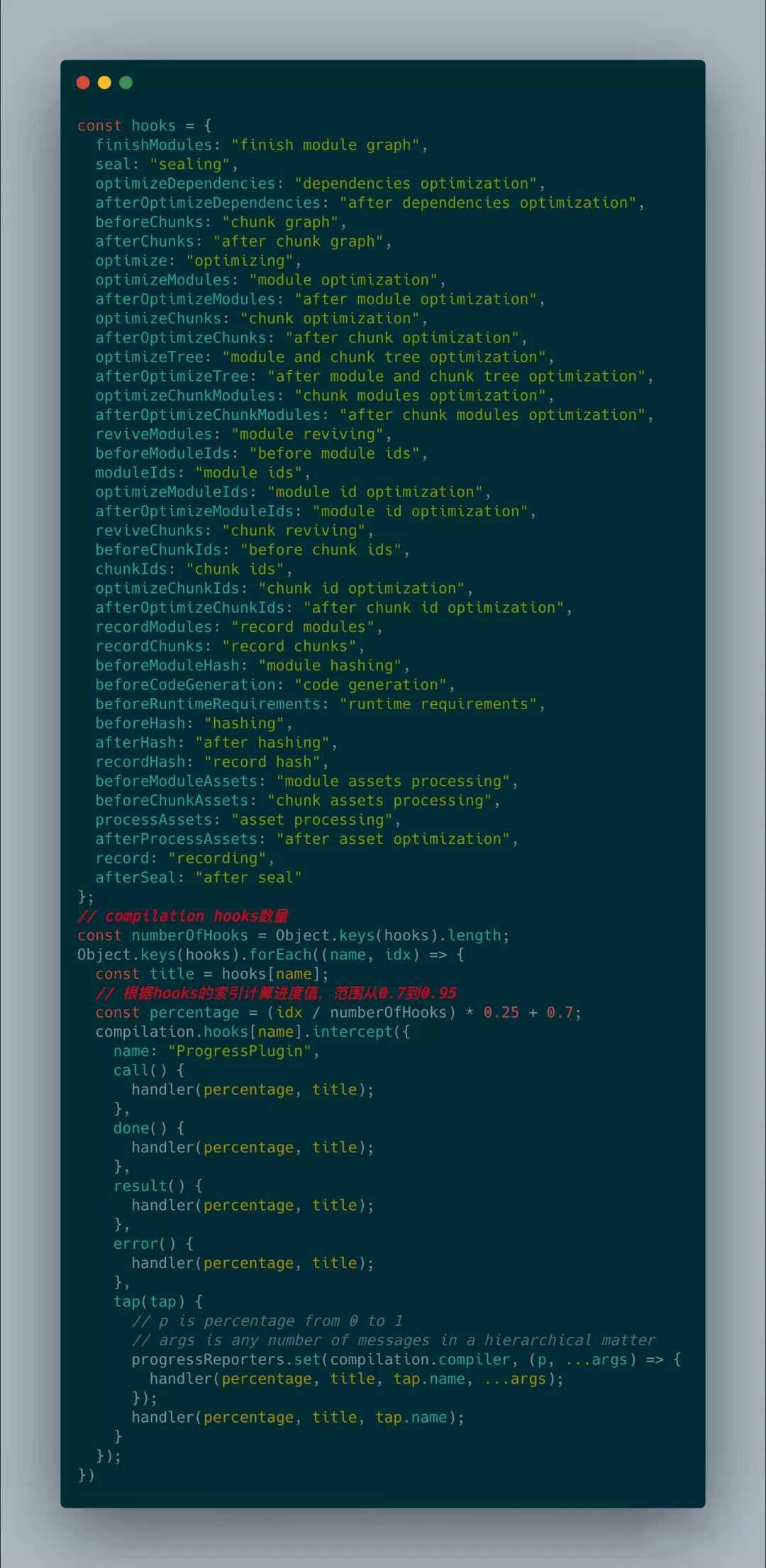
文章转载自公众号:小姐姐味道
目前HTTP协议,乃至WebSocket协议,乃至采用了MQTT协议的WebSocket协议,都不可避免的使用了 Nginx 。所谓病从口入,祸从口出。作为入口,Nginx 承担的责任非常的重要。假如某个时刻不能用了,那可真是灾难。
如何保证 Nginx 的高可用呢?这是个问题。不论你用什么样的方案,到最后总是要归为单一,很让人苦恼。
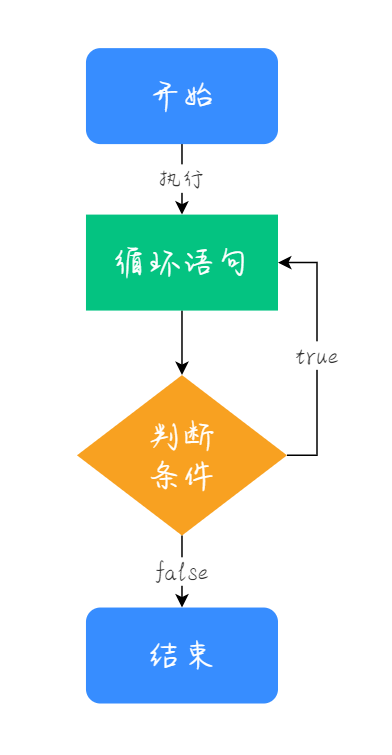
所谓的高可用,无非两种方式。一种方式就是在组件自身上做文章,另外一种方式,就是加入一个中间层。我们通常希望在高可用的时候,同时还能够负载均衡,典型的猫和狗都想要,贪婪的很。
每当解决不了问题的时候,我们都会加入一个中间层,然后把希望寄托在这个新生的组件上。
如果这个中间层解决不了问题,我们就可以加入另外一个中间层。就这样一层套一层,到最后系统高可用架构就会变得非常复杂。
DNS保证高可用
第一种方式当然是要在 DNS 上做文章了。通过在 DNS 上,绑定多个 Nginx 的 IP 地址,即可完成高可用。不仅能够完成高可用,还能顺便完成负载均衡。
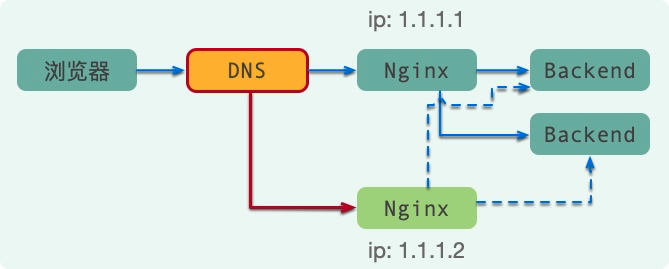
但这玩意有一个致命的问题,那就是故障的感知时间。
我们的浏览器在访问到真正的 Nginx 之前,需要把域名转化为真正的 IP 地址,DNS 就是干解析这个动作的,每次需要耗费20-20ms不等。
为了加快解析速度,一般都会有多级的缓存。比如浏览器就有 DNS 的缓存;你使用的 PC 机上也有这样的缓存;IPS 服务提供商,也会有缓存;再加上有的企业为了加速访问所自建的 DNS 服务器,中间的缓存层就更多了。
只有所有的缓存都不命中的情况下,DNS 才会查询真正的 IP 地址。所以,如果有一台 Nginx 当机了,这个故障的感知能力就会特别的差。总有一部分用户的请求,会落在这台已经死亡的机器上。
硬件保证高可用
我们前面说了。解决不了的问题,就可以加中间层,即使这个中间层是硬件,比如F5。
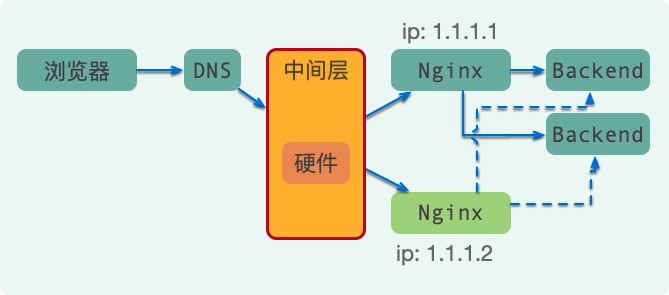
这种架构一般的企业玩不起,只有那些采购有回扣有油水的公司,才会喜欢这个。互联网中用的很少,就不过多介绍了。
当然,F5同样有单点的问题。虽然硬件肯定要比软件稳定上一点,但是总归是一个隐患。就像 Oracle 无论再厉害,它还是有出问题的时候,到时候备机是必须的。
有的厂商在卖硬件的时候,推荐你一次买3个!为啥呢?这也有理由。
你的一台硬件正在服务,有两台备份机器。当你服务的这台机器出现问题时,就可以选取备份机中的其中一台作为主机,另一台依然是备机,集群还是高可用的。
这理由真让人陶醉。按照这个逻辑,碰到傻子,我可以卖出100台!
主备模式
硬的不行,就要来软的。采用主备的模式,使用软件来完成切换过程。
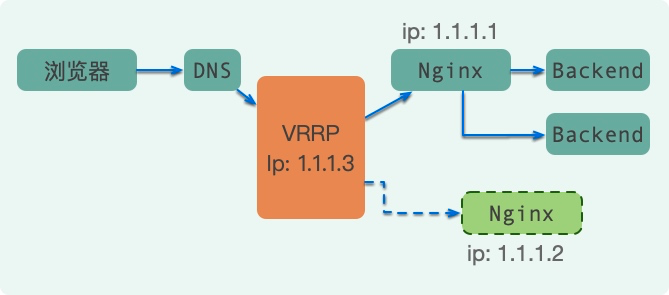
如图,使用keepalived组件,通过VRRP协议,即可完成最简单的高可用配置。
我们把DNS的地址绑定在VIP上,当正在服务的Nginx发生问题,VIP会发生漂移,转移到另外一台Nginx上。
可以看到,备份的Nginx,正常情况下是无法进行服务的,它也叫做影子节点,只有主Nginx发生问题的时候才有用。如果你的节点非常多,这种模式下,会有非常大的浪费。
除了浪费,还有一个非常大的问题。那就是,单台 Nginx 无论性能多么牛X,总是有上限的。当网卡的流量达到顶峰,接下来何去何从呢?
这种模式肯定是不满足需求的。
简单组合模式
这个时候,我们就可以配合 DNS 解析,以及主备模式做文章了。如下图,DNS 解析到两个 VIP 上,VIP 本身也做了高可用。这样就能够缩短故障时间,同时也能够保证每个组件的高可用。
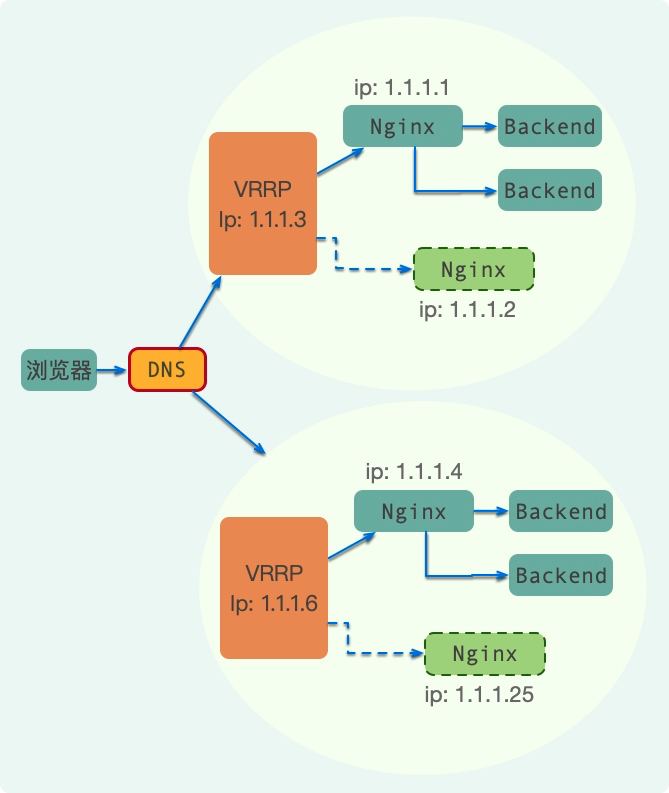
这种架构模式思路是非常清晰的,但依然存在影子节点的浪费。
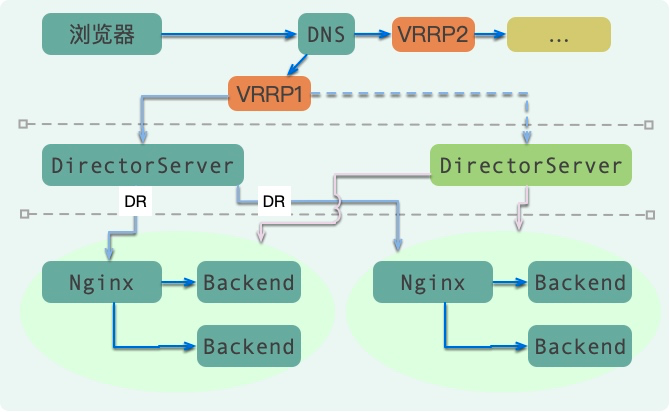
LVS+KeepAlived+Nginx
LVS 是 Linux Virtual Server 的简称,也就是 Linux 虚拟服务器。现在 LVS 已经是 Linux 标准内核的一部分,从 Linux2.4 内核以后,已经完全内置了 LVS 的各个功能模块,无需给内核打任何补丁,可以直接使用 LVS 提供的各种功能。

LVS 工作在 OSI 模型的第4层:传输层,比如 TCP/UDP,所以像7层网络的 HTTP 协议,它是识别不出来的。也就是说,我们不能拿 HTTP 协议的一些内容来控制路由,它的路由切入层次更低一些。
如下图,LVS 架设的服务器集群系统有三个部分组成:
- 最前端的负载均衡层,用 Load Balancer 表示
- 中间的服务器集群层,用 Server Array 表示
- 最底端的数据共享存储层,用 Shared Storage 表示
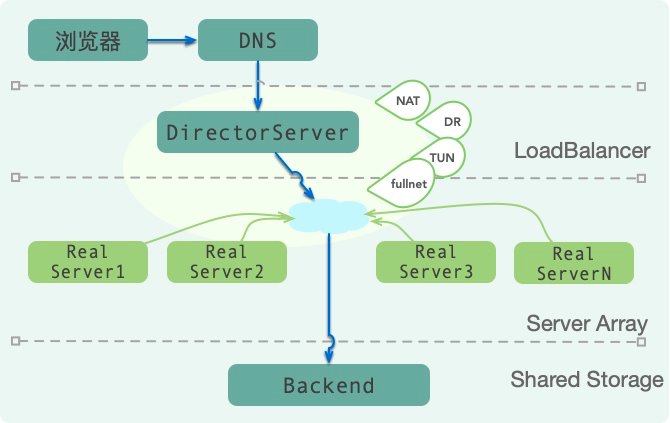
DR(直接路由)模式可将响应数据包直接返回给用户浏览器,避免负载均衡服务器网卡带宽成为瓶颈,是目前采用最为广泛的方式(数据不详,fullnat模式使用也比较广泛)。
所以,配合 DNS 的负载均衡,加上LVS的负载均衡,可以实现双层的负载均衡和高可用。
如图,DNS 可以将请求绑定在 VIP 上。由于 LVS DR 模式的效率非常高,网卡要达到瓶颈也需要非常大的请求量(只有入口流量才走LVS),所以一般通过 LVS 做 nginx 的负载均衡就足够了。如果 LVS 还有瓶颈,那么就可以在 DNS 上再做文章。
还有哪些挑战?
其实,我们上面谈到的这些方案,大多数是在同机房的。如果在多个机房,如何让用户选择最快的节点、如何保证负载均衡,又是一个大的问题。另外,你可以看到数据包经过层层的转发和协调,还有多种负载均衡算法参与其中,如何保持会话,也是一个挑战。一般的,四层会话会通过 IP 地址去实现,七层会话会通过 cookie 或者头信息等去实现。
开发人员一般情况下接触不到这么入口级的东西,但一旦遇到了,可能会受忙脚乱。本文是xjjdog根据一些即有的经验进行整理,希望你在公司需要一些高可用方案的时候,能够助你一臂之力。
什么叫方案?你只需要 当时 把你的领导哄好,让他感觉很认同的样子就行了。至于要不要做,具体怎么做,那都是后面的事。君不见,扯了这么半天,很多企业其实一个nginx,就可以走天下。
以上就是W3Cschool编程狮关于HA(高可用)就像套娃,像胖子,剥掉一层还有一层的相关介绍了,希望对大家有所帮助。