Apache Doris(前身为Palo)是一款开源的实时分析数据库解决方案,旨在解决大规模数据的实时查询和分析需求。它具有高性能、可扩展性和易用性等特点,深受企业和数据团队的青睐。本文将介绍Apache Doris的特点、架构和关键功能,探讨其在大数据分析领域的应用和优势。

Apache Doris的特点
- 高性能:Apache Doris通过使用列式存储、多级索引和智能压缩等技术,实现了高效的数据存储和查询。它能够处理大规模数据集,并提供快速的实时查询性能。
- 可扩展性:Apache Doris采用分布式架构,可以轻松地水平扩展,以适应不断增长的数据量和查询负载。它支持自动数据分片和负载均衡,保证了系统的高可用性和可扩展性。
- 易用性:Apache Doris提供了直观的用户界面和易于使用的查询语言。它支持标准的SQL语法和丰富的查询功能,使用户能够快速进行复杂的数据分析和查询操作。
- 实时性:Apache Doris支持实时数据导入和查询,可以在数据写入后立即进行分析,满足了实时业务和数据洞察的需求。
Apache Doris的架构
- 存储层:Apache Doris使用列式存储引擎,将数据按列存储,提高了查询性能和压缩率。它还支持多级索引和智能压缩算法,降低了存储成本。
- 计算层:Apache Doris采用分布式计算架构,将查询任务分布到不同的节点上并并行执行。这使得它能够在大规模数据集上快速执行复杂的数据分析和查询操作。
- 元数据管理:Apache Doris使用分布式元数据存储,存储表结构、分区信息和索引等元数据。这保证了系统的可靠性和元数据的一致性。
- 查询引擎:Apache Doris内置了高性能的查询引擎,支持多种查询操作,包括聚合查询、分组查询和多表连接等。它还提供了实时查询和交互式查询的能力。
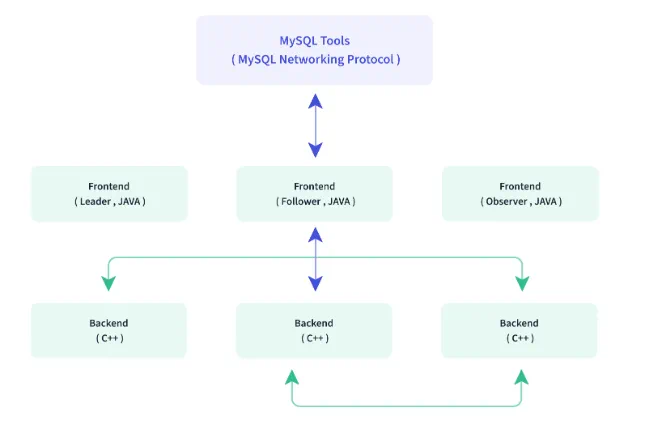
Apache Doris的关键功能
- 实时数据加载:Apache Doris支持实时数据加载,可以将实时产生的数据快速导入到数据库中进行实时分析。
- 多维分析:Apache Doris支持多维分析,可以进行复杂的数据透视和切片,帮助用户深入分析数据。
- 数据安全:Apache Doris提供了数据安全的功能,包括数据加密、权限控制和数据备份等,保护数据的机密性和完整性。
- 高可用性:Apache Doris通过数据分片和冗余存储,实现了高可用性和容错能力。在节点故障时,系统能够自动恢复并保证数据的可用性。
Apache Doris的应用
- 大数据分析:Apache Doris适用于大规模数据分析场景,如数据仓库、业务智能和实时报表等。它可以快速处理海量数据,并提供实时的查询和分析能力。
- 企业应用:Apache Doris可以应用于各种企业应用,如金融、电子商务和物流等领域。它可以支持复杂的数据分析和决策,提供准确的数据洞察和业务价值。
总结
Apache Doris作为一款开源的实时分析数据库解决方案,具有高性能、可扩展性和易用性等特点,适用于大数据分析和企业应用场景。它的列式存储引擎、分布式计算架构和实时查询能力使其成为处理大规模数据的理想选择。随着大数据和实时分析的需求不断增长,Apache Doris将继续发展和创新,为用户提供更强大的数据分析和洞察能力。

如果你对编程知识和相关职业感兴趣,欢迎访问编程狮官网(https://www.w3cschool.cn/)。在编程狮,我们提供广泛的技术教程、文章和资源,帮助你在技术领域不断成长。无论你是刚刚起步还是已经拥有多年经验,我们都有适合你的内容,助你取得成功。