在当今高度互联的数字世界中,监控和警报系统已经成为了保障应用程序和基础架构稳定性的关键组成部分。而在众多可选方案中,Prometheus凭借其强大的功能和灵活性逐渐崭露头角。本文将深入介绍Prometheus,探讨其特点、架构和用途,帮助读者了解和利用这个开源监控解决方案。
什么是Prometheus?
Prometheus是一个开源的系统监控和警报工具,由SoundCloud于2012年创建并于2015年开源。它旨在帮助开发人员和系统管理员收集、存储和分析应用程序和基础架构的度量指标数据。

Prometheus的特点
- 多维度数据模型:Prometheus采用多维度数据模型,每个时间序列由指标名称和一组标签键值对组成,使得数据的灵活建模和查询成为可能。
- 灵活的查询语言:Prometheus提供了强大而直观的查询语言PromQL,支持对指标数据进行过滤、聚合和计算,以满足不同的监控需求。
- 实时监控和警报:Prometheus具备实时监控能力,可以收集和存储时间序列数据,并根据用户定义的规则触发警报。这使得及时发现和解决问题成为可能。
- 可视化和报告:Prometheus可以与多种可视化工具和报告生成器集成,如Grafana和Prometheus自带的Dashboard,帮助用户更好地展示和理解监控数据。
- 可扩展性:Prometheus具有良好的可扩展性,能够处理大规模的监控环境。它支持分布式部署和自动发现,可以与其他工具集成,如Kubernetes、容器化应用和云服务。
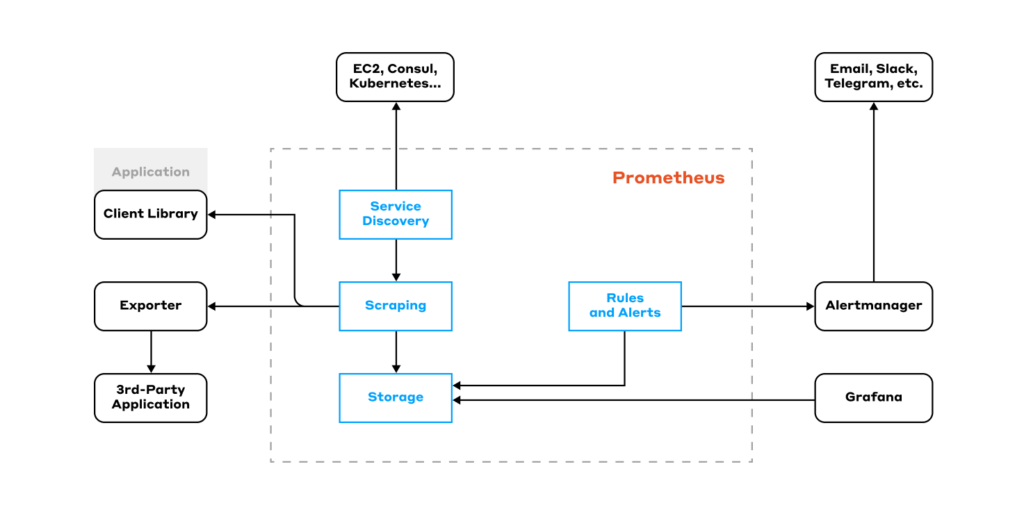
Prometheus的架构
- 数据采集器(Collector):负责定期收集和抓取目标系统的度量指标数据,并将其存储在本地数据库中。
- 存储引擎(Storage Engine):Prometheus使用自己的本地时间序列数据库,用于存储和查询采集到的指标数据。
- 查询处理器(Query Processor):处理用户通过PromQL查询语言提交的请求,从存储引擎中检索和计算所需的数据。
- 警报管理器(Alertmanager):负责接收来自Prometheus的警报信息,并根据用户定义的规则进行处理和分发。
Prometheus的使用场景
- 应用程序监控:Prometheus可以监控应用程序的性能指标、请求处理时间、错误率等,帮助开发人员及时发现和解决问题。
- 基础架构监控:Prometheus可用于监控服务器、网络设备、数据库、存储系统等基础架构组件的运行状态和性能指标。
- 容器化环境监控:作为Kubernetes的首选监控方案,Prometheus可以监控容器化环境中的Pod、服务发现、自动扩展等关键指标。
- 云服务监控:Prometheus支持与各种云服务提供商集成,如AWS、GCP和Azure,可以监控云资源的使用情况、服务健康状态等。
- 分布式系统监控:Prometheus的可扩展性使其成为监控分布式系统的理想选择,可以收集和分析分布式应用程序的度量指标。
总结
Prometheus作为一种现代监控和警报解决方案,具备灵活性、可扩展性和强大的功能集,得到了广泛的应用和社区支持。它的多维度数据模型、实时监控和警报能力以及可视化和报告功能,使得用户可以更好地理解和管理其应用程序和基础架构的健康状况。随着数字化时代的不断发展,Prometheus将继续在监控领域发挥重要的作用,为用户提供可靠的监控解决方案。

如果你对编程知识和相关职业感兴趣,欢迎访问编程狮官网(https://www.w3cschool.cn/)。在编程狮,我们提供广泛的技术教程、文章和资源,帮助你在技术领域不断成长。无论你是刚刚起步还是已经拥有多年经验,我们都有适合你的内容,助你取得成功。