在Java中,Integer封装类的相等性比较常常让人感到困惑。为什么当我们比较100和100时,结果为true,但比较1000和1000时,结果却为false?这个现象涉及到Java的整数缓存和对象引用的差异。在本文中,我们将揭示这个有趣的现象的原因,并解释如何正确比较整数封装类的相等性。

在Java中,对于整数类型的封装类Integer,我们经常会遇到一个有趣的现象:当比较两个小整数相等性时,例如100和100,结果为true;但当比较两个大整数相等性时,例如1000和1000,结果却为false。这种现象背后隐藏着Java中整数对象缓存和对象引用的一些细微差别。
public class Main {
public static void main(String[] args) {
Integer a = 1000;
Integer b = 1000;
System.out.println(a == b);
Integer c = 100;
Integer d = 100;
System.out.println(c == d);
}
}
/**
* 运行结果
* false
* true
*/为了提高性能和节省内存,Java在内部维护了一个整数缓存池,范围是-128到127。当我们创建一个Integer对象时,如果数值在这个范围内,Java会尝试从缓存池中获取已经存在的Integer对象。这样,当我们使用相同数值的两个Integer对象进行比较时,它们实际上是同一个对象的引用,因此比较结果为true。这种情况下,我们可以说它们是相等的。
然而,当整数超出了缓存池的范围,例如1000,Java会在堆中创建新的Integer对象,而不是从缓存池中获取。尽管它们的数值相同,但它们在内存中是不同的对象,具有不同的引用。因此,当我们比较两个大整数的相等性时,由于比较的是对象的引用而不是数值本身,结果为false。
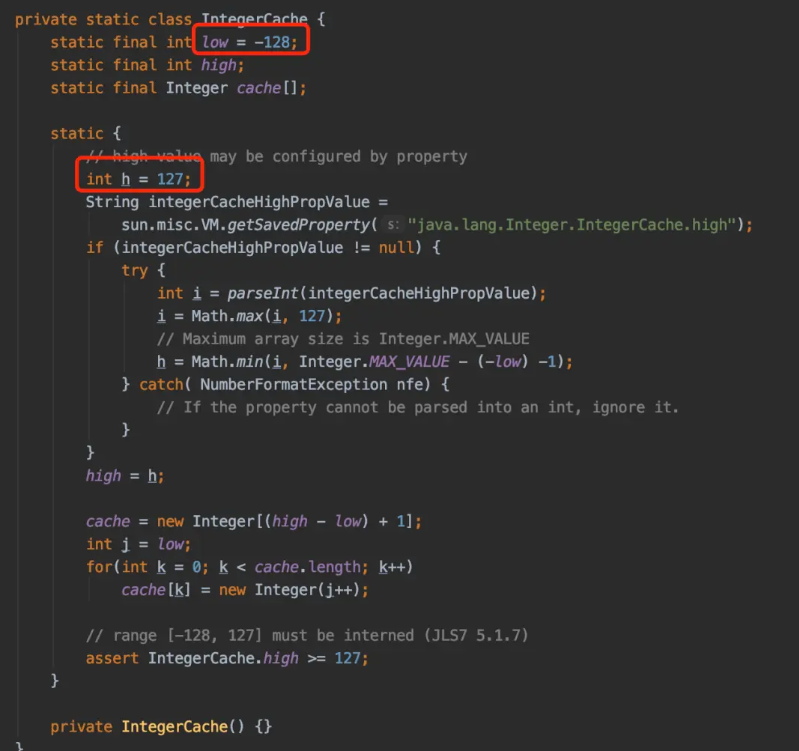
这种行为可以通过Java的自动装箱(Autoboxing)和拆箱(Unboxing)机制来解释。当我们使用==运算符比较两个Integer对象时,实际上是在比较它们的引用,而不是数值。如果我们想要比较它们的数值是否相等,应该使用equals()方法,因为在Integer类中,equals()方法被重写以进行数值的比较。
public class Main {
public static void main(String[] args) {
Integer a = 1000;
Integer b = 1000;
System.out.println(a.equals(b));
Integer c = 100;
Integer d = 100;
System.out.println(c == d);
}
}
/**
* 运行结果
* true
* true
*/需要注意的是,这种整数缓存的行为只适用于整数类型的封装类Integer,而不适用于其他封装类如Long、Double等。
为了避免这种混淆和潜在的错误,我们应该始终使用equals()方法来比较两个封装类的相等性,尤其是在使用自动装箱和拆箱的情况下。此外,如果我们需要比较大整数的相等性,建议使用equals()方法或将整数转换为基本数据类型进行比较。
总结
Java中的整数封装类Integer存在一个缓存池,对于-128到127之间的整数,它们是同一个对象的引用,因此比较结果为true;对于超出该范围的整数,它们是不同的对象,比较结果为false。这是由于自动装箱和对象引用的特性所导致的,我们应该谨慎使用==运算符来比较封装类的相等性,而是使用equals()方法来进行数值的比较。