在文章
部署CPU与GPU通用的tensorflow:Anaconda环境以及
部署可使用GPU的tensorflow库中,我们已经介绍了
Windows平台下,配置
CPU、
GPU版本的
tensorflow库的方法;而在本文中,我们就介绍一下在
Linux Ubuntu环境中,
CPU与
GPU版本
tensorflow库的配置方法。
K8s新手系列之指定Pod调度到指定节点上
在实际生产过程中,我们想让Pod调度到我们想要的节点上,往往通过kube-schedule默认的调度策略无法实现,这个时候我们需要指定一些策略来帮助我们实现。
NSDictionary 内存布局
熟悉
NSDictionary的内部实现,有助于我们更好的使用它们。
JAVA实现读取最后几行日志
主要使用 ReversedLinesFileReader 实现到读日志文件,需要引入commons-io依赖,底层使用 RandomAccessFile 实现.
FFmpeg开发笔记(六十二)Windows给FFmpeg集成H.266编码器vvenc
先下载最新的vvenc源码,解压下载后的源码包,再打开cmake-gui程序(cmake-gui的安装说明见《FFmpeg开发实战:从零基础到短视频上线》第八章的“8.1.5 给FFmpeg集成x265”)。cmake-gui窗口界面的source code栏填vvenc的源码目录,where to build栏填vvenc源码下的build目录,接着单击窗口左下方的Configure按钮,配置完成的窗口界面如下图所示。
GIS开发必知:WKT 与 EPSG 如何表达空间参考坐标系?附 GDAL 实现
通过第2章介绍的地理空间参考系统的知识我们可以知道,一个空间参考坐标系的内容是非常丰富的:需要描述参考椭球参数、基准面参数等;如果是投影坐标系,还需要描述投影参数,并且每个投影算法的参数都不同。而在实际的GIS应用中,对空间参考坐标系的表达是复用程度和通用程度都很高的功能;那么,有没有一种可能,采用一种约定俗成的方式,去描述各种空间参考坐标系呢。答案是肯定的,那就是WKT字符串和EPSG编码。
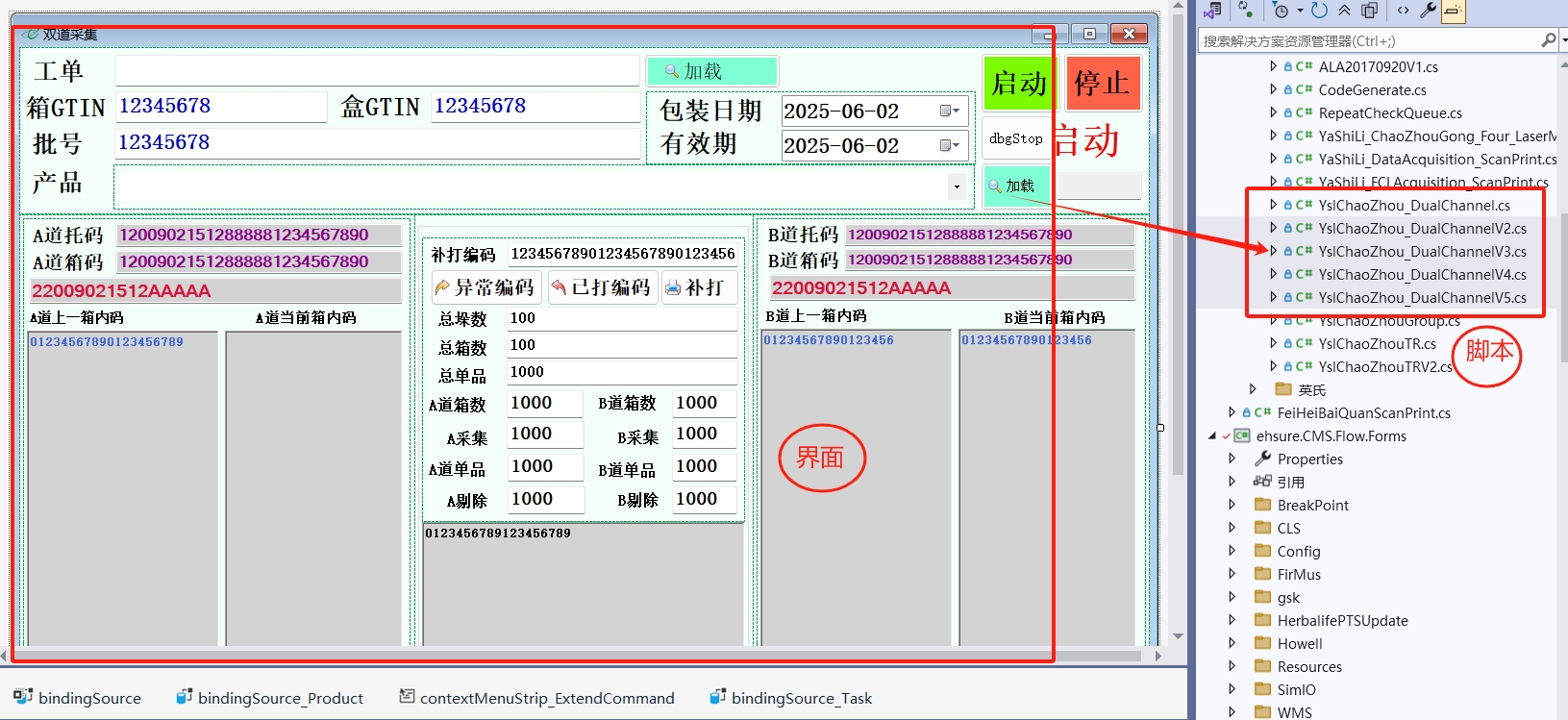
Winform高级技巧-界面和代码分离的实践案例
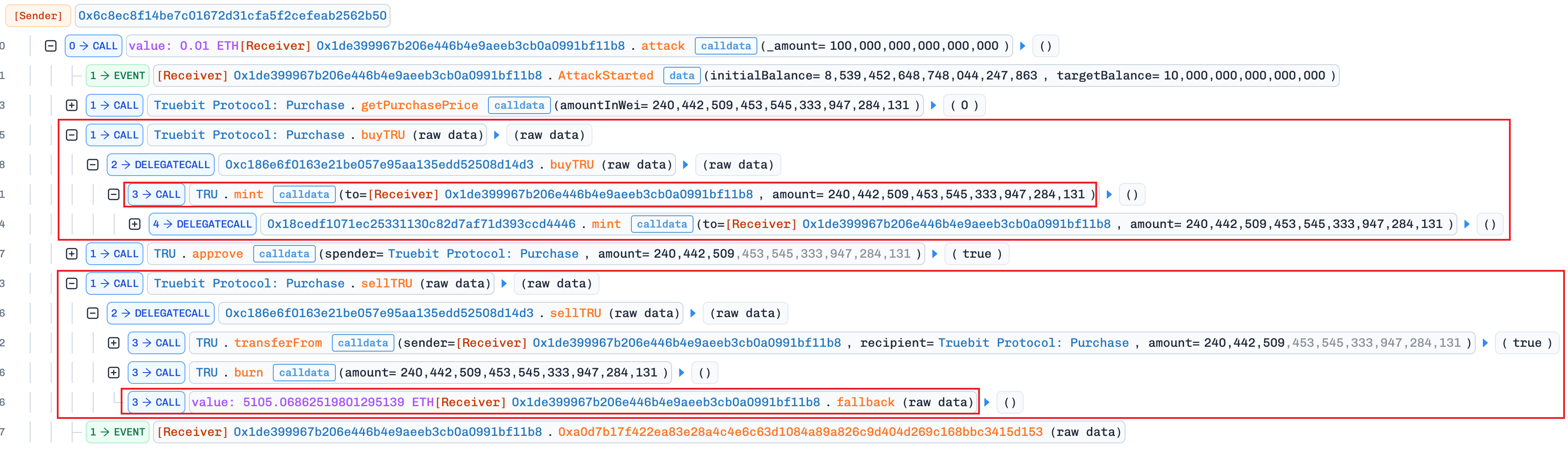
20260109 – TRU 协议攻击事件分析:买得够多免费送了喂!
基于梯度组合的多任务 / 多目标学习
其核心矛盾在于:不同任务的梯度(指导模型更新的方向)经常“打架”。有的梯度幅值大,有的方向完全相反。简单地将梯度加起来更新,模型就会被大梯度或某个特定任务“带偏”,导致其他任务学不好。