上一篇,我们学习了MAF中如何持久化聊天记录到关系型数据库。这一篇,我们来学习一下工作流编排。不知大家是否记得,我们在之前用Semantic Kernel学习过多Agent编排的一些知识,例如顺序,并发,移交等模式仍然历历在目。那么,今天,我们用MAF的工作流编排来实现一下,看看有什么不一样。
rllm中的推理流程
我们打印出一条推理路径看看效果
.NET周刊【11月第2期 2025-11-09】
文章讨论.NET 开发者在 AI 领域的潜力,反驳了对.NET 与 AI 不匹配的常见误解。作者指出,虽然 Python 在 AI 研究阶段有优势,但在生产环境中,.NET 因其性能、类型安全和企业集成能力更为优越。文章详细介绍了微软在.NET AI 生态的快速发展,强调了 Semantic Kernel 和 MEAI 等工具的推出,使.NET 开发者能够灵活开发 AI 应用。这些发展使得.NET 开发者能够与 AI 的红利接轨,而不必转型为 Python 开发者。
从硬盘I/O到网络传输:Kafka与RocketMQ读写模型及零拷贝技术深度对比
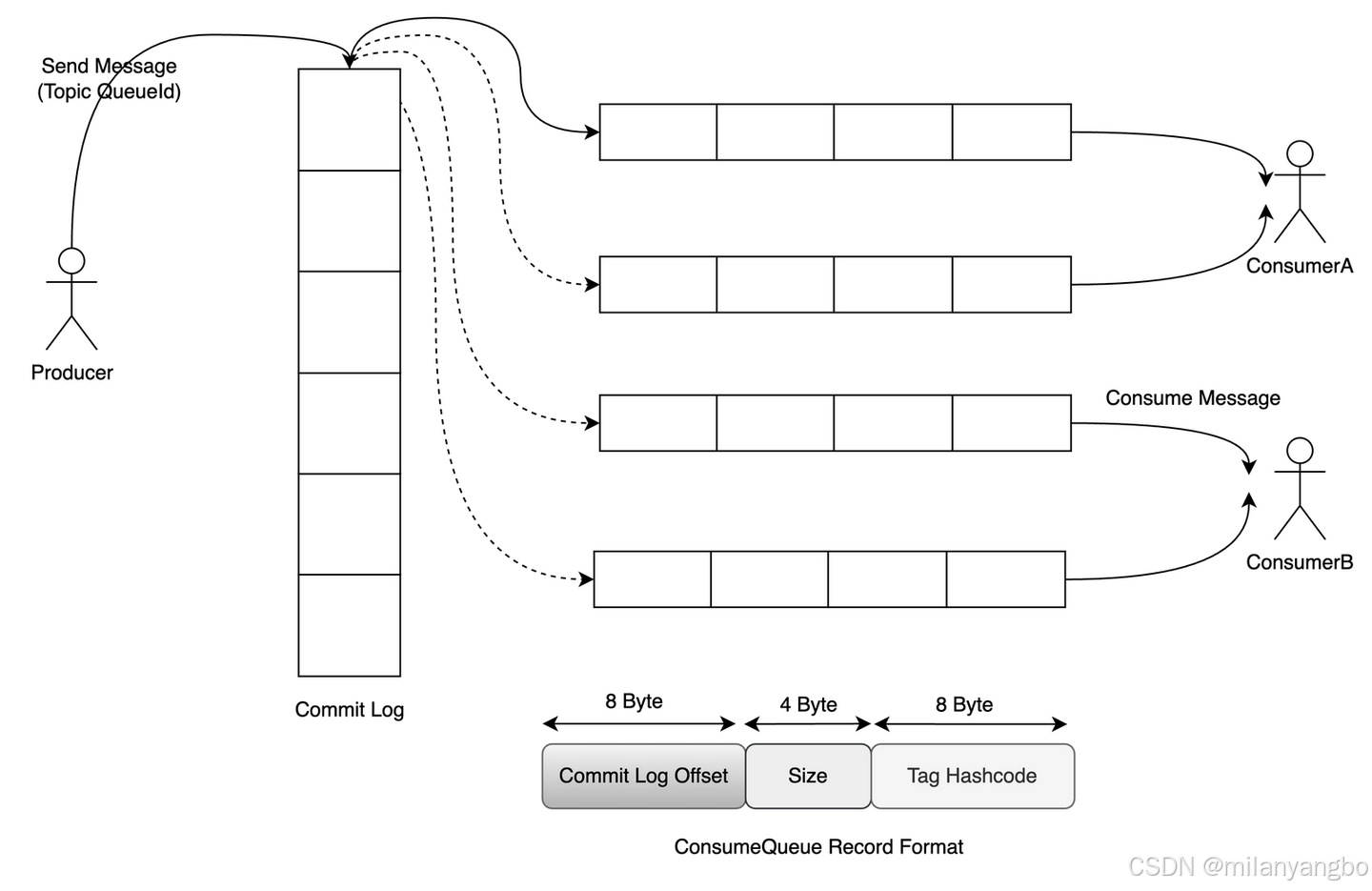
在RocketMQ中,所有主题的所有消息数据,无论其逻辑归属如何,都会被首先写入到一个名为提交日志(CommitLog)的中心化大文件中。这个CommitLog文件由多个固定大小(默认为1GB)的文件顺序组成,当前只有一个文件处于可写状态。因为所有写操作都集中在这一点,即便随着主题和队列数量的急剧增加,硬盘在同一时间也只对一个文件进行追加写入,从而保证了绝对的顺序写。为了进一步提升I/O效率,RocketMQ采用内存映射(mmap)技术来读写CommitLog。
当消息需要被消费时,直接扫描庞大的CommitLog显然是低效的。为此,RocketMQ为每个主题的每个消息队列(ConsumeQueue)建立了一个独立的、轻量级的消费队列文件。每个ConsumeQueue条目都是固定长度的(20字节),其中存储了该消息在CommitLog中的物理偏移量(Offset)(8字节)、消息总大小(Size)(4字节)以及消息Tag的哈希码(8字节)。当消费者拉取消息时,它首先顺序读取对应ConsumeQueue文件中的索引条目,根据获取到的物理偏移量,再到CommitLog中定位并读取到完整的消息数据。这种“先读索引,再读数据”分离的模式,既保证了写入的绝对顺序性,又实现了消费时的高效查找。
此外,为了支持按消息Key或时间范围等维度的快速查询,RocketMQ还提供了可选的索引文件(IndexFile)。其底层数据结构本质上是一个存储在硬盘上的哈希表。IndexFile由文件头、哈希槽(Slot Table)和索引条目列表(Index Linked List)三部分组成。当根据Key查找时,先计算Key的哈希值并定位到对应的哈希槽,该槽内存储了指向最新一条索引条目的指针。由于可能存在哈希冲突,具有相同哈希值的索引条目会通过前向指针形成一个链表。
SvelteKit 开发实战:拥抱 Web 标准 (Web Standards)
这意味着,SvelteKit 的核心并非由复杂的私有 API 堆砌而成,而是构建在标准的
MDN Web APIs 之上。这种设计理念不仅让你的现有 Web 开发技能可以直接迁移,而且学习 SvelteKit 的过程,本质上就是在学习通用的 Web 标准,让你成为更强大的开发者。
团队里最”危险”的人,是那个什么都懂却从不写文档的”大神”
我们经常陷入一种误区:
盲目崇拜”全能大神”。
那些遇到问题能秒解、对业务逻辑倒背如流、在脑子里跑完整个流程的员工,通常被视为公司的资产。
Hudi 数据模型分析
在 Hudi 里,一条数据记录不是简单的字符串或者字节数组,而是一个结构化的对象,包含了记录本身的数据、唯一标识、存储位置等信息。这种设计让 Hudi 能够高效地管理数据,支持更新、删除、合并等复杂操作。
【python】字典数据结构的设计原理学习
其中,
如何将WinForm.NET代码迁移到Blazor WASM平台上
南京都昌信息科技有限公司 袁永福 2025-12-3
ELK日志分析平台搭建实战:从日志混乱到一目了然
痛点: