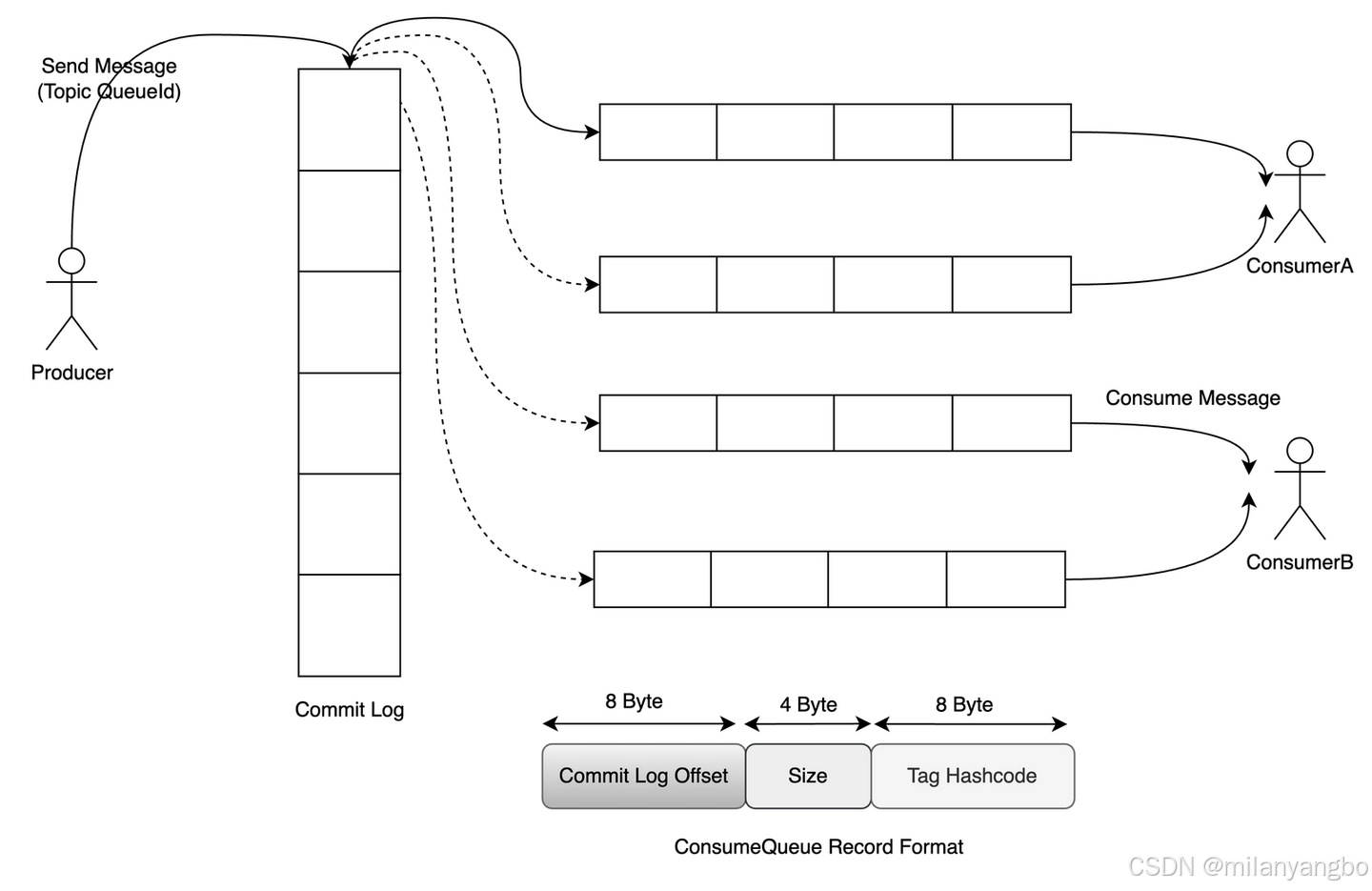
在RocketMQ中,所有主题的所有消息数据,无论其逻辑归属如何,都会被首先写入到一个名为提交日志(CommitLog)的中心化大文件中。这个CommitLog文件由多个固定大小(默认为1GB)的文件顺序组成,当前只有一个文件处于可写状态。因为所有写操作都集中在这一点,即便随着主题和队列数量的急剧增加,硬盘在同一时间也只对一个文件进行追加写入,从而保证了绝对的顺序写。为了进一步提升I/O效率,RocketMQ采用内存映射(mmap)技术来读写CommitLog。
当消息需要被消费时,直接扫描庞大的CommitLog显然是低效的。为此,RocketMQ为每个主题的每个消息队列(ConsumeQueue)建立了一个独立的、轻量级的消费队列文件。每个ConsumeQueue条目都是固定长度的(20字节),其中存储了该消息在CommitLog中的物理偏移量(Offset)(8字节)、消息总大小(Size)(4字节)以及消息Tag的哈希码(8字节)。当消费者拉取消息时,它首先顺序读取对应ConsumeQueue文件中的索引条目,根据获取到的物理偏移量,再到CommitLog中定位并读取到完整的消息数据。这种“先读索引,再读数据”分离的模式,既保证了写入的绝对顺序性,又实现了消费时的高效查找。
此外,为了支持按消息Key或时间范围等维度的快速查询,RocketMQ还提供了可选的索引文件(IndexFile)。其底层数据结构本质上是一个存储在硬盘上的哈希表。IndexFile由文件头、哈希槽(Slot Table)和索引条目列表(Index Linked List)三部分组成。当根据Key查找时,先计算Key的哈希值并定位到对应的哈希槽,该槽内存储了指向最新一条索引条目的指针。由于可能存在哈希冲突,具有相同哈希值的索引条目会通过前向指针形成一个链表。
从硬盘I/O到网络传输:Kafka与RocketMQ读写模型及零拷贝技术深度对比
未经允许不得转载:小狮博客 » 从硬盘I/O到网络传输:Kafka与RocketMQ读写模型及零拷贝技术深度对比