
ToCom:一次训练随意使用,华为提出通用的ViT标记压缩器 | ECCV 2024

SQL 高级语法 MERGE INTO
这里的Source table 不限于单独的表格,也可以是子查询的内容
论文阅读翻译之Deep reinforcement learning from human preferences
最近在将强化学习 (RL) 扩展到大规模问题上取得的成功,主要得益于那些具有明确奖励函数的领域(Mnih等, 2015, 2016; Silver等, 2016)。不幸的是,许多任务的目标是复杂的、定义不清的或难以明确说明的。克服这一限制将大大扩展深度强化学习的潜在影响,并可能进一步扩大机器学习的应用范围。
区块链应用与以太坊的交互
对于一些简单的调用,通过上面两种方式是可行的,例如我们只是做一些nft的构造,通过钱包是最合适的。但是对于向arbitrum这类
链上的应用,如果要做一个交互式单步证明,在这个过程中我需要监控链上合约抛出的event,分析event并构造出相应结果。
这个时候钱包就很难插手,而如果主动构造交易并签名,那么过程太繁琐。实际上以太坊上已经提供了相关的工具链。
Logstash 配置Java日志格式的方法
下面是一个 Logstash 配置示例,该示例假设我们有一个 Java 应用,其日志文件遵循常见的日志格式,例如 Logback 的默认模式(包含时间戳、日志级别、线程名称、日志记录器名称和消息)。
Go runtime 调度器精讲(二):调度器初始化
上一讲 介绍了 Go 程序初始化的过程,这一讲继续往下看,进入调度器的初始化过程。
Blazor开发框架Known-V2.0.10
下面是本次版本的更新内容。
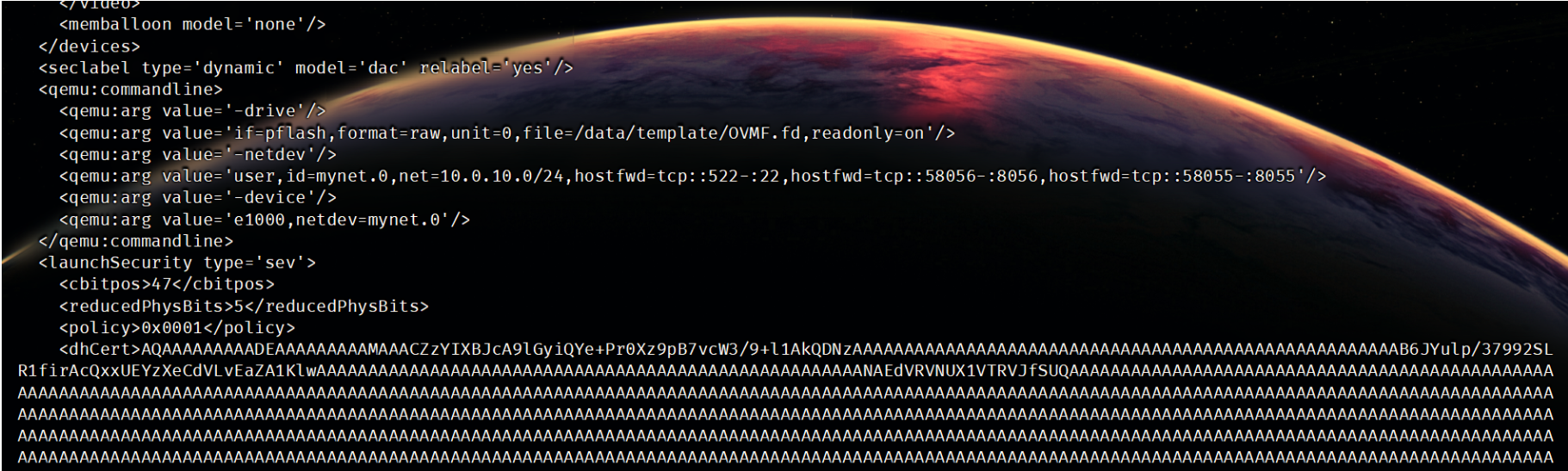
qemu虚拟机启动后无法远程连接
TreeMap源码详解—彻底搞懂红黑树的平衡操作
Java
TreeMap实现了
SortedMap接口,也就是说会按照key的大小顺序对
Map中的元素进行排序,key大小的评判可以通过其本身的自然顺序(natural ordering),也可以通过构造时传入的比较器(Comparator)。