在当今数字化的世界中,API扮演着连接软件和服务的关键角色。然而,一个高效的API并非自然而然产生,而是需要经过精心设计和优化。优化API性能是保证应用程序高效运行的关键步骤之一。通过精益求精的策略和技术手段,可以显著提升API的效率、响应速度和可靠性。本文将探讨一系列有效的方法,以帮助您优化API性能,为用户提供更快速、更可靠的服务体验。
API(Application Programming Interface)是一组定义了软件系统如何相互交互的规则集合。它允许不同软件或服务之间互相通信和交换数据,提供了一种编程的接口,使得不同系统之间能够有效地进行信息传递和功能调用。 API就像是软件应用的门户,允许开发者访问另一个软件或服务的功能,从而进行数据交换或执行特定任务。
缓存
缓存是一种将经常访问的数据存储在内存或其他快速存储设备中的技术,利用缓存可以大幅提升API性能。缓存常用于存储频繁请求的数据,以减少对数据库或其他慢速存储设备的访问次数,从而提高数据的读取速度。缓存可以分为客户端缓存和服务器端缓存,根据不同的场景和需求选择合适的缓存策略。

连接池
连接池是一种管理数据库连接的技术,它可以在系统启动时创建一定数量的数据库连接,并将它们保存在一个池中,当有请求需要访问数据库时,直接从连接池中获取一个空闲的连接,使用完毕后再将连接归还到连接池中,这样可以避免频繁地创建和销毁数据库连接,提高数据库连接的复用率和效率。连接池可以根据不同的参数进行配置。

异步处理
异步是一种编程模型,它可以在一个线程中执行多个任务,而不需要等待每个任务的完成,从而提高线程的利用率和并发能力。异步可以分为客户端异步和服务器端异步,根据不同的场景和需求选择合适的异步方式。例如,对于一些非核心的或者耗时的任务,可以使用客户端异步,让客户端在发起请求后不需要等待服务器的响应,而是继续执行其他任务,当服务器返回响应后,再通过回调函数或者事件机制处理响应。对于一些核心的或者快速的任务,可以使用服务器端异步,让服务器在收到请求后不需要同步地执行任务,而是将任务交给一个线程池或者一个消息队列,然后立即返回一个响应,表示任务已经接收,当任务执行完毕后,再通过回调函数或者事件机制通知客户端。使用异步可以有效地减少线程的阻塞和等待,提升API的性能。

N+1问题
N+1问题是一个在数据库查询性能优化领域常见的问题,指的是在进行关联查询时,如果需要获取主表中的N条记录以及每条记录关联的另一个表中的相关信息时,会导致在获取相关信息时产生额外的查询操作,从而造成额外的负担和性能问题。

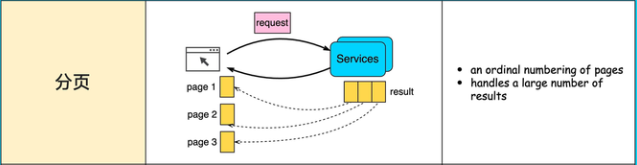
分页
分页是一种将大量的数据分成多个页面进行展示的技术,它可以让用户在不加载全部数据的情况下,快速地浏览和查找所需的数据,提高用户的体验和满意度。分页可以分为客户端分页和服务器端分页,根据不同的场景和需求选择合适的分页方式。
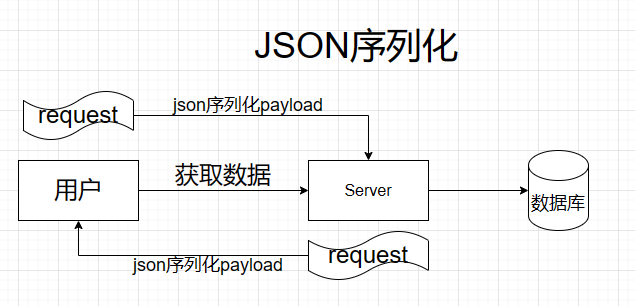
JSON序列化
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,它易于人类阅读和编写,同时也易于机器解析和生成。JSON可以将复杂的数据结构或对象转换为简单的字符串,以便在网络传输、存储或与其他程序交互时进行数据交换。JSON序列化是将数据结构或对象转换为JSON格式的字符串的过程,JSON反序列化是将JSON格式的字符串转换为数据结构或对象的过程。在各种编程语言中,都有相应的库或内置函数来进行JSON序列化和反序列化操作。使用JSON序列化可以有效地减少数据的大小和复杂度,提升数据的可读性和可维护性,提升API的性能。
总结
优化API性能是保证应用程序高效运行的重要步骤。通过采用缓存、异步处理等技术,可以大幅提升API的响应速度和吞吐量,从而提供更好的用户体验。同时,持续的监控和优化是确保API性能持续优化的关键。综上所述,优化API性能不仅仅是提高系统效率,更是提升用户满意度和应用竞争力的重要手段。因此,对API性能的持续关注和优化是保持应用程序高性能的不二选择。