MongoDB副本集是一种提供高可用性和数据冗余的解决方案。本文将介绍MongoDB副本集的概念、架构和工作原理,以及它在数据保护和故障恢复方面的作用。
副本集简介
副本集(Replica Set)是MongoDB中的一种维护相同数据集的服务,提供了冗余和高可用性。副本集类似于主从集群,使用多台机器进行数据同步,实现多个副本的数据一致性。当主库发生故障时,副本集会自动切换其他备份服务器作为主库。此外,副本集还可以实现读写分离,利用副本服务器作为只读服务器,提高负载能力。

副本集架构和组成
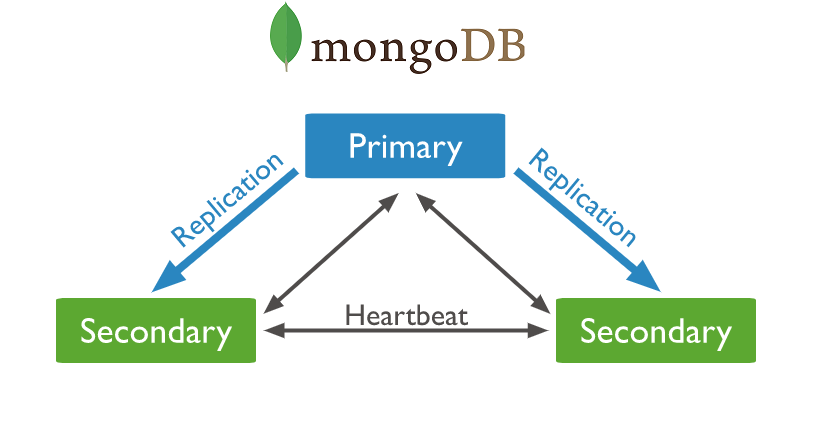
副本集由多个节点组成,其中包括一个主节点(Primary)和多个从节点(Secondary)。主节点负责处理所有的写操作,并将写操作的结果异步地复制给从节点。从节点会持续地复制主节点的数据,并可以接收读取操作。此外,副本集还可以包括一个仲裁节点(Arbiter),用于解决选举过程中的投票平局。
副本集的工作原理
- 主节点的角色:主节点是副本集中的核心节点,它处理所有的写操作,并将写操作的结果复制给从节点。主节点还负责维护副本集的状态信息,如成员列表和选举信息。如果主节点发生故障或不可用,副本集会自动触发选举过程,选择一个新的主节点。
- 从节点的角色: 从节点是副本集中的备份节点,它负责复制主节点的数据,并可以接收读取操作。从节点会持续地从主节点复制数据,并与主节点保持同步。如果主节点不可用,副本集会从从节点中选择一个新的主节点。
- 数据复制和同步:副本集使用Oplog(操作日志)来实现数据的复制和同步。当主节点接收到写操作时,它会将操作记录在Oplog中,并将Oplog的数据发送给从节点。从节点会按顺序读取Oplog的数据,并将操作应用到自己的数据集中,以保持与主节点的数据一致性。
- 选举过程:副本集中的选举过程用于选择一个新的主节点,以应对主节点故障或不可用的情况。当主节点不可用时,从节点会发起选举过程,各节点会相互交换选票,并根据一定的规则选择新的主节点。副本集会根据选举算法(如Raft或Paxos)来确保选举的正确性和稳定性。
副本集的作用和优势
- 高可用性: 副本集提供了高可用性的解决方案,当主节点不可用时,副本集会自动选择一个新的主节点,以保持系统的可用性。这可以减少故障对应用程序的影响,并提供连续的服务。
- 数据冗余和灾备:通过在多个节点上复制数据,副本集实现了数据的冗余和灾备。即使某个节点发生故障或数据损坏,副本集中的其他节点仍然可以提供数据访问和恢复,确保数据的可靠性和完整性。
- 故障恢复和自动故障转移:副本集具有自动故障转移的能力,当主节点不可用时,副本本集会自动选择一个新的主节点,以确保系统的可用性和数据的一致性。这意味着即使发生故障,副本集也能快速恢复并继续提供服务,减少停机时间和数据丢失的风险。
- 扩展性和负载均衡:副本集还可以用于提高系统的扩展性和负载均衡能力。通过将读取操作分布到多个从节点上,副本集可以实现读写分离,提高系统的整体吞吐量和响应速度。
总结
MongoDB副本集是一种提供高可用性和数据冗余的解决方案。它通过在多个节点上复制数据,并保持数据的一致性和可用性,提供了故障恢复、数据冗余和灾备、自动故障转移等功能。副本集还可以提高系统的扩展性和负载均衡能力,从而满足不同规模和需求的应用程序。对于需要高可用性和数据保护的MongoDB部署,副本集是一个可靠且成熟的选择。