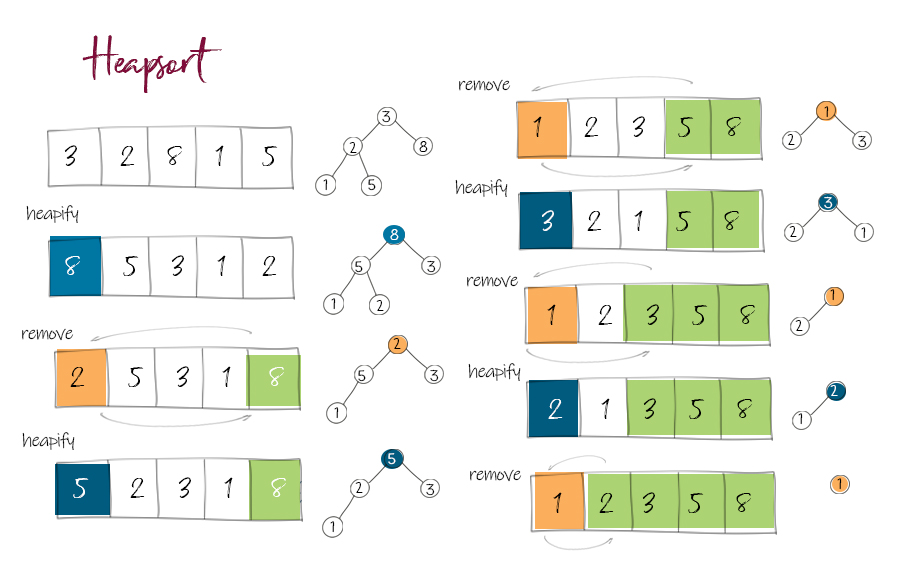
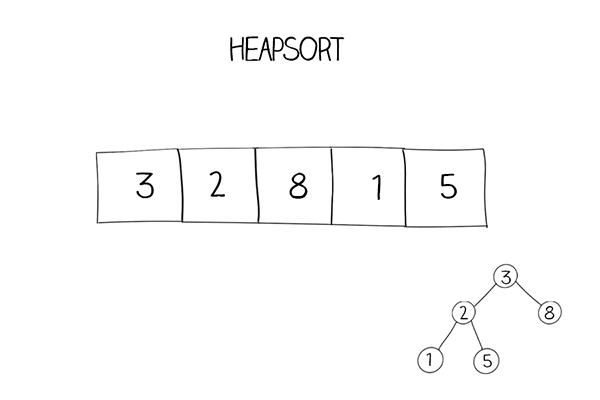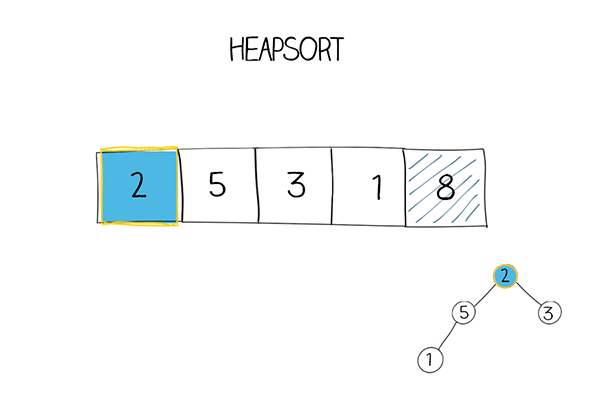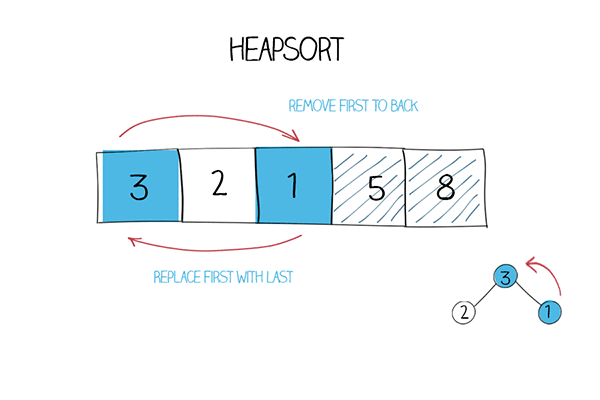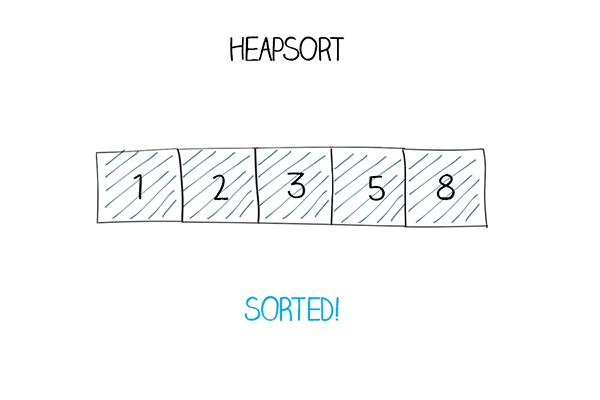
Spring Boot作为一个强大的Java开发框架,以其简化配置和快速开发的特性而备受开发者欢迎。其中最引人注目的特性之一就是自动装配(Auto-Configuration)。Spring Boot的自动装配机制可以帮助开发者自动配置和组装各种组件,提供了更加便捷的开发体验。本文将深入探究Spring Boot自动装配的原理与机制,帮助读者理解其工作原理,并为如何自定义和扩展自动装配提供指导。
Spring Boot自动装配概述
自动装配是Spring Boot提供的一种机制,用于根据应用程序的依赖关系自动配置和组装Spring Bean。它通过分析类路径上的依赖和条件判断,自动加载并配置所需的Bean,从而简化了繁琐的配置过程。自动装配的好处自动装配可以大大减少开发者的工作量,提高开发效率。它能够自动处理各种依赖关系和配置细节,使开发者能够更专注于业务逻辑的实现。

Spring Boot自动装配原理
- 条件注解(Conditional Annotation):Spring Boot使用条件注解来控制自动装配的条件和规则。条件注解可以根据特定的条件判断是否进行自动装配,例如
@ConditionalOnClass、@ConditionalOnProperty等。 - 自动配置类(Auto-Configuration Class):自动配置类是Spring Boot自动装配的核心组件。它使用
@Configuration注解标记,并通过@EnableAutoConfiguration注解启用自动装配。自动配置类中定义了一系列的Bean定义和配置,以满足特定条件下的自动装配需求。 - Spring Boot的启动过程:在Spring Boot启动过程中,会自动扫描并加载类路径下的自动配置类。通过条件注解的判断,选择合适的自动配置类进行装配。自动配置类中的Bean定义会被Spring容器自动加载,并根据条件进行实例化和装配。
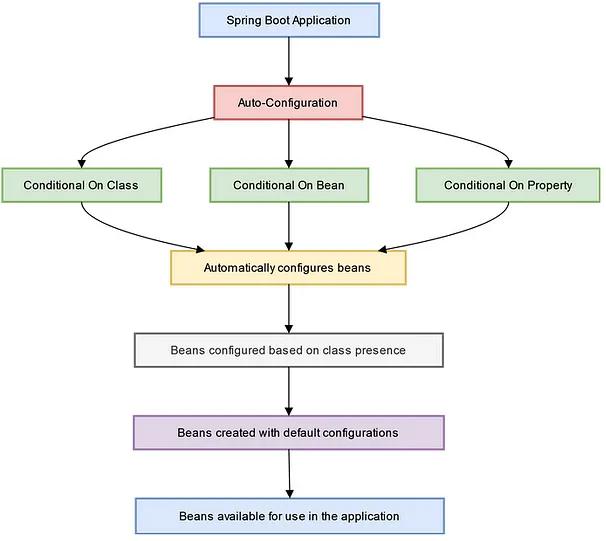
自定义和扩展自动装配
- 排除自动装配:开发者可以使用
@SpringBootApplication注解的exclude属性或@EnableAutoConfiguration注解的exclude属性,排除特定的自动配置类。 - 自定义自动装配:开发者可以编写自己的自动配置类,通过
@Configuration和条件注解来定义自动装配的规则。自定义自动配置类应放置在Spring Boot的自动扫描路径下,以被自动加载和装配。 - 自定义属性配置:开发者可以通过
@ConfigurationProperties注解和application.properties文件定义自定义属性,并在自动配置类中使用这些属性进行配置。
总结
Spring Boot自动装配机制是其独特的特性之一,通过条件注解和自动配置类的协作,实现了便捷的Bean加载和配置。理解Spring Boot自动装配的原理和机制,有助于开发者更好地利用和扩展自动装配功能,提升开发效率和代码质量。