Java是一种面向对象的编程语言,广泛应用于软件开发。在Java中,源代码需要被编译成字节码才能在Java虚拟机中执行。Java字节码作为一种中间表示形式,在Java开发和执行过程中发挥着重要作用。本文将深入讨论Java字节码的概念、结构和好处,帮助读者更好地理解和欣赏Java字节码技术。
Java字节码的概念
Java字节码是Java源代码编译后生成的中间代码,它是一种与平台无关的二进制格式。Java字节码包含一系列指令,用于在Java虚拟机中执行程序。它是一种面向栈的指令集,其中操作数从操作数栈中取出并进行计算。
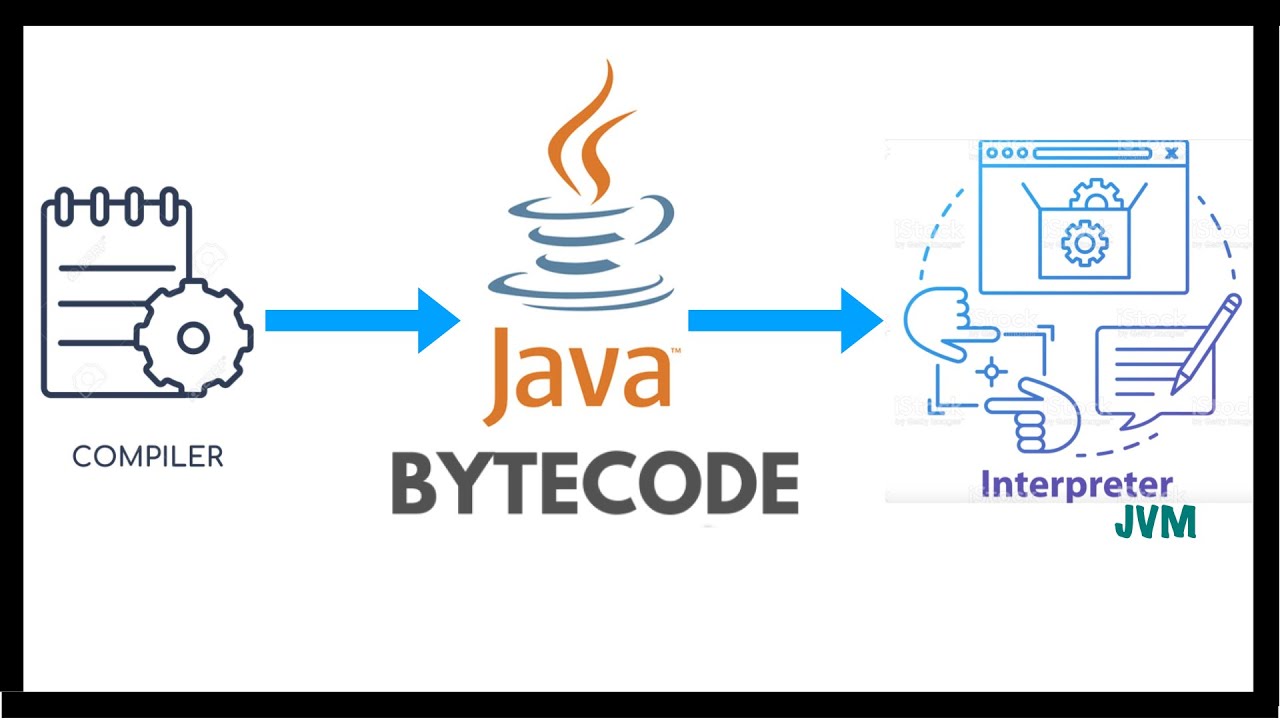
Java字节码的工作原理
当我们用Java编写程序时,首先,编译器会编译该程序,并为该代码生成字节码。当我们希望在任何其他平台上运行这个 .class 文件时,我们可以这样做。第一次编译后,生成的字节码现在由 Java 虚拟机运行,而不是由所考虑的处理器运行。这本质上意味着我们只需要在我们想要运行代码的任何平台上进行基本的 java 安装。运行字节码所需的资源由 Java 虚拟机提供,它调用处理器来分配所需的资源。 JVM 是基于堆栈的,因此它们通过堆栈实现来读取代码。
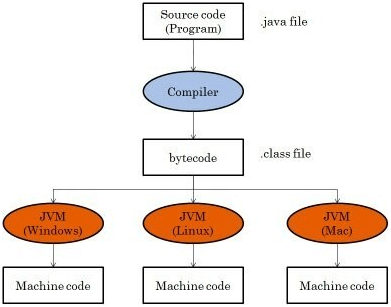
Java字节码的结构
Java字节码的结构由操作码和操作数组成。操作码指示虚拟机执行的具体操作,例如加载、存储、算术运算等。操作数提供了执行操作所需的参数,例如变量索引、常量值等。Java字节码的结构非常紧凑,使得它在执行时具有高效性能。
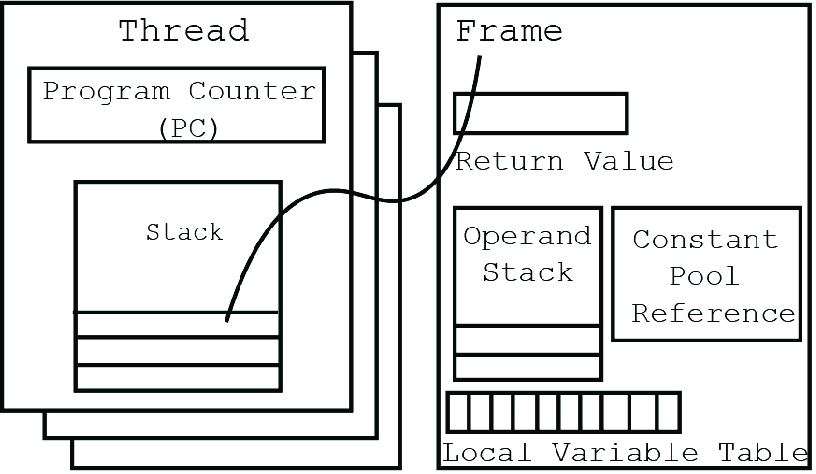
采用Java字节码的好处
- 跨平台性:Java字节码是与平台无关的,它可以在不同的操作系统和硬件上执行。Java虚拟机负责解释和执行字节码,使得Java程序具有跨平台的特性,一次编写,到处执行。
- 安全性:Java字节码可以通过字节码校验器进行验证,以确保其符合Java安全规范。这种验证过程可以防止恶意代码的执行,提高程序的安全性。Java虚拟机的安全管理器还可以对字节码进行访问控制和权限管理。
- 动态性:Java字节码具有动态性,它可以在运行时进行加载、链接和执行。这使得Java程序可以动态地加载和使用类,实现灵活的扩展和插件机制。
- 性能优化:Java虚拟机可以对字节码进行即时编译(Just-In-Time Compilation),将其转换为本地机器代码以提高执行速度。优化技术包括方法内联、循环展开和逃逸分析等,可以使Java程序达到接近本地代码的性能水平。
- 调试和分析:Java字节码可以被调试器和分析工具解析和处理,提供强大的调试和性能分析能力。开发人员可以在执行过程中检查字节码的状态、执行路径和变量值,帮助排查问题和优化程序。
Java字节码的应用领域
- Java虚拟机(JVM):Java字节码是在JVM中执行的中间代码。Java源代码通过编译器转换为字节码,然后由JVM解释和执行。
- Android开发:Android应用程序也是通过Java字节码在Dalvik虚拟机或ART(Android Runtime)中执行。Android开发者使用Java语言编写应用程序,然后将其编译成字节码。
- 字节码增强框架:字节码增强框架(如AspectJ)利用Java字节码的特性,可以在编译期或运行期修改和增强字节码,实现横切关注点的处理、动态代理和性能监控等功能。
总结
Java字节码作为Java程序在Java虚拟机中执行的中间表示形式,具有跨平台性、安全性、动态性和性能优化等优势。它使得Java程序可以在不同的平台上运行,并且具备强大的安全机制和动态扩展能力。通过深入了解和应用Java字节码,开发人员可以优化程序性能、实现跨平台兼容性,并增强代码的安全性和灵活性。Java字节码技术的发展为Java开发和执行带来了新的可能性,为构建高效、安全和可扩展的应用提供了基础。