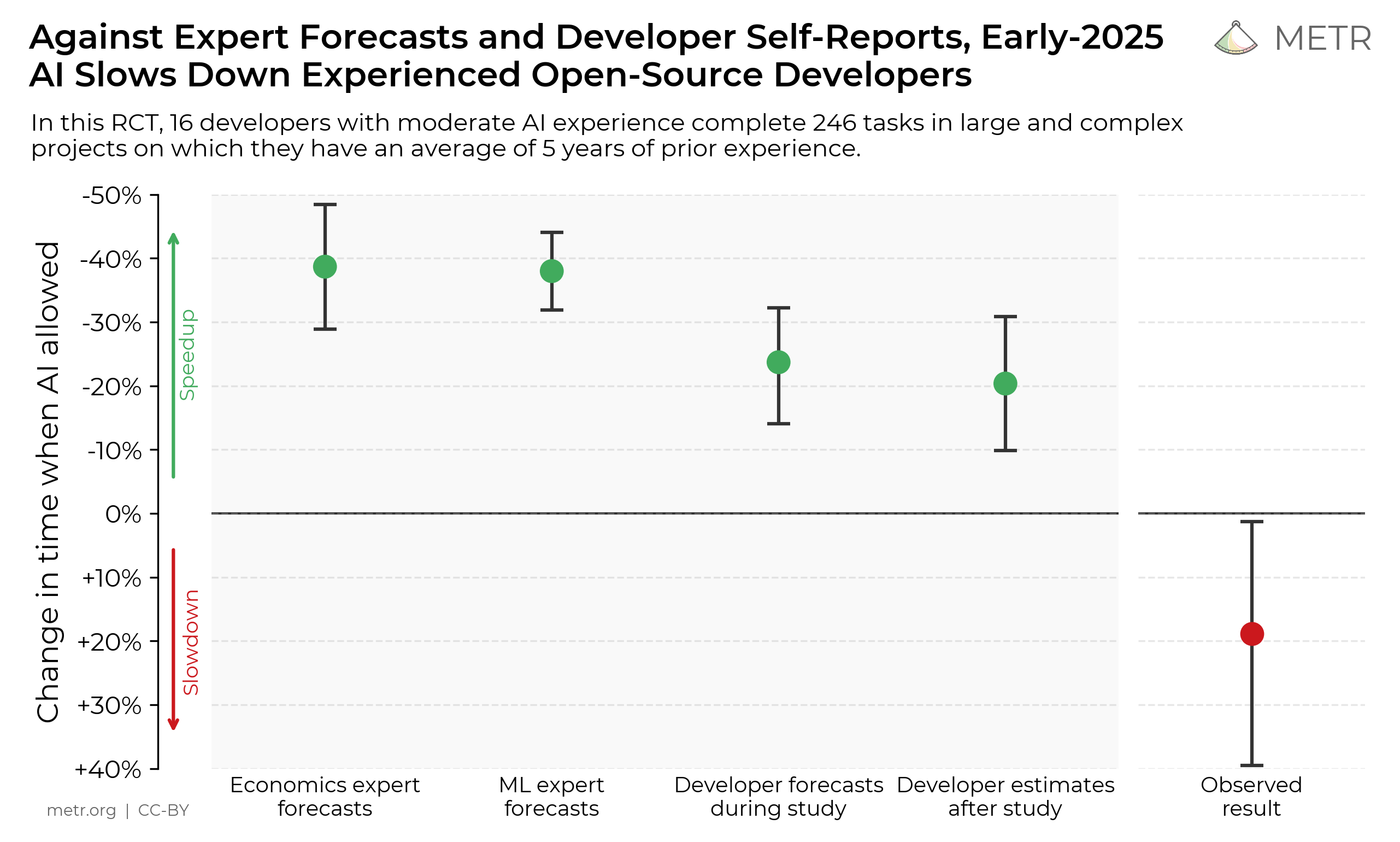
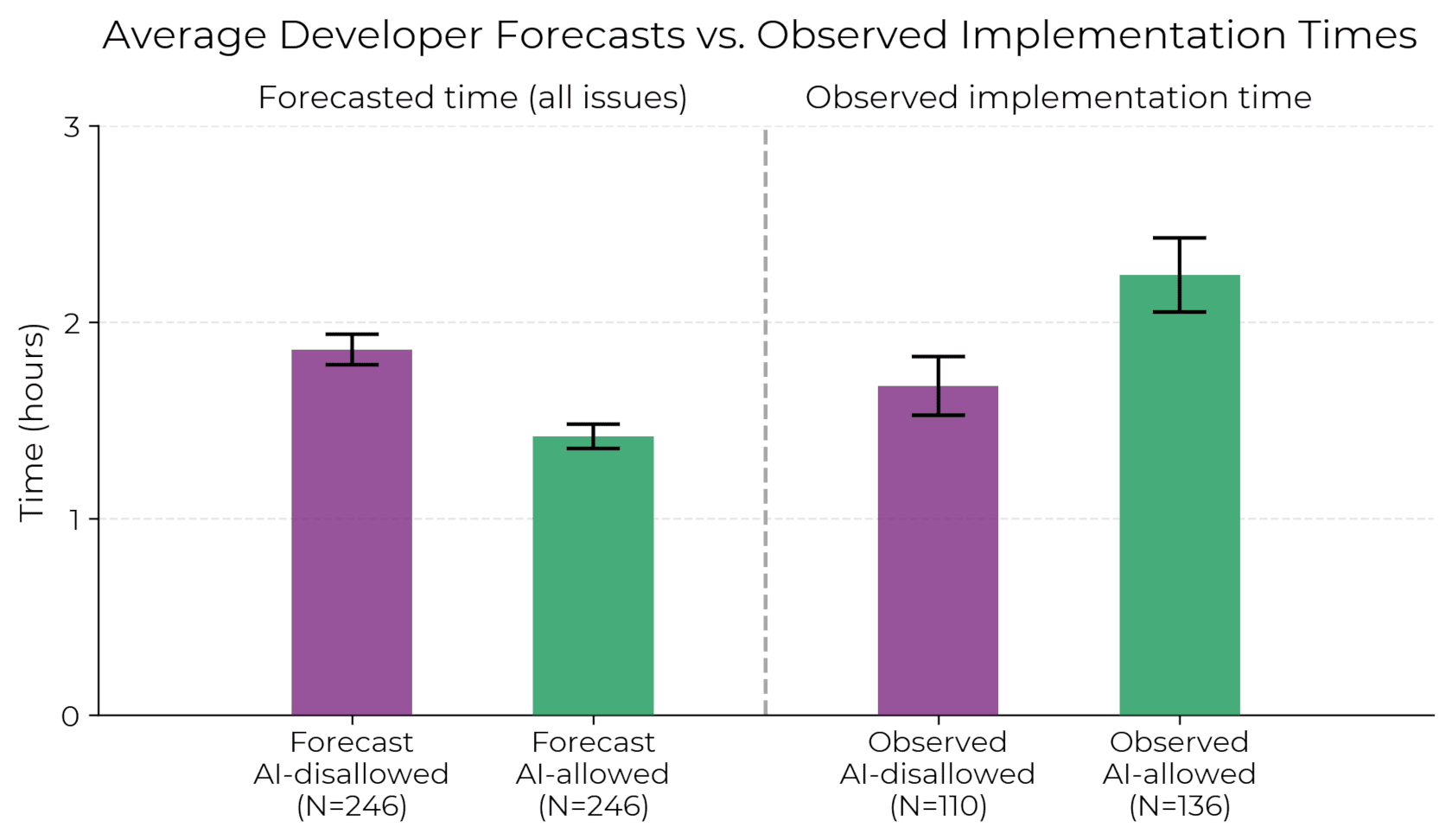
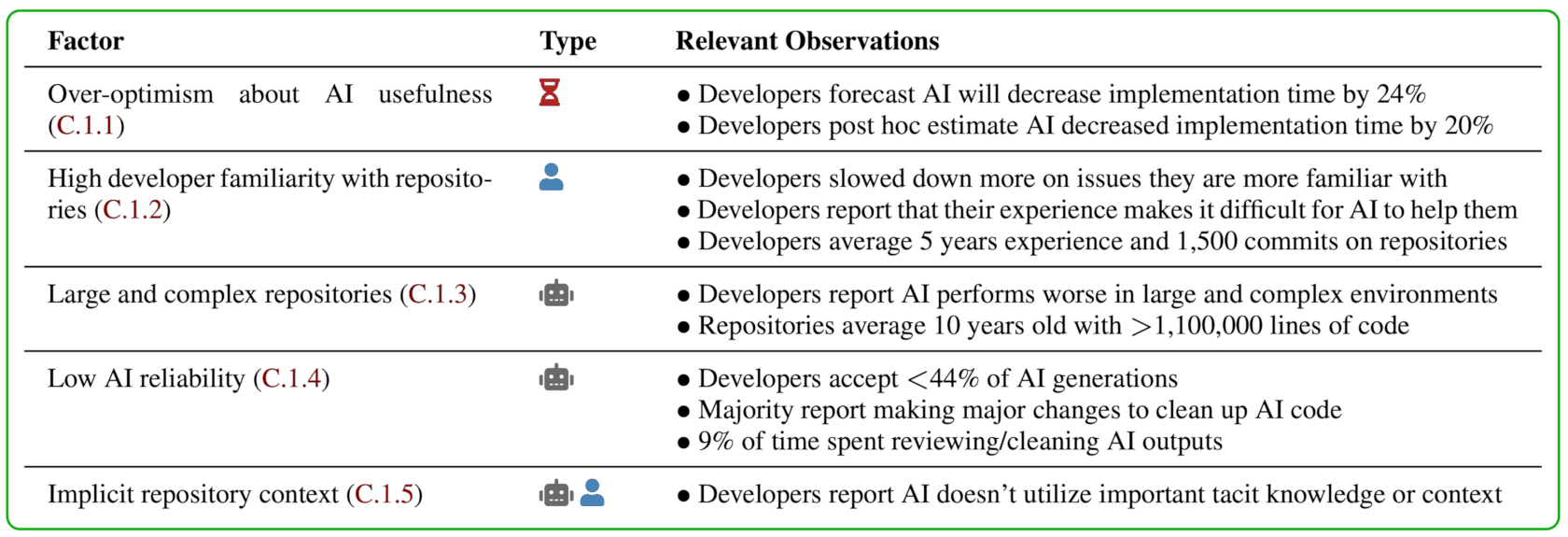
谁说 AI 只能干重复活?用对了提示词,ChatGPT 能成为你的技术合伙人。直接上 50 个实战场景,每个都附可复制的中文提示词。
一、代码生成:从零到整,AI 写完你收工
(一)语义化 HTML + CSS 组件
提示词模板:
用 [框架] 生成一个语义化的 [组件名称],包含 [组件元素],布局为 [布局方式]示例:
用 Tailwind CSS 生成一个语义化的“联系支持”表单,包含用户姓名、邮箱、问题类型和留言,布局为垂直堆叠的卡片式。效果:
<div class="max-w-md mx-auto bg-white p-6 rounded-lg shadow-md">
<form>
<div class="mb-4">
<label class="block text-gray-700 font-bold mb-2">姓名</label>
<input class="shadow appearance-none border rounded w-full py-2 px-3 text-gray-700 leading-tight focus:outline-none focus:shadow-outline">
</div>
<!-- 邮箱、问题类型、留言类似 -->
</form>
</div>(二)函数逻辑
提示词模板:
写一个 [语言] 函数,输入 [输入类型],返回 [输出类型]示例:
写一个 JavaScript 函数,输入完整姓名,返回头像字母。效果:
function getAvatarLetters(fullName) {
return fullName.split(' ').map(name => name[0].toUpperCase()).join('');
}
console.log(getAvatarLetters("张三")); // 输出 ZS(三)API 接口
提示词模板:
用 [框架] 写一个 API,功能是 [功能描述],用 [数据库] 存储数据示例:
用 Express.js 写一个 API,功能是获取当前用户资料,用 MongoDB 存储数据。效果:
const express = require('express');
const router = express.Router();
const mongoose = require('mongoose');
// 连接 MongoDB
mongoose.connect('mongodb://localhost:27017/userDB');
// 定义用户模型
const User = mongoose.model('User', new mongoose.Schema({
name: String,
email: String
}));
// 获取用户资料接口
router.get('/profile', async (req, res) => {
try {
const user = await User.findById(req.userId);
res.json(user);
} catch (err) {
res.status(500).json({ message: err.message });
}
});
module.exports = router;二、代码补全:AI 帮你“写一半,猜一半”
提示词:
补全以下代码:示例:
const animals = ["dogs", "cats", "birds", "fish"];
let animal = animals[Math.floor(Math.random() * animals.length)];
switch (animal) {
case "dogs":
console.log("Dogs are wonderful companions...");
break;
// 需要补全 cats、birds、fish 的 case
}AI 补全效果:
case "cats":
console.log("Cats are graceful and independent...");
break;
case "birds":
console.log("Birds bring color and song...");
break;
case "fish":
console.log("Fish create a peaceful underwater world...");
break;三、代码转换:用 AI 实现跨语言“翻译”
(一)语言互转
提示词模板:
把以下代码从 [源语言/框架] 转换为 [目标语言/框架]示例:
把以下代码从 JavaScript 转换为 TypeScript:function nonRepeatingWords(str1, str2) {
const map = new Map();
const res = [];
const str = str1 + " " + str2;
str.split(" ").forEach(word => {
map.has(word) ? map.set(word, map.get(word) + 1) : map.set(word, 1);
});
for (let [key, val] of map) {
if (val === 1) res.push(key);
}
return res;
}AI 转换效果:
function nonRepeatingWords(str1: string, str2: string): string[] {
const map = new Map<string, number>();
const res: string[] = [];
const str = str1 + " " + str2;
str.split(" ").forEach(word => {
map.has(word) ? map.set(word, map.get(word)! + 1) : map.set(word, 1);
});
map.forEach((val, key) => {
if (val === 1) res.push(key);
});
return res;
}(二)CSS 框架互转
提示词模板:
把以下代码从 [源 CSS 框架] 转换为 [目标 CSS 框架]示例:
把以下代码从 Bootstrap 转换为 Tailwind CSS:<div class="container">
<div class="row">
<div class="col-md-6">内容</div>
</div>
</div>AI 转换效果:
<div class="max-w-7xl mx-auto px-4 sm:px-6 lg:px-8">
<div class="flex flex-wrap -mx-4">
<div class="w-full md:w-1/2 px-4">内容</div>
</div>
</div>四、代码解释:让 AI 成为你的“代码翻译官”
提示词模板:
解释以下 [语言] 代码:示例:
const regex = /^[A-Za-z0–9._%+-]+@[A-Za-z0–9.-]+\.[A-Za-z]{2,}$/;AI 解释效果:
这是一段 JavaScript 正则表达式,用于验证电子邮件地址格式。具体规则如下:
- 允许字母(大小写)、数字、点号、下划线、百分号、加号和短横线作为用户名部分
- 必须包含 @ 符号
- 域名部分允许字母(大小写)、数字和短横线
- 最后必须有一个点号,后面跟至少两个字母(顶级域名)五、代码审查:让 AI 帮你揪出“隐形炸弹”
提示词模板:
审查以下 [语言] 代码,找出代码味道并提改进建议示例:
function processOrder(order) {
if (order.total > 1000) {
order.status = "完成";
sendEmail(order.user, "您的订单已处理");
} else {
order.status = "待审核";
sendEmail(order.manager, "新订单需要审核");
}
return order;
}AI 审查效果:
1. **硬编码问题**:1000 的金额阈值直接写在代码里,建议抽取为配置项。
2. **职责过载**:函数既处理订单状态又发送邮件,建议拆分为 updateOrderStatus 和 notifyOrderEvent。
3. **错误处理缺失**:sendEmail 如果失败没有回滚逻辑,建议加入 try-catch 并记录日志。六、代码重构:用 AI 让“老旧代码”焕然一新
(一)提升错误处理
提示词模板:
重构以下 [语言] 代码,优化错误处理和容错能力示例:
function fetchData(url) {
return fetch(url).then(res => res.json());
}AI 重构效果:
async function fetchData(url) {
try {
const res = await fetch(url);
if (!res.ok) throw new Error(`HTTP error! status: ${res.status}`);
return await res.json();
} catch (err) {
console.error("Fetch failed:", err);
Sentry.captureException(err); // 假设已集成错误监控
throw err;
}
}(二)提升响应式设计
提示词模板:
重构以下组件代码,使其适配移动、平板和桌面设备示例:
<div class="container">
<div class="product-grid">
<div class="product-card">商品 1</div>
<div class="product-card">商品 2</div>
</div>
</div>AI 重构效果:
<div class="max-w-7xl mx-auto px-4 sm:px-6 lg:px-8">
<div class="grid grid-cols-1 gap-4 sm:grid-cols-2 md:grid-cols-3 lg:grid-cols-4">
<div class="bg-white p-4 rounded-lg shadow-sm">商品 1</div>
<div class="bg-white p-4 rounded-lg shadow-sm">商品 2</div>
</div>
</div>七、Bug 检测与修复:让 AI 成为你的“除虫雷达”
提示词模板:
以下代码报错 [错误信息],帮我修复:示例:
以下代码报错 "Uncaught TypeError: Cannot read properties of undefined (reading 'name')",帮我修复:function greetUser(user) {
console.log(`Hello, ${user.name}!`);
}AI 修复效果:
function greetUser(user) {
if (!user || typeof user.name === "undefined") {
console.error("Invalid user object:", user);
return "Hello, Guest!";
}
return `Hello, ${user.name}!`;
}八、系统设计:AI 帮你画出“技术蓝图”
提示词模板:
假设你是一个系统设计专家,用 [技术栈] 设计一个 [系统名称]示例:
假设你是一个系统设计专家,用 Next.js 和 Firebase 设计一个酒店预订系统。AI 设计效果:
### 系统架构概览
1. **前端**:Next.js 负责页面渲染和路由管理,采用 Server Components 提升首屏速度。
2. **后端**:Firebase Functions 提供无服务器 API 端点,处理预订逻辑和数据验证。
3. **数据库**:Firebase Firestore 存储酒店、房间、用户和预订数据,启用 indexing 提升查询效率。
4. **认证**:Firebase Auth 管理用户登录状态,集成第三方登录(Google、Apple)。
5. **支付**:Stripe API 集成,通过 Firebase Functions 调用完成支付流程。
6. **部署**:Vercel 部署 Next.js 前端,Firebase Hosting 静态资源全球加速。
### 数据流
1. 用户浏览酒店列表 → Next.js 从 Firestore 获取数据并缓存。
2. 用户提交预订 → Firebase Function 验证库存并扣减房间数量。
3. 支付成功 → 订单状态更新为“已确认”,触发邮件通知。九、SEO 优化:AI 帮你写出“搜索引擎友好”的代码
提示词模板:
为 [网站类型] 生成一个优化 SEO 的 <head> 标签示例:
为运动员社交网站生成一个优化 SEO 的 <head> 标签AI 生成效果:
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>运动伙伴 - 连接全球运动员的社交网络</title>
<meta name="description" content="发现 nearby 运动员,组队跑步、骑行或健身,分享训练心得和赛事经验。">
<meta name="keywords" content="运动员社交, 运动组队, 健身伙伴, 跑步俱乐部">
<meta property="og:title" content="运动伙伴 - 连接全球运动员">
<meta property="og:description" content="加入 100,000+ 运动员的社交网络,找到你的运动伙伴">
<meta property="og:image" content="https://example.com/og-image.jpg">
<link rel="canonical" href="https://www.example.com">
</head>十、测试:AI 帮你写出“bulletproof”测试用例
提示词模板:
为以下 [框架] 组件写单元测试,使用 [测试框架]示例:
为以下 React 组件写单元测试,使用 Jest 和 React Testing Library:function LoginForm({ onSubmit }) {
const [email, setEmail] = useState('');
const [password, setPassword] = useState('');
return (
<form onSubmit={() => onSubmit({ email, password })}>
<input type="email" value={email} onChange={(e) => setEmail(e.target.value)} required />
<input type="password" value={password} onChange={(e) => setPassword(e.target.value)} required />
<button type="submit">登录</button>
</form>
);
}AI 生成效果:
import { render, screen, fireEvent } from '@testing-library/react';
import userEvent from '@testing-library/user-event';
import LoginForm from './LoginForm';
test('提交表单时触发 onSubmit 回调', async () => {
const mockOnSubmit = jest.fn();
render(<LoginForm onSubmit={mockOnSubmit} />);
await userEvent.type(screen.getByLabelText(/email/i), 'test@example.com');
await userEvent.type(screen.getByLabelText(/password/i), 'password123');
await userEvent.click(screen.getByRole('button', { name: /登录/i }));
expect(mockOnSubmit).toHaveBeenCalledWith({
email: 'test@example.com',
password: 'password123'
});
});十一、文档:让代码“自述其意”
提示词模板:
为以下代码写注释:示例:
function calculateDiscount(price, discountPercentage) {
return price * (1 - discountPercentage / 100);
}AI 生成效果:
/**
* 计算折扣后的价格
* @param {number} price - 原价
* @param {number} discountPercentage - 折扣百分比(例如 20 表示 8 折)
* @returns {number} 折扣后的价格
* @example calculateDiscount(100, 20) // 返回 80
*/
function calculateDiscount(price, discountPercentage) {
return price * (1 - discountPercentage / 100);
}十二、Shell 命令:用 AI 替代“人肉百度”
提示词模板:
写一个命令 [需求描述]示例:
写一个命令 删除 logs 文件夹下所有 .log 文件AI 生成效果:
find ./logs -type f -name "*.log" -exec rm -f {} \;十三、正则表达式:让 AI 成为你的“模式匹配专家”
提示词模板:
生成一个匹配 [文本模式] 的正则表达式示例:
生成一个匹配手机号码(13/15/18开头,共11位)的正则表达式AI 生成效果:
const regex = /^(13|15|18)\d{9}$/;十四、内容生成:用 AI 写出“有温度”的文案
提示词模板:
为 [网站类型] 生成 [内容类型],包含 [关键信息]示例:
为电商服装网站生成 5 个产品示例的 JSON 数据AI 生成效果:
[
{
"id": 1,
"name": "休闲棉麻衬衫",
"price": 199,
"color": "浅蓝",
"size": ["S", "M", "L"],
"imageUrl": "https://example.com/image1.jpg"
},
{
"id": 2,
"name": "修身牛仔裤",
"price": 299,
"color": "深蓝",
"size": ["28", "29", "30"],
"imageUrl": "https://example.com/image2.jpg"
}
]十五、简历与求职信:让 AI 成为你的“职业包装师”
提示词模板:
根据我的简历,写一份申请 [职位名称] 的求职信,语气 [风格]示例:
根据我的简历,写一份申请 React 前端开发工程师的求职信,语气专业但不失亲和力。AI 生成效果:
尊敬的招聘经理:
您好!我是一名热爱前端开发的工程师,附上我的简历供您审阅。
在过去 3 年中,我主导了多个中大型 React 项目,熟练运用 Hooks、Context API 和 Redux 管理状态。在 [公司名称],我通过引入代码分割和懒加载机制,将首屏加载时间从 4.2s 优化到 1.8s,提升转化率 15%。
我对您的职位描述中提到的“性能优化”和“组件库设计”特别感兴趣。我相信我的经验与贵司需求高度契合。
期待与您进一步沟通!
此致
[你的姓名]十六、面试准备:AI 成为你的“面试陪练”
提示词模板:
我即将面试 [职位名称],请帮我准备回答以下问题:示例:
我即将面试高级 React 开发工程师,请列出 10 个高频面试问题。AI 生成效果:
1. React 中的虚拟 DOM 是如何工作的?它比真实 DOM 操作快在哪里?
2. 请解释 React Hooks 的工作机制,以及为何函数组件现在可以替代类组件?
3. 在性能优化方面,您有哪些经验?请举例说明如何解决过组件反复渲染的问题。
4. 如何设计一个可扩展的组件库?您会如何处理主题切换和全局状态?
5. 您对 Suspense 和 Concurrent Mode 的理解是什么?它们解决了什么问题?十七、学习提升:AI 成为你的“技术导师”
提示词模板:
作为 [学习阶段] 的 [语言/框架] 学习者,请推荐 5 个必关注的 [学习资源类型]示例:
作为入门级的 TypeScript 学习者,请推荐 5 个必关注的 YouTube 频道。AI 生成效果:
1. **TypeScript Official** - 官方频道,发布语言更新和最佳实践。
2. **Fireship** - 以极简动画讲解 TypeScript 核心概念。
3. **Ahfarmer** - 深入浅出的进阶技巧,适合有一定基础的学习者。
4. **Code with Hlove** - 结合实际项目演示 TypeScript 在 React 中的应用。
5. **The Net Ninja** - 适合完全新手的 TypeScript 入门系列。附:50 个提示词速查表(直接复制用)
| 场景 | 提示词 |
|---|---|
| 生成组件代码 | 用 [框架] 生成一个语义化的 [组件名称],包含 [元素列表],布局为 [样式] |
| 补全代码 | 补全以下代码:const data = [{ id: 1, name: 'Item 1' }]; |
| 转换代码语言 | 把以下代码从 JavaScript 转换为 TypeScript:function add(a, b) { return a + b; } |
| 解释代码 | 解释以下 Python 代码:lambda x: x % 2 == 0 |
| 审查代码 | 审查以下 JavaScript 代码,找出潜在问题:const result = fetchData().then(data => processData(data)); |
| 重构代码提升性能 | 重构以下 JavaScript 函数,优化性能:function filterItems(items) { return items.filter(item => item.isActive); } |
| 检测 Bug | 以下代码报错 “Cannot read property of undefined”,帮我修复:console.log(user.details.profile.name); |
| 设计系统 | 用 React 和 Node.js 设计一个在线教育平台,功能包括课程购买和进度跟踪 |
| 优化 SEO | 为电商平台生成一个优化 SEO 的 HTML <head> 标签 |
| 写单元测试 | 为以下 Vue 组件写单元测试,使用 Jest:<button @click="increment">{{ count }}</button> |
| 写代码注释 | 为以下函数写注释:function calculateTotal(prices) { return prices.reduce((sum, price) => sum + price, 0); } |
| 写 Shell 命令 | 写一个命令,统计 logs 文件夹下所有错误日志的数量 |
| 生成正则表达式 | 生成一个匹配 URL 的正则表达式 |
| 生成产品示例数据 | 生成 5 个商品的 JSON 示例数据,包含 id、名称、价格和库存 |
| 写求职信 | 根据我的简历,写一封申请前端开发工程师的求职信,语气专业 |
| 准备面试问题 | 我即将面试高级 Web 开发工程师,请列出 5 个高频问题 |
| 生成 Markdown 文档 | 为我的项目生成一个 README.md 文件,包含项目简介、安装步骤和使用示例 |
| 生成随机数据 | 生成 10 个随机用户数据,包含姓名、年龄和邮箱 |
| 转换文件格式 | 将以下 JSON 数据转换为 CSV 格式 |
| 生成 API 文档 | 为我的 RESTful API 生成文档,包含端点描述和请求示例 |
| 分析代码复杂度 | 分析以下 JavaScript 代码的时间和空间复杂度 |
| 优化 SQL 查询 | 优化以下 SQL 查询,提高执行效率 |
| 生成数据库模式 | 为我的电商网站生成数据库模式,包括用户、产品和订单表 |
| 检查代码风格 | 检查以下 Python 代码是否符合 PEP 8 风格指南 |
| 生成错误处理代码 | 为以下 JavaScript 函数生成错误处理代码 |
| 优化图像加载 | 提供优化网页图像加载速度的建议 |
| 生成动画效果 | 用 CSS 生成一个淡入淡出的动画效果 |
| 创建响应式布局 | 创建一个响应式的网页布局,适配移动设备和桌面设备 |
| 生成 Webpack 配置 | 为我的 Vue.js 项目生成 Webpack 配置文件 |
| 分析网站性能 | 分析我的网站性能,并提供优化建议 |
| 生成部署脚本 | 生成一个用于部署项目的 Shell 脚本 |
| 创建用户认证系统 | 用 [框架] 创建一个用户认证系统,包括注册、登录和密码重置功能 |
| 生成邮件模板 | 为我的应用生成一个邮件模板,用于发送欢迎邮件和通知 |
| 创建数据可视化图表 | 用 [库] 创建一个数据可视化图表,展示用户增长趋势 |
| 生成国际化支持代码 | 为我的应用生成国际化支持代码,支持英语和中文 |
| 创建前端状态管理 | 用 [库] 创建一个前端状态管理系统 |
| 生成后端服务代码 | 用 [框架] 生成一个后端服务代码,包含 RESTful API 和数据库连接 |
| 创建实时聊天功能 | 用 [技术] 创建一个实时聊天功能,支持多用户在线聊天 |
| 生成缓存策略 | 为我的应用生成缓存策略,提高数据访问速度 |
| 创建搜索功能 | 用 [引擎] 创建一个搜索功能,支持全文搜索和过滤 |
| 生成图像处理代码 | 为我的应用生成图像处理代码,支持裁剪、缩放和滤镜效果 |
| 创建文件上传系统 | 用 [框架] 创建一个文件上传系统,支持多文件上传和进度显示 |
| 生成数据备份代码 | 为我的数据库生成备份代码,支持定时备份和恢复 |
| 创建数据分析报告 | 用 [工具] 创建一个数据分析报告,展示用户行为和转化率 |
| 生成 A/B 测试代码 | 为我的网站生成 A/B 测试代码,测试不同页面布局的效果 |
| 创建内容管理系统 | 用 [框架] 创建一个内容管理系统,支持文章发布和管理 |
| 生成支付集成代码 | 为我的应用生成支付集成代码,支持支付宝和微信支付 |
| 创建通知系统 | 用 [服务] 创建一个通知系统,支持邮件、短信和应用内通知 |
| 生成安全审计代码 | 为我的系统生成安全审计代码,记录用户操作和系统事件 |
| 创建性能监控系统 | 用 [工具] 创建一个性能监控系统,实时监控应用性能指标 |
| 生成日志分析代码 | 为我的应用生成日志分析代码,提取关键信息和异常 |
| 创建推荐系统 | 用 [算法] 创建一个推荐系统,根据用户行为推荐相关产品 |
| 生成数据迁移代码 | 为我的数据库生成数据迁移代码,支持从旧版本到新版本的升级 |
| 创建工作流引擎 | 用 [框架] 创建一个工作流引擎,支持任务分配和审批流程 |
| 生成智能客服代码 | 为我的网站生成智能客服代码,支持常见问题自动回答 |
| 创建数据分析模型 | 用 [库] 创建一个数据分析模型,预测用户需求和行为趋势 |