普通人或许会摇头:这不就是又一个高大上的概念吗?别急,这可能是你我真正的机会。
【调研】Vision Language Model Safety
Task-specific Attacks 的目标是针对某个具体的任务(如图像描述生成、指代表达理解等),通过精心设计的对抗样本,使得模型在该任务上产生错误的输出。例如,攻击者可能希望模型生成错误的图像描述,或者在对图像进行指代表达理解(根据给定的自然语言描述(指代表达),在图像中定位并识别出与之对应的特定目标物体或区域)时给出错误的答案。
Gao et al.提出了针对指代表达理解任务的攻击范式,展示了如何通过对抗样本误导模型在该任务上的表现。
从零开始开发一个 MCP Server!
最近,在 AI 开发领域,MCP (Model Context Protocol) 是越来越火了!
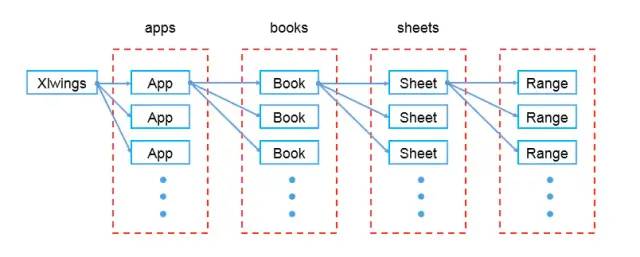
xlwings-能让 Excel 飞上天
文章转载自公众号:Python技术
人生苦短,我用 Python!
Python 作为一种脚本语言,其编程方式越来越受程序员们的青睐,同时其应用也越来越广泛,其中数据分析岗位人才需求也日益渐增,运用 Python 相关模块进行数据分析能大大提升工作效率,减轻数据分析人员的工作负担。在日常办公中,使用 Python 的场景也越来越多,很多重复的工作直接交给程序执行效率会大大提高,所以 Python 操作 Excel 也成为每一个数据分析人员的必备技能,今天的文章就一起来看看 Python 中能操作 Excel 工作表的神器。
Python 操作 Excel 模块简介
Python 操作 Excel 的模块,网上提到的模块大致有:xlwings、xlrd、xlwt、openpyxl、pyxll 等,他们提供的功能归纳起来无非有两种形式:
- 1、用 Python 读写
Excel文件,实际上就是读写有格式的文本文件,操作excel文件和操作text、csv文件没有区别,Excel文件只是用来储存数据。 - 2、除了操作数据,还可以调整
Excel文件的表格宽度、字体颜色等。另外需要提到的是用COM调用Excel的API操作Excel文档同样也是可行的,相当麻烦基本和VBA没有区别。
关于 xlwings
为什么 xlwings 能让 Excel 飞起来呢,因为xlwings支持 Excel 的读写操作。具体使用请参照官网 ,一切技术的出现都是为了满足人的惰性,因此 xlwings 能让繁琐的工作简单化、简洁化。
Xlwings 是开源且免费的工具,能够非常方便的读写 Excel 文件中的数据,并且能够进行单元格格式的修改。
xlwings 还可以和 matplotlib、numpy 以及 pandas 无缝连接,支持读写 numpy、pandas 数据类型,将 matplotlib 可视化图表导入到 excel 中。
最重要的是 xlwings 可以调用 Excel 文件中 VBA 写好的程序,也可以让 VBA调用用 Python 写的程序。
xlwings 优点
- xlwings 能够非常方便的读写
Excel文件中的数据,并且能够进行单元格格式的修改 - xlwings 可以和
Matplotlib以及Pandas无缝连接 - xlwings 可以调用
Excel文件中VBA写好的程序,也可以让VBA调用Python 写的程序。 - xlwings 开源免费,并且一直在更新
xlwings 基本操作
xlwings 安装和使用
和其他模块使用一样,xlwings 在使用之前也需要安装,本文环境为 Python 3.6 版本的 Windows 环境。
模块安装
安装xlwings的最简单方法是通过pip:
pip install xlwings
或者使用conda:
conda install xlwings
再或者
conda install -c conda-forge xlwings引入模块使用
import xlwings as xwPython to Excel
连接到工作簿最简单便捷的方法是由 xw.Book 提供:它在所有应用程序实例中查找该工作簿并返回错误,但如果同一个工作簿在多个实例中打开,要连接到活动应用程序实例中的工作簿,则需要使用 xw.books 并引用特定应用程序, 使用区别如下:
| Header1 | Header2 | Header3 |
|---|---|---|
| New book | xw.Book() | xw.books.add() |
| Unsaved book | xw.Book(‘Book1’) | xw.books[‘Book1’] |
| UBook by (full)name | xw.Book(r’D:/test/file.xlsx’) | xw.books.open(r’D:/test/file.xlsx’) |
注:在 Windows 上指定文件路径时,应该通过在字符串前放置一个 r 来使用原始字符串,或者使用双反斜杠:D:\Test\file.xlsx
Excel 活动对象
# 活动应用程序(即Excel实例)
app = xw.apps.active
# 活动工作簿
wb = xw.books.active # 在活动app
wb = app.books.active # 在特定app
# 活动工作表
sht = xw.sheets.active # 在活动工作簿
sht = wb.sheets.active # 在特定工作簿
# 活动工作表的Range
xw.Range('A1') #在活动应用程序的活动工作簿的活动表上基本操作
以下代码展示相关基本操作:
- 打开表格
- 引用工作表
- 引用单元格
- 引用区域
- 写入数据(数据写入默认按照行写入,如果要指定相应的列写入则需要添加相应参数,指定参数为:transpose = True)
- 读取数据
import xlwings as xw
# 打开表格
file_path = r'D:/test/file.xlsx'
xw.Book(file_path) # 固定打开表格
xw.books.open(file_path) # 频繁打开表格
# 引用工作表
sht = wb.sheets['sheet1']
# 引用单元格
rng = xw.Range('A1')
# rng = sht[0,0] # 此代码第一行的第一列即a1,相当于 pandas 的切片
# 引用区域
rng = sht.range('a1:a5')
# rng = sht['a1:a5']
# rng = sht[:5,0]
# 写入数据
sht.range('a1').value = 'Hello Excel' # 指定一个单元格写入数据
# 按行写入数据
sht.range('a1').value = [1, 2, 3, 4,5,6,7,8]
# 按照列写入数据
sht.range('a2').options(transpose=True).value = [2, 3, 4, 5, 6, 7, 8]
# 按照二维列表的方式写入数据
sht.range('a9').expand('table').value = [['a', 'b', 'c'], ['d', 'e', 'f'], ['g', 'h', 'i'],['j', 'k', 'l']]
# 读取写入的数据
print(sht.range('A1:D5').value)xlwings 结合 matplotlib
xlwings 结合 Matplotlib 使用能讲图画贴入到 Excel 中,具体使用 pictures.add() 方法就可以很容易地将Matplotlib图作为图片粘贴到表格中。详细代码如下:
fig = plt.figure() # 指定画布
# plt.plot([1, 2, 3, 4, 5])
plt.plot([36,5,3,25,78])
plt.plot([9,10,31,45])
plt.plot([6,14,45,31])
sht = xw.Book(r'G:/test/test.xlsx').sheets[0]
sht.pictures.add(fig, name='myplt', update=True) 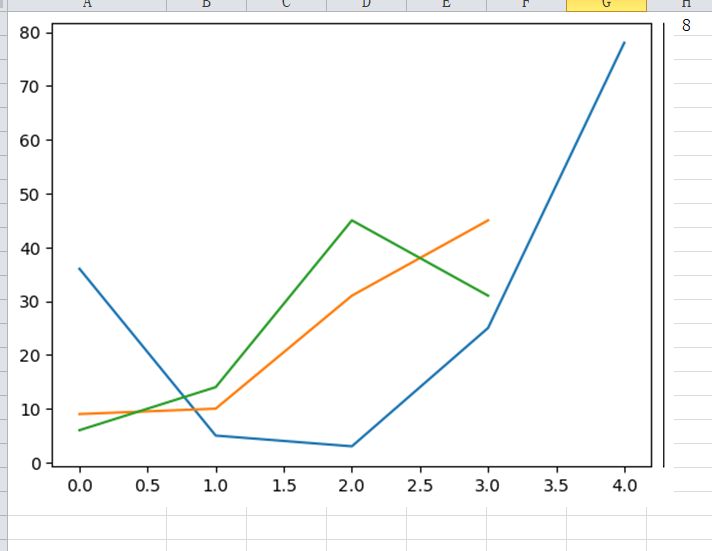
总结
磨刀不误砍柴工,今天的文章主要是操作 Excel 的工具 xlwings 介绍,大家都用工具操练起来,好好修炼如何拧好螺丝的内功,奥利给!
以上就是W3Cschool编程狮关于xlwings-能让 Excel 飞上天的相关介绍了,希望对大家有所帮助。
学C语言和学C++它有毛关系吗?
文章转载自公众号:CodeSheep,作者hansonwong99
最近收到读者读者小伙伴所提的问题,我顺手截了两个图。


实不相瞒,这类问题之前也经常看到,但是我忘了截图了。
每次遇到这种问题,看起来很简单,但是打字一时半会还真说不清,想想今天周末了,写一篇文章来统一聊聊吧,如果小伙伴们有不同看法,也欢迎批评指正。
C和C++到底是什么关系?
首先 C++ 和 C 语言本来就是两种不同的编程语言,但 C++ 确实是对 C 语言的扩充和延伸,并且对 C 语言提供后向兼容的能力。对于有些人说的 C++ 完全就包含了 C 语言的说法还是有点别扭的。
C++ 一开始被本贾尼·斯特劳斯特卢普(Bjarne Stroustrup)发明时,起初被称为“C with Classes”,即「带类的C」。很明显它是在 C 语言的基础上扩充了类class等面向对象的特性和机制。但是后来经过一步步修订和很多次演变(如下图所示),最终才形成了现如今这个支持一系列重大特性的庞大编程语言。

就像经典书籍《Effective C++》一开头就说的,现如今我们提到 C++ ,都应该视其为一个庞大的「语言联邦」,最起码包含如下几个重要的组成部分:
- 面向过程编程
- 面向对象编程
- 泛型编程
- 元编程
- 函数式编程
- STL标准库
这其中的第一部分「面向过程编程」,正是C++提供的向后兼容C语言的部分,所以你能看到市面上在售的大部分讲C++编程的书,一开始前几个章节基本都是在讲「面向过程编程」的内容,包括但不限于:数据类型、变量、运算符、表达式、语句、判断、循环、函数、指针等等这些内容。
不学C语言能直接学C++吗?
还是像前面所说,C++编程语言的第一大重要组成部分就是「面向过程编程」,而这正是C语言老大哥的领域。即使没有学过C语言,一上来就直接学习C++的小伙伴,应该也难逃『面向过程』这一部分的内容。因为市面上在售的大部分讲C++编程的书,开始的章节都在讲「面向过程编程」的内容。
从理论上来说,学C++前并不一定非得学C语言,但是有C语言底子再去学C++往往更具优势,最起码「面向过程编程」这一部分内容能够轻车熟路。
但是遗憾的是,即使是《C++ Primer》这种700多页厚的权威C++书籍,开头也只有很少一部分在讲「面向过程编程」,所以对于面向过程这一部分的讲述是肯定没有专门讲C语言的书籍剖析得细致和全面的,不然也不会有侧重讲指针相关的《C和指针》等这类书籍的出现了。
所以个人建议是在学C++之前,C语言的基础还是尽量要夯实,肯定是有帮助的。
C学得好的,学C++是否更具优势?
是的。
最起码学C++时,里面的「面向过程」这一部分内容可以说轻车熟路了。
C++能替代C语言吗?
既然C++这么强大,包含这么多模块和范式,而且也几乎包含了C语言面向过程这一部分的内容,那为啥还要学C语言呢?都直接学习C++它不香嘛?
是的,C++很强大没错,但那些强大的范式和机制本身带来的包袱就不轻,也确实给学习者造成了不小的负担,甚至劝退了很多人。
而反观C语言,C语言本身就是一个把能力、性能、效率和学习成本权衡得非常极致的一种编程语言,以至于大学阶段必开的程序设计课程里基本都有C语言的身影。
而且C语言的应用领域极度广泛,上到操作系统底层的原生接口,下到普通的应用层开发,C语言都有着不小的功劳。以至于这么多年来,在Tiobe编程语言排行榜里,C语言都是居高位不下。

而且2020开年C语言重回巅峰王座,一举夺得「2019年度编程语言」。虽然这只是一个看起来很无聊的排名,但多多少少能说明一些事情。

所以无论是过去,现在,甚至是未来,近50岁的C语言老将军依然永不为奴。
只有C++这种面向对象的语言才适合大型项目吗?
C++的出现的确是为了更方便地开发大型应用程序,毕竟面向对象编程里的很多重要思想和机制都对大型项目和复杂系统所要求的项目工程化、代码复用性/扩展性/可维护性等提供了强大的支撑。
但是摆在眼前的事实告诉我们,即便是C语言,也照样可以构建出极其复杂的系统和软件。上到Linux这种旷世伟大的操作系统内核,小到被各个公司重度依赖的Redis、Nginx等开源软件或框架,都是C语言的代表作品。
所以有时候我们不得不承认的是,大家所说的抽象能力更多的是看写这个程序的人,而并非编程语言本身。
小 结
好啦,扯得有点多了,总结一下就是:
- C 语言和 C++ 是两个不同的编程语言,只不过内容上有一定的重叠;
- C 语言是一门很强大的编程语言,我觉得有机会还是要学一下;
- 一般来说,有了 C 语言的基础,上手 C++ 也会更快;
- C++ 和C 各有各的选用考虑和应用场景,并没有谁更好一说,学不学看自己的兴趣和自身技术发展的考量
以上就是W3Cschool编程狮关于学C语言和学C++它有毛关系吗?的相关介绍了,希望对大家有所帮助。
未读消息(小红点),前端 与 RabbitMQ 实时消息推送实践,贼简单~
文章转载自公众号:程序员内点事
前几天粉丝群里有个小伙伴问过:web 页面的未读消息(小红点)怎么实现比较简单,刚好本周手头有类似的开发任务,索性就整理出来供小伙伴们参考,没准哪天就能用得上呢。

web 端实时消息推送,常用的实现方式比较多,但万变不离其宗,底层基本上还是依赖于 websocket,MQTT 协议也不例外。
RabbitMQ 搭建
RabbitMQ的基础搭建就不详细说了,自行百度一步一步搞问题不大,这里主要说一下两个比较重要的配置。
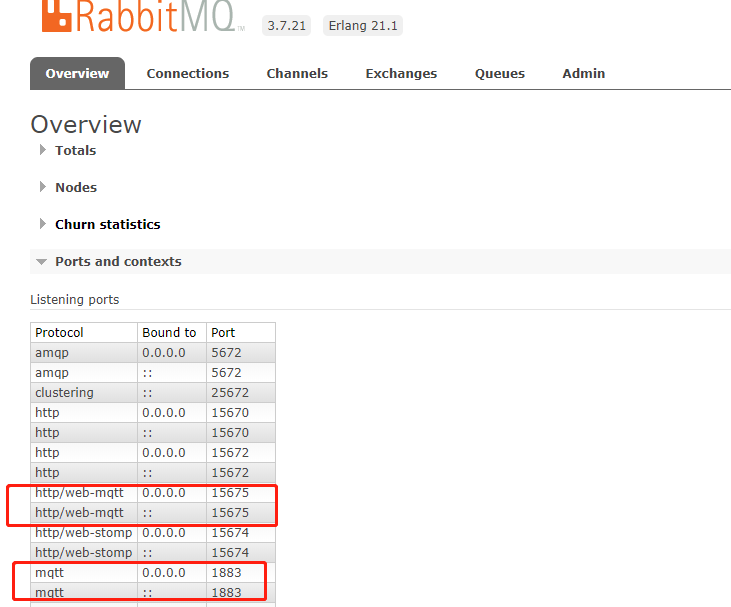
1、开启 mqtt 协议
默认情况下RabbitMQ是不开启MQTT 协议的,所以需要我们手动的开启相关的插件,而RabbitMQ的MQTT 协议分为两种。
第一种 rabbitmq_mqtt 提供与后端服务交互使用,对应端口1883。
rabbitmq-plugins enable rabbitmq_mqtt 第二种 rabbitmq_web_mqtt 提供与前端交互使用,对应端口15675。
rabbitmq-plugins enable rabbitmq_web_mqtt 在 RabbitMQ 管理后台看到如下的显示,就表示MQTT 协议开启成功,到这中间件环境就搭建完毕了。
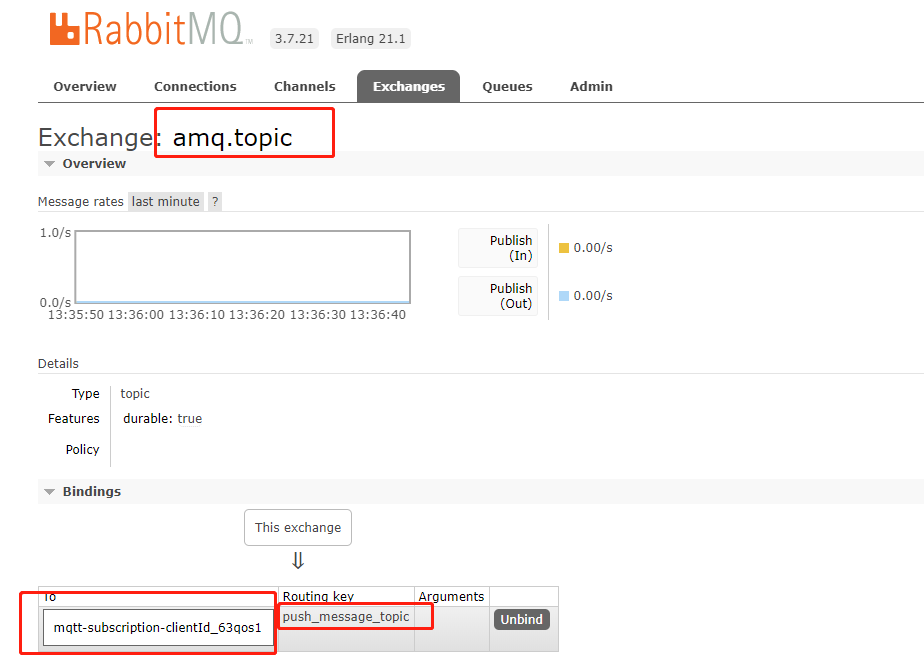
使用MQTT 协议默认的交换机 Exchange 为 amp.topic,而我们订阅的主题会在 Queues 注册一个客户端队列,路由 Routing key 就是我们设置的主题。
服务端消息发送
web 端实时消息推送一般都是单向的推送,前端接收服务端推送的消息显示即可,所以就只实现消息发送即可。
1、mqtt 客户端依赖包
引入 spring-integration-mqtt、org.eclipse.paho.client.mqttv3两个工具包实现
<!--mqtt依赖包-->
<dependency>
<groupId>org.springframework.integration</groupId>
<artifactId>spring-integration-mqtt</artifactId>
</dependency>
<dependency>
<groupId>org.eclipse.paho</groupId>
<artifactId>org.eclipse.paho.client.mqttv3</artifactId>
<version>1.2.0</version>
</dependency>2、消息发送者
消息的发送比较简单,主要是应用到 @ServiceActivator 注解,需要注意messageHandler.setAsync属性,如果设置成 false,关闭异步模式发送消息时可能会阻塞。
@Configuration
public class IotMqttProducerConfig {
@Autowired
private MqttConfig mqttConfig;
@Bean
public MqttPahoClientFactory mqttClientFactory() {
DefaultMqttPahoClientFactory factory = new DefaultMqttPahoClientFactory();
factory.setServerURIs(mqttConfig.getServers());
return factory;
}
@Bean
public MessageChannel mqttOutboundChannel() {
return new DirectChannel();
}
@Bean
@ServiceActivator(inputChannel = "iotMqttInputChannel")
public MessageHandler mqttOutbound() {
MqttPahoMessageHandler messageHandler = new MqttPahoMessageHandler(mqttConfig.getServerClientId(), mqttClientFactory());
messageHandler.setAsync(false);
messageHandler.setDefaultTopic(mqttConfig.getDefaultTopic());
return messageHandler;
}
} MQTT 对外提供发送消息的 API 时,需要使用 @MessagingGateway注解,去提供一个消息网关代理,参数 defaultRequestChannel 指定发送消息绑定的channel。
可以实现三种API接口,payload 为发送的消息,topic 发送消息的主题,qos 消息质量。
@MessagingGateway(defaultRequestChannel = "iotMqttInputChannel")
public interface IotMqttGateway {
// 向默认的 topic 发送消息
void sendMessage2Mqtt(String payload);
// 向指定的 topic 发送消息
void sendMessage2Mqtt(String payload,@Header(MqttHeaders.TOPIC) String topic);
// 向指定的 topic 发送消息,并指定服务质量参数
void sendMessage2Mqtt(@Header(MqttHeaders.TOPIC) String topic, @Header(MqttHeaders.QOS) int qos, String payload);
}前端消息订阅
前端使用与服务端对应的工具 paho-mqtt mqttws31.js实现,实现方式与传统的 websocket 方式差不多,核心方法 client = new Paho.MQTT.Client 和 各种监听事件,代码比较简洁。
注意:要保证前后端 clientId的全局唯一性,我这里就简单用随机数解决了
<script type="text/javascript">
// mqtt协议rabbitmq服务
var brokerIp = location.hostname;
// mqtt协议端口号
var port = 15675;
// 接受推送消息的主题
var topic = "push_message_topic";
// mqtt连接
client = new Paho.MQTT.Client(brokerIp, port, "/ws", "clientId_" + parseInt(Math.random() * 100, 10));
var options = {
timeout: 3, //超时时间
keepAliveInterval: 30,//心跳时间
onSuccess: function () {
console.log(("连接成功~"));
client.subscribe(topic, {qos: 1});
},
onFailure: function (message) {
console.log(("连接失败~" + message.errorMessage));
}
};
// 考虑到https的情况
if (location.protocol == "https:") {
options.useSSL = true;
}
client.connect(options);
console.log(("已经连接到" + brokerIp + ":" + port));
// 连接断开事件
client.onConnectionLost = function (responseObject) {
console.log("失去连接 - " + responseObject.errorMessage);
};
// 接收消息事件
client.onMessageArrived = function (message) {
console.log("接受主题: " + message.destinationName + "的消息: " + message.payloadString);
$("#arrivedDiv").append("<br/>"+message.payloadString);
var count = $("#count").text();
count = Number(count) + 1;
$("#count").text(count);
};
// 推送给指定主题
function sendMessage() {
var a = $("#message").val();
if (client.isConnected()) {
var message = new Paho.MQTT.Message(a);
message.destinationName = topic;
client.send(message);
}
}
</script>测试
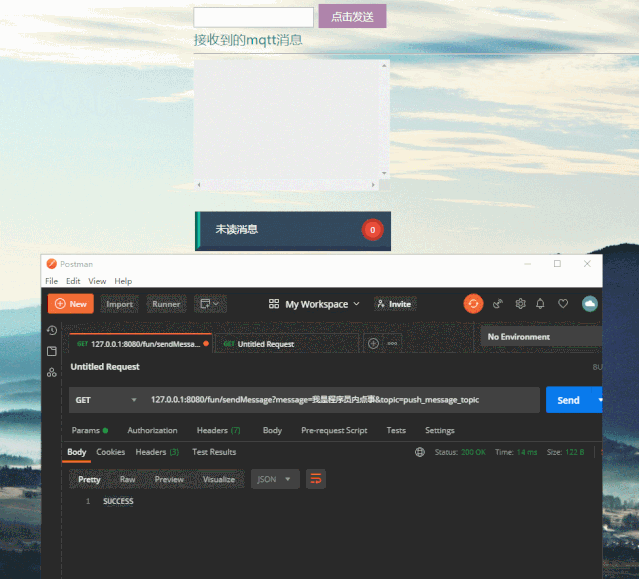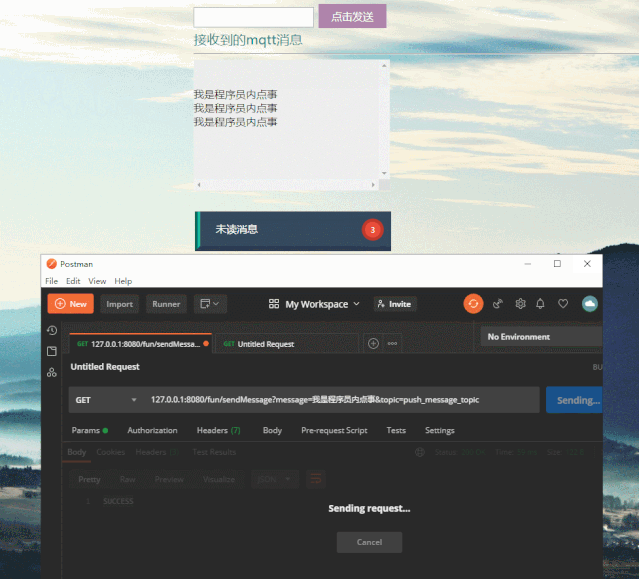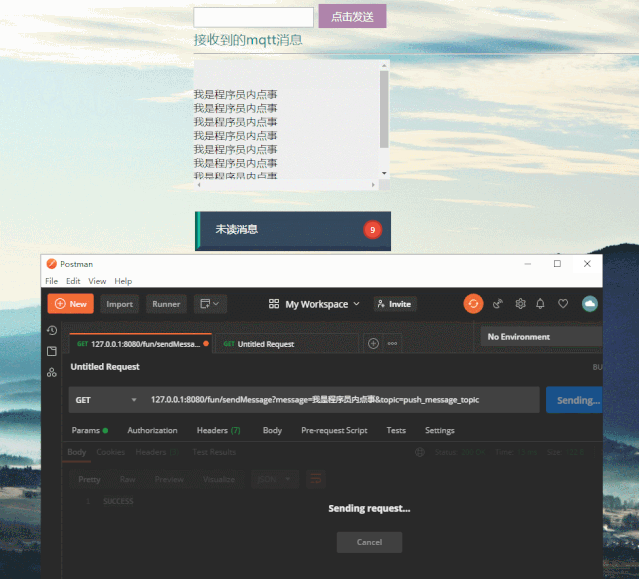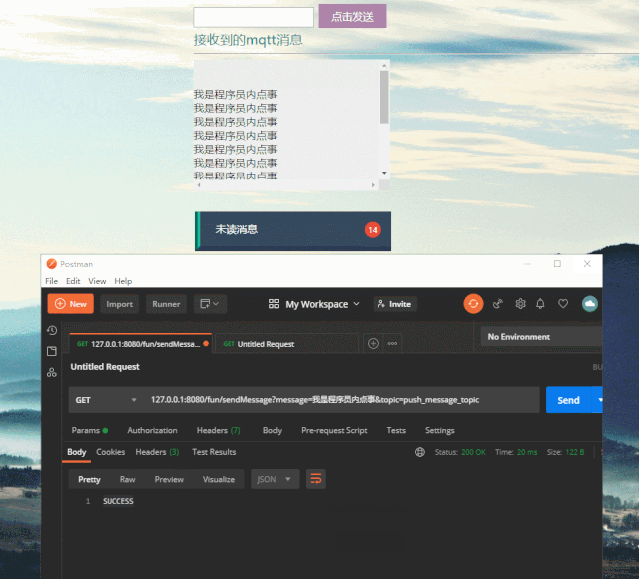
前后端的代码并不多,接下来我们测试一下,弄了个页面看看效果。
首先用 postman 模拟后端发送消息
http://127.0.0.1:8080/fun/sendMessage?message=我是程序员内点事&topic=push_message_topic 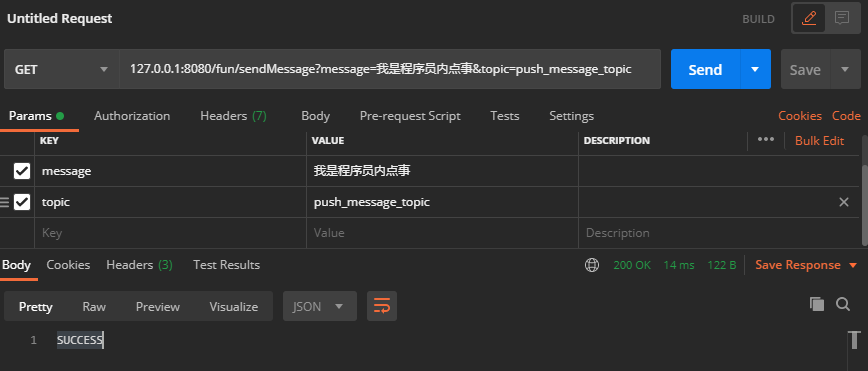
再看一下前端订阅消息的效果,看到消息被实时推送到了前端,这里只做了未读消息数量统计,一般还会做未读消息详情列表。
总结
未读消息是一个十分常见的功能,不管是 web端还是移动端系统都是必备的模块,MQTT 协议只是其中的一种实现方式,还是有必要掌握一种方法。具体用什么工具实现还是要看具体的业务场景和学习成本,像我用RabbitMQ 做还考虑到一些运维成本在里边。
以上就是W3Cschool编程狮关于未读消息(小红点),前端 与 RabbitMQ 实时消息推送实践,贼简单~的相关介绍了,希望对大家有所帮助。
基于 Vue 技术栈的微前端方案实践
文章来源于公众号:程序员成长指北 ,作者mcuking
前几天看到了 微前端在美团外卖的实践,感觉和笔者所在团队实践了一年多的微前端方案非常类似,只不过我们是基于 Vue 技术栈的,所以也想总结一篇文章分享给大家。因为笔者文笔不算太好,其中借用了一些美团文章的一些总结性的文字,还请见谅哦~
背景介绍
对于大型前端项目,比如公司内部管理系统(一般包括 OA、HR、CRM、会议预约等系统),如果将所有业务放在一个前端项目里,随着业务功能不断增加,就会导致如下这些问题:
- 代码规模庞大,导致编译时间过长,开发、打包速度越来越慢
- 项目文件越来越多,导致查找相关文件变得越来越困难
- 某一个业务的小改动,导致整个项目的打包和部署
方案介绍
preload-routes 和 async-routes 是目前笔者所在团队使用的微前端方案,最终会将整个前端项目拆解成一个主项目和多个子项目,其中两者作用如下:
- 主项目:用于管理子项目的路由切换、注册子项目的路由和全局 Store 层、提供全局库和方法
- 子项目:用于开发子业务线业务代码,一个子项目对应一个子业务线,并且包含两端(PC + Mobile)代码和复用层代码(项目分层中的非视图层)
结合笔者之前的采用分层架构实现复用非视图代码的方式(感兴趣的话请参考笔者之前的文章 前端分层架构实践心得),完整的方案如下:
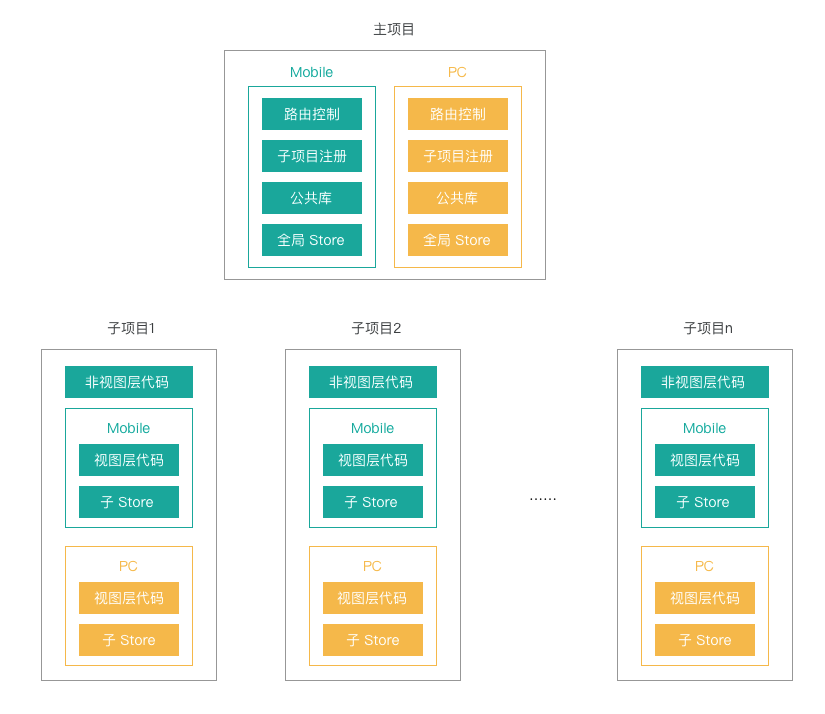
如图所示,将整个前端项目按照业务线拆分出多个子项目,每个子项目都是独立的仓库,只包含了单个业务线的代码,可以进行独立开发和部署,降低了项目维护的复杂度。
采用这套方案,使得我们的前端项目不仅保有了横向上(多个子项目)的扩展性,又拥有了纵向上(单个子项目)的复用性。那么这套方案具体是怎么实现的呢?下面就详细说明方案的实现机制。
在讲解之前,首先明确下这套方案有两种实现方式,一种是预加载路由,另一种是懒加载路由,可以根据实际需求选择其中一个即可。接下来就分别介绍这两种方式的实现机制。
实现机制
预加载路由方式
preload-routes
1.子项目按照 vue-cli 3 的 library 模式进行打包,以便后续主项目引用
注:在 library 模式中, Vue 是外置的。这意味着包中不会有 Vue ,即便你在代码中导入了 Vue 。如果这个库会通过一个打包器使用,它将尝试通过打包器以依赖的方式加载 Vue ;否则就会回退到一个全局的 Vue 变量。
2.在编译主项目的时候,通过 InsertScriptPlugin 插件将子项目的入口文件 main.js 以 script 标签形式插入到主项目的 html 中
注:务必将子项目的入口文件 main.js 对应的 script 标签放在主项目入口文件 app.js 的 script 标签之上,这是为了确保子项目的入口文件先于主项目的入口文件代码执行,接下来的步骤就会明白为什么这么做。
再注:本地开发环境下项目的入口文件编译后的 main.js 是保存在内存中的,所以磁盘上看不见,但是可以访问。
InsertScriptPlugin 核心代码如下:
compiler.hooks.compilation.tap('InsertScriptWebpackPlugin', compilation => {
compilation.hooks.htmlWebpackPluginBeforeHtmlProcessing.tap(
'InsertScriptWebpackPlugin',
htmlPluginData => {
const {
assets: { js }
} = htmlPluginData;
// 将传入的 js 以 script 标签形式插入到 html 中
// 注意:需要将子项目的入口文件 main.js 放在主项目入口文件 app.js 之前,因为需要子项目提前将自己的 route list 注册到全局上
js.unshift(...self.files);
}
);
}); 3.主项目的 html 要访问子项目里的编译后的 js / css 等资源,需要进行代理转发
- 如果是本地开发时,可以通过 webpack 提供的 proxy,例如:
const PROXY = {
'/app-a/': {
target: 'http://localhost:10241/'
}
};- 如果是线上部署时,可以通过 nginx 转发或者将打包后的主项目和子项目放在一个文件夹中按照相对路径引用。
4.当浏览器解析 html 时,解析并执行到子项目的入口文件 main.js,将子项目的 route list 注册到 Vue.share.routes 上,以便后续主项目将其合并到总的路由中。
子项目 main.js 代码如下:(为了尽量减少首次主项目页面渲染时加载的资源,子项目的入口文件建议只做路由挂载)
import Vue from 'vue';
import routes from './routes';
const share = (Vue.__share__ = Vue.__share__ || {});
const routesPool = (share.routes = share.routes || {});
// 将子项目的 route list 挂载到 Vue.__share__.routes 上,以便后续主项目将其合并到总的路由中
routesPool[process.env.VUE_APP_NAME] = routes; 5.继续向下解析 html,解析并执行到主项目 main.js 时,从 Vue.share.routes 获取所有子项目的 route list,合并到总的路由表中,然后初始化一个 vue-router实例,并传入到 new Vue 内
相关关键代码如下
// 从 Vue.__share__.routes 获取所有子项目的 route list,合并到总的路由表中
const routes = Vue.__share__.routes;
export default new Router({
routes: Object.values(routes).reduce((acc, prev) => acc.concat(prev), [
{
path: '/',
redirect: '/app-a'
}
])
}); 到此就实现了单页面应用按照业务拆分成多个子项目,直白来说子项目的入口文件 main.js 就是将主项目和子项目联系起来的桥梁。
另外如果需要使用 vuex,则和 vue-router 的顺序恰好相反(先主项目后子项目):
1.首先在主项目的入口文件中初始化一个 store 实例 new Vuex.Store,然后挂在到 Vue.__share__.store 上
2.然后在子项目的 App.vue 中获取到 Vue.__share__.store 并调用 store.registerModule(‘app-x', store),将子项目的 store 作为子模块注册到 store 上
懒加载路由方式
async-routes
懒加载路由,顾名思义,就是说等到用户点击要进入子项目模块,通过解析即将跳转的路由确定是哪一个子项目,然后再异步去加载该子项目的入口文件 main.js(可以通过 systemjs 或者自己写一个动态创建 script 标签并插入 body 的方法)。加载成功后就可以将子项目的路由动态添加到主项目总的路由里了。
1.主项目 router.js 文件中定义了在 vue-router 的 beforeEach 钩子去拦截路由,并根据即将跳转的路由分析出需要哪个子项目,然后去异步加载对应子项目入口文件,下面是核心代码:
const cachedModules = new Set();
router.beforeEach(async (to, from, next) => {
const [, module] = to.path.split('/');
if (Reflect.has(modules, module)) {
// 如果已经加载过对应子项目,则无需重复加载,直接跳转即可
if (!cachedModules.has(module)) {
const { default: application } = await window.System.import(
modules[module]
);
if (application && application.routes) {
// 动态添加子项目的 route-list
router.addRoutes(application.routes);
}
cachedModules.add(module);
next(to.path);
} else {
next();
}
return;
}
}); 2.子项目的入口文件 main.js 仅需要将子项目的 routes 暴露给主项目即可,代码如下:
import routes from './routes';
export default {
name: 'javascript',
routes,
beforeEach(from, to, next) {
console.log('javascript:', from.path, to.path);
next();
}
}; 注意:这里除了暴露 routes 方法外,另外又暴露了 beforeEach 方法,其实就是为了支持通过路由守卫对子项目进行页面权限限制,主项目拿到这个子项目的 beforeEach,可以在 vue-router 的 beforeEach 钩子执行,具体代码请参考 async-routes。
除了主项目和子项目的交互方式不同,代理转发子项目资源、vuex store 注册等和上面的预加载路由完全一致。
优缺点
下面谈下这套方案的优缺点:
优点
- 子项目可单独打包、单独部署上线,提升了开发和打包的速度
- 子项目之间开发互相独立,互不影响,可在不同仓库进行维护,减少的单个项目的规模
- 保持单页应用的体验,子项目之间切换不刷新
- 改造成本低,对现有项目侵入度较低,业务线迁移成本也较低
- 保证整体项目统一一个技术栈
缺点:
部分问题解答
1.如果子项目代码更新后,除了打包部署子项目之外,还需要打包部署主项目吗?
不需要更新部署主项目。这里有个 trick 上文忘记提及,就是子项目打包后的入口文件并没有加上 chunkhash,直接就是 main.js(子项目其他的 js 都有 chunkhash)。也就是说主项目只需要记住子项目的名字,就可以通过 subapp-name/main.js 找到子项目的入口文件,所以子项目打包部署后,主项目并不需要更新任何东西。
2.针对第二个问题中子项目入口文件 main.js 不使用 chunkhash 的话,如何防止该文件始终被缓存呢?
可以在静态资源服务器端针对子项目入口文件设置强制缓存为不缓存,下面是服务器为 nginx 情况的相关配置:
location / {
set $expires_time 7d;
...
if ($request_uri ~* \/(contract|meeting|crm)-app\/main.js(\?.*)?$) {
# 针对入口文件设置 expires_time -1,即expire是服务器时间的 -1s,始终过期
set $expires_time -1;
}
expires $expires_time;
...
}待完善
- 可以通过写一个脚手架来自动生成子项目以及相关的配置
结尾
如果没有在一个大型前端项目中使用多个技术栈的需求,还是很推荐笔者目前团队实践的这个方案的。另外如果是 React 技术栈,也是可以按照这种思想去实现类似的方案的。
以上就是W3Cschool编程狮关于基于 Vue 技术栈的微前端方案实践的相关介绍了,希望对大家有所帮助。
13个超实用的JavaScript数组操作技巧
文章来源于公众号:字节前端 ,作者子非鱼
数组是JS最常见的概念之一,它为我们提供了处理存储数据的许多可能性。考虑到数组是 JavaScript 语言中最基本的概念之一,您可能在编程开始之初就了解到了这一点,在本文中,我将向您展示一些您可能不知道并且可能非常有用的技巧。这些技巧非常有助于我们编码!让我们开始吧。
1. 数组去重
这里只展示两种可行的方法, 一种是实用.from()方法, 第二种是实用扩展运算符...
let fruits = ["banana", "apple", "orange", "watermelon", "apple", "orange", "grape", "apple"]
// 第一种方法
let uniqueFruits = Array.from(new Set(fruits))
//第二种方法
let uniqueFruits2 = [...new Set(fruits)]2 .替换数组中的特定值
我们可用使用.splice(start, value to remove, valueToAdd),并在其中传递三个参数,这些参数指定了要在哪里开始修改,要更改多少个值以及新增加的值。
let fruits = ["banana", "apple", "orange", "watermelon", "apple", "orange", "grape", "apple"]
fruits.splice(0, 2, "potato", "tomato")
console.log(fruits) // returns ["potato", "tomato", "orange", "watermelon", "apple", "orange", "grape", "apple"]3. 不使用.map()映射数组
也许每个人都知道数组的.map()方法,但是可以使用另一种方案来获得相似的效果,并且代码非常简洁。这里我们可用.from()方法。
let friends = [
{ name: 'John', age: 22 },
{ name: 'Peter', age: 23 },
{ name: 'Mark', age: 24 },
{ name: 'Maria', age: 22 },
{ name: 'Monica', age: 21 },
{ name: 'Martha', age: 19 },
]
let friendsNames = Array.from(friends, ({name}) => name)
console.log(friendsNames) //returns ["John", "Peter", "Mark", "Maria", "Monica", "Martha"]4. 清空数组
您是否有一个包含所有元素的数组,但出于任何目的都需要对其进行清理,并且不想一个一个地删除元素?只需一行代码即可完成。要清空数组,您需要将数组的长度设置为0,仅此而已!
let fruits = ["banana", "apple", "orange", "watermelon", "apple", "orange", "grape", "apple"];
fruits.length = 0;
console.log(fruits); // returns []5. 数组转对象
碰巧我们有一个数组,但是出于某种目的,我们需要一个具有此数据的对象,而将数组转换为对象的最快方法是使用众所周知的扩展运算符...。
let fruits = ["banana", "apple", "orange", "watermelon"];
let fruitsObj = {...fruits};
console.log(fruitsObj) // returns {0: “banana”, 1: “apple”, 2: “orange”, 3: “watermelon”, 4: “apple”, 5: “orange”, 6: “grape”, 7: “apple”}6. 用数据填充数组
在某些情况下,当我们创建一个数组时,我们想用一些数据填充它,或者我们需要一个具有相同值的数组,在这种情况下,.fill()方法提供了一种简单而干净的解决方案。
let newArray = new Array(10).fill('1')
console.log(newArray) // returns [“1”, “1”, “1”, “1”, “1”, “1”, “1”, “1”, “1”, “1”, “1”]7. 合并数组
除了使用.concat()方法,我们也可以使用扩展运算符...。
var fruits = [“apple”, “banana”, “orange”];
var meat = [“poultry”, “beef”, “fish”];
var vegetables = [“potato”, “tomato”, “cucumber”];
var food = […fruits, …meat, …vegetables];
console.log(food); // [“apple”, “banana”, “orange”, “poultry”, “beef”, “fish”, “potato”, “tomato”, “cucumber”]8. 求数组的交集
这也是您在任何 JavaScript 面试中面临的最普遍的挑战之一,因为它展示了你是否可以使用数组方法以及你的逻辑是什么。
var numOne = [0, 2, 4, 6, 8, 8];
var numTwo = [1, 2, 3, 4, 5, 6];
var duplicatedValues = [...new Set(numOne)].filter(item=> numTwo.includes(item))
console.log(duplicatedValues); // returns [2, 4, 6]9. 从数组中删除虚值
首先,让我们定义虚值。在 JavaScript 中,虚值有false, 0, „”, null, NaN, undefined。现在,我们可以找到如何从数组中删除此类值。为此,我们将使用.filter()方法。
var mixedArr = [0, “blue”, “”, NaN, 9, true, undefined, “white”, false];
var trueArr = mixedArr.filter(Boolean);
console.log(trueArr); // returns [“blue”, 9, true, “white”]10. 从数组中获取随机值
有时我们需要从数组中随机选择一个值。为了以简单,快速和简短的方式创建它并保持我们的代码整洁,我们可以根据数组长度获取随机索引号。让我们看一下代码:
var colors = [“blue”, “white”, “green”, “navy”, “pink”, “purple”, “orange”, “yellow”, “black”, “brown”];
var randomColor = colors[(Math.floor(Math.random() * (color.length)))]11. 反转数组
var colors = [“blue”, “white”, “green”, “navy”, “pink”, “purple”, “orange”, “yellow”, “black”, “brown”];
var reversedColors = colors.reverse();
console.log(reversedColors); // returns [“brown”, “black”, “yellow”, “orange”, “purple”, “pink”, “navy”, “green”, “white”, “blue”]12. .lastIndexOf()方法
在 JavaScript 中,有一个有趣的方法,它允许查找给定元素的最后一次出现的索引。例如,如果我们的数组有重复的值,我们可以找到它最后一次出现的位置。让我们看一下代码示例:
var nums = [1, 5, 2, 6, 3, 5, 2, 3, 6, 5, 2, 7];
var lastIndex = nums.lastIndexOf(5);
console.log(lastIndex); // returns 913. 对数组中的所有值求和
var nums = [1, 5, 2, 6];
var sum = nums.reduce((x, y) => x + y);
console.log(sum); // returns 14结论
在本文中,我向您介绍了13个技巧和小窍门,它们可以帮助你编写简洁明了的代码。另外,请记住,您可以在 Javascript 中使用许多值得探索的技巧,不仅涉及数组,而且涉及不同的数据类型。我希望您喜欢本文中提供的解决方案,并且将使用它们来改善您的开发过程。
以上就是W3Cschool编程狮关于13个超实用的JavaScript数组操作技巧的相关介绍了,希望对大家有所帮助。
URL 去重的 6 种方案!(附详细代码)
文章来源于公众号:Java中文社群 ,作者:磊哥
URL 去重在我们日常工作中和面试中很常遇到,比如这些:
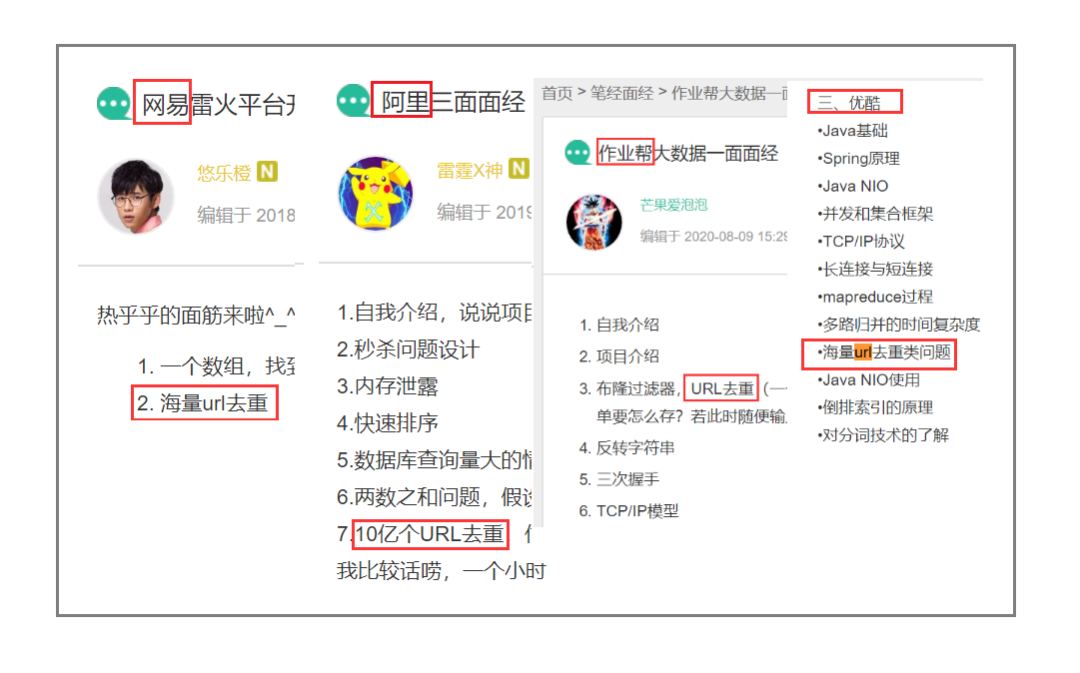
可以看出,包括阿里,网易云、优酷、作业帮等知名互联网公司都出现过类似的面试题,而且和 URL 去重比较类似的,如 IP 黑/白名单判断等也经常出现在我们的工作中,所以我们本文就来“盘一盘”URL 去重的问题。
URL 去重思路
在不考虑业务场景和数据量的情况下,我们可以使用以下方案来实现 URL 的重复判断:
- 使用 Java 的 Set 集合,根据添加时的结果来判断 URL 是否重复(添加成功表示 URL 不重复);
- 使用 Redis 中的 Set 集合,根据添加时的结果来判断 URL 是否重复;
- 将 URL 都存储在数据库中,再通过 SQL 语句判断是否有重复的 URL;
- 把数据库中的 URL 一列设置为唯一索引,根据添加时的结果来判断 URL 是否重复;
- 使用 Guava 的布隆过滤器来实现 URL 判重;
- 使用 Redis 的布隆过滤器来实现 URL 判重。
以上方案的具体实现如下。
URL 去重实现方案
1.使用 Java 的 Set 集合判重
Set 集合天生具备不可重复性,使用它只能存储值不相同的元素,如果值相同添加就会失败,因此我们可以通过添加 Set 集合时的结果来判定 URL 是否重复,实现代码如下:
public class URLRepeat {
// 待去重 URL
public static final String[] URLS = {
"www.apigo.cn",
"www.baidu.com",
"www.apigo.cn"
};
public static void main(String[] args) {
Set<String> set = new HashSet();
for (int i = 0; i < URLS.length; i++) {
String url = URLS[i];
boolean result = set.add(url);
if (!result) {
// 重复的 URL
System.out.println("URL 已存在了:" + url);
}
}
}
}程序的执行结果为:
URL 已存在了:www.apigo.cn
从上述结果可以看出,使用 Set 集合可以实现 URL 的判重功能。
2.Redis Set 集合去重
使用 Redis 的 Set 集合的实现思路和 Java 中的 Set 集合思想思路是一致的,都是利用 Set 的不可重复性实现的,我们先使用 Redis 的客户端 redis-cli来实现一下 URL 判重的示例:
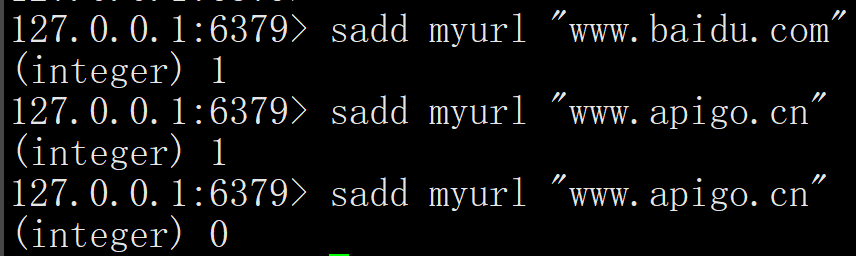
从上述结果可以看出,当添加成功时表示 URL 没有重复,但添加失败时(结果为 0)表示此 URL 已经存在了。
我们再用代码的方式来实现一下 Redis 的 Set去重,实现代码如下:
// 待去重 URL
public static final String[] URLS = {
"www.apigo.cn",
"www.baidu.com",
"www.apigo.cn"
};
@Autowired
RedisTemplate redisTemplate;
@RequestMapping("/url")
public void urlRepeat() {
for (int i = 0; i < URLS.length; i++) {
String url = URLS[i];
Long result = redisTemplate.opsForSet().add("urlrepeat", url);
if (result == 0) {
// 重复的 URL
System.out.println("URL 已存在了:" + url);
}
}
}以上程序的执行结果为:
URL 已存在了:www.apigo.cn
以上代码中我们借助了 Spring Data 中的 RedisTemplate 实现的,在 Spring Boot 项目中要使用 RedisTemplate 对象我们需要先引入 spring-boot-starter-data-redis 框架,配置信息如下:
<!-- 添加操作 RedisTemplate 引用 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency> 然后需要再项目中配置 Redis 的连接信息,在 application.properties 中配置如下内容:
spring.redis.host=127.0.0.1
spring.redis.port=6379
#spring.redis.password=123456 # Redis 服务器密码,有密码的话需要配置此项 经过以上两个步骤之后,我们就可以在 Spring Boot 的项目中正常的使用 RedisTemplate 对象来操作 Redis 了。
3.数据库去重
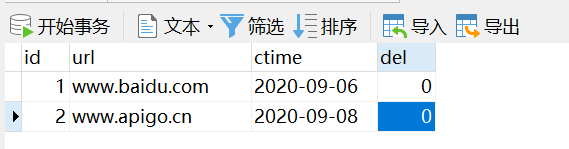
我们也可以借助数据库实现 URL 的重复判断,首先我们先来设计一张 URL 的存储表,如下图所示:

此表对应的 SQL 如下:
/*==============================================================*/
/* Table: urlinfo */
/*==============================================================*/
create table urlinfo
(
id int not null auto_increment,
url varchar(1000),
ctime date,
del boolean,
primary key (id)
);
/*==============================================================*/
/* Index: Index_url */
/*==============================================================*/
create index Index_url on urlinfo
(
url
); 其中 id 为自增的主键,而 url 字段设置为索引,设置索引可以加快查询的速度。
我们先在数据库中添加两条测试数据,如下图所示:
我们使用 SQL 语句查询,如下图所示:
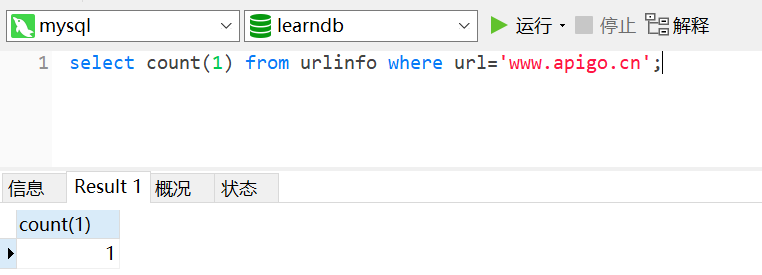
如果结果大于 0 则表明已经有重复的 URL 了,否则表示没有重复的 URL。
4.唯一索引去重
我们也可以使用数据库的唯一索引来防止 URL 重复,它的实现思路和前面 Set 集合的思想思路非常像。
首先我们先为字段 URL 设置了唯一索引,然后再添加 URL 数据,如果能添加成功则表明 URL 不重复,反之则表示重复。
创建唯一索引的 SQL 实现如下:
create unique index Index_url on urlinfo
(
url
);5.Guava 布隆过滤器去重
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
布隆过滤器的核心实现是一个超大的位数组和几个哈希函数,假设位数组的长度为 m,哈希函数的个数为 k。
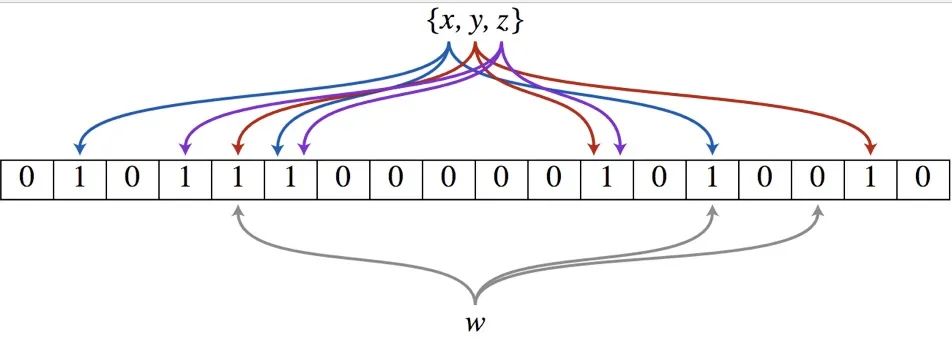
以上图为例,具体的操作流程:假设集合里面有 3 个元素 {x, y, z},哈希函数的个数为 3。首先将位数组进行初始化,将里面每个位都设置位 0。对于集合里面的每一个元素,将元素依次通过 3 个哈希函数进行映射,每次映射都会产生一个哈希值,这个值对应位数组上面的一个点,然后将位数组对应的位置标记为 1,查询 W 元素是否存在集合中的时候,同样的方法将 W 通过哈希映射到位数组上的 3 个点。如果 3 个点的其中有一个点不为 1,则可以判断该元素一定不存在集合中。反之,如果 3 个点都为 1,则该元素可能存在集合中。注意:此处不能判断该元素是否一定存在集合中,可能存在一定的误判率。可以从图中可以看到:假设某个元素通过映射对应下标为 4、5、6 这 3 个点。虽然这 3 个点都为 1,但是很明显这 3 个点是不同元素经过哈希得到的位置,因此这种情况说明元素虽然不在集合中,也可能对应的都是 1,这是误判率存在的原因。
我们可以借助 Google 提供的 Guava 框架来操作布隆过滤器,实现我们先在 pom.xml 中添加 Guava 的引用,配置如下:
<!-- 添加 Guava 框架 -->
<!-- https://mvnrepository.com/artifact/com.google.guava/guava -->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>28.2-jre</version>
</dependency>URL 判重的实现代码:
public class URLRepeat {
// 待去重 URL
public static final String[] URLS = {
"www.apigo.cn",
"www.baidu.com",
"www.apigo.cn"
};
public static void main(String[] args) {
// 创建一个布隆过滤器
BloomFilter<String> filter = BloomFilter.create(
Funnels.stringFunnel(Charset.defaultCharset()),
10, // 期望处理的元素数量
0.01); // 期望的误报概率
for (int i = 0; i < URLS.length; i++) {
String url = URLS[i];
if (filter.mightContain(url)) {
// 用重复的 URL
System.out.println("URL 已存在了:" + url);
} else {
// 将 URL 存储在布隆过滤器中
filter.put(url);
}
}
}
}以上程序的执行结果为:
URL 已存在了:www.apigo.cn
6.Redis 布隆过滤器去重
除了 Guava 的布隆过滤器,我们还可以使用 Redis 的布隆过滤器来实现 URL 判重。在使用之前,我们先要确保 Redis 服务器版本大于 4.0(此版本以上才支持布隆过滤器),并且开启了 Redis 布隆过滤器功能才能正常使用。
以 Docker 为例,我们来演示一下 Redis 布隆过滤器安装和开启,首先下载 Redis 的布隆过器,然后再在重启 Redis 服务时开启布隆过滤器,如下图所示:
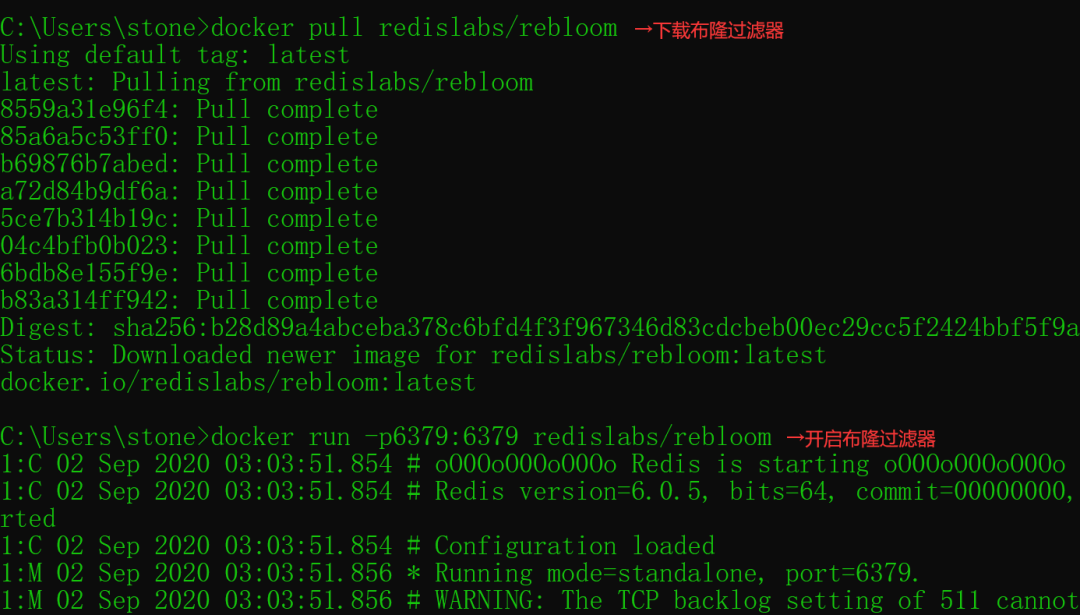
布隆过滤器使用:布隆过滤器正常开启之后,我们先用 Redis 的客户端 redis-cli 来实现一下布隆过滤器 URL 判重了,实现命令如下:
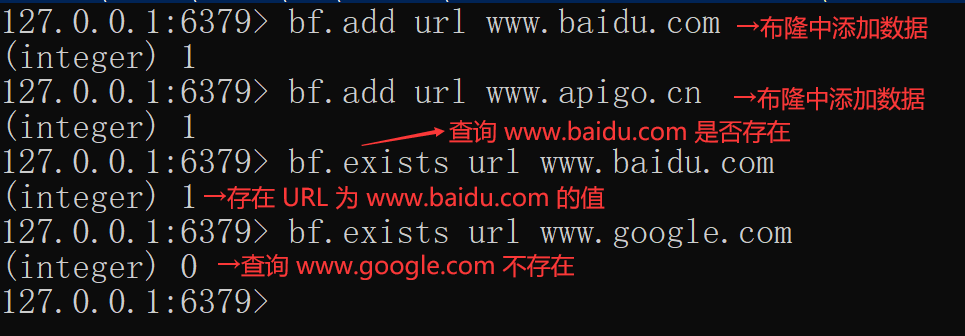
在 Redis 中,布隆过滤器的操作命令不多,主要包含以下几个:
– bf.add 添加元素;
– bf.exists 判断某个元素是否存在;
– bf.madd 添加多个元素;
– bf.mexists 判断多个元素是否存在;
– bf.reserve 设置布隆过滤器的准确率。
接下来我们使用代码来演示一下 Redis 布隆过滤器的使用:
import redis.clients.jedis.Jedis;
import utils.JedisUtils;
import java.util.Arrays;
public class BloomExample {
// 布隆过滤器 key
private static final String _KEY = "URLREPEAT_KEY";
// 待去重 URL
public static final String[] URLS = {
"www.apigo.cn",
"www.baidu.com",
"www.apigo.cn"
};
public static void main(String[] args) {
Jedis jedis = JedisUtils.getJedis();
for (int i = 0; i < URLS.length; i++) {
String url = URLS[i];
boolean exists = bfExists(jedis, _KEY, url);
if (exists) {
// 重复的 URL
System.out.println("URL 已存在了:" + url);
} else {
bfAdd(jedis, _KEY, url);
}
}
}
/**
* 添加元素
* @param jedis Redis 客户端
* @param key key
* @param value value
* @return boolean
*/
public static boolean bfAdd(Jedis jedis, String key, String value) {
String luaStr = "return redis.call('bf.add', KEYS[1], KEYS[2])";
Object result = jedis.eval(luaStr, Arrays.asList(key, value),
Arrays.asList());
if (result.equals(1L)) {
return true;
}
return false;
}
/**
* 查询元素是否存在
* @param jedis Redis 客户端
* @param key key
* @param value value
* @return boolean
*/
public static boolean bfExists(Jedis jedis, String key, String value) {
String luaStr = "return redis.call('bf.exists', KEYS[1], KEYS[2])";
Object result = jedis.eval(luaStr, Arrays.asList(key, value),
Arrays.asList());
if (result.equals(1L)) {
return true;
}
return false;
}
}以上程序的执行结果为:
URL 已存在了:www.apigo.cn
总结
本文介绍了 6 种 URL 去重的方案,其中 Redis Set、Redis 布隆过滤器、数据库和唯一索引这 4 种解决方案适用于分布式系统,如果是海量的分布式系统,建议使用 Redis 布隆过滤器来实现 URL 去重,如果是单机海量数据推荐使用 Guava 的布隆器来实现 URL 去重。
以上就是W3Cschool编程狮关于URL 去重的 6 种方案!(附详细代码)的相关介绍了,希望对大家有所帮助。
5个小技巧让你写出更好的JavaScript
文章来源于公众号:前端人
在使用 JavaScript 时,我们常常要写不少的条件语句。这里有五个小技巧,可以让你写出更干净、漂亮的条件语句。
使用 Array.includes 来处理多重条件
举个栗子 :
// 条件语句
function test(fruit) {
if (fruit == 'apple' || fruit == 'strawberry') {
console.log('red');
}
}乍一看,这么写似乎没什么大问题。
然而,如果我们想要匹配更多的红色水果呢,比方说『樱桃』和『蔓越莓』?我们是不是得用更多的 || 来扩展这条语句?
我们可以使用 Array.includes重写以上条件句。
function test(fruit) {
// 把条件提取到数组中
const redFruits = ['apple', 'strawberry', 'cherry', 'cranberries'];
if (redFruits.includes(fruit)) {
console.log('red');
}
}我们把红色的水果(条件)都提取到一个数组中,这使得我们的代码看起来更加整洁。
少写嵌套,尽早返回
让我们为之前的例子添加两个条件:
如果没有提供水果,抛出错误;
如果该水果的数量大于 10,将其打印出来。
function test(fruit, quantity) {
const redFruits = ['apple', 'strawberry', 'cherry', 'cranberries'];
// 条件 1:fruit 必须有值
if (fruit) {
// 条件 2:必须为红色
if (redFruits.includes(fruit)) {
console.log('red');
// 条件 3:必须是大量存在
if (quantity > 10) {
console.log('big quantity');
}
}
} else {
thrownewError('No fruit!');
}
}
// 测试结果
test(null); // 报错:No fruits
test('apple'); // 打印:red
test('apple', 20); // 打印:red,big quantity让我们来仔细看看上面的代码,我们有:
1 个 if/else 语句来筛选无效的条件;
3 层if语句嵌套(条件 1,2 & 3)。
就我个人而言,我遵循的一个总的规则是当发现无效条件时尽早返回。
/ 当发现无效条件时尽早返回 /
function test(fruit, quantity) {
const redFruits = ['apple', 'strawberry', 'cherry', 'cranberries'];
// 条件 1:尽早抛出错误
if (!fruit) thrownewError('No fruit!');
// 条件2:必须为红色
if (redFruits.includes(fruit)) {
console.log('red');
// 条件 3:必须是大量存在
if (quantity > 10) {
console.log('big quantity');
}
}
}如此一来,我们就少写了一层嵌套。这是种很好的代码风格,尤其是在 if 语句很长的时候(试想一下,你得滚动到底部才能知道那儿还有个 else 语句,是不是有点不爽)。
如果反转一下条件,我们还可以进一步地减少嵌套层级。注意观察下面的条件 2 语句,看看是如何做到这点的:
/ 当发现无效条件时尽早返回 /
function test(fruit, quantity) {
const redFruits = ['apple', 'strawberry', 'cherry', 'cranberries'];
if (!fruit) thrownewError('No fruit!'); // 条件 1:尽早抛出错误
if (!redFruits.includes(fruit)) return; // 条件 2:当 fruit 不是红色的时候,直接返回
console.log('red');
// 条件 3:必须是大量存在
if (quantity > 10) {
console.log('big quantity');
}
}通过反转条件 2 的条件,现在我们的代码已经没有嵌套了。
当我们代码的逻辑链很长,并且希望当某个条件不满足时不再执行之后流程时,这个技巧会很好用。
然而,并没有任何硬性规则要求你这么做。这取决于你自己,对你而言,这个版本的代码(没有嵌套)是否要比之前那个版本(条件 2 有嵌套)的更好、可读性更强?
是我的话,我会选择前一个版本(条件 2 有嵌套)。原因在于:
这样的代码比较简短和直白,一个嵌套的 if 使得结构更加清晰;
条件反转会导致更多的思考过程(增加认知负担)。
因此,始终追求更少的嵌套,更早地返回,但是不要过度。
使用函数默认参数和解构
我猜你也许很熟悉以下的代码,在 JavaScript 中我们经常需要检查 null / undefined并赋予默认值:
function test(fruit, quantity) {
if (!fruit) return;
const q = quantity || 1; // 如果没有提供 quantity,默认为 1
console.log(`We have ${q}${fruit}!`);
}
//测试结果
test('banana'); // We have 1 banana!
test('apple', 2); // We have 2 apple!事实上,我们可以通过函数的默认参数来去掉变量 q。
function test(fruit, quantity = 1) { // 如果没有提供 quantity,默认为 1
if (!fruit) return;
console.log(`We have ${quantity}${fruit}!`);
}
//测试结果
test('banana'); // We have 1 banana!
test('apple', 2); // We have 2 apple!是不是更加简单、直白了?
请注意,所有的函数参数都可以有其默认值。举例来说,我们同样可以为 fruit 赋予一个默认值:
function test(fruit = ‘unknown’, quantity = 1)。
那么如果 fruit 是一个对象(Object)呢?我们还可以使用默认参数吗?
function test(fruit) {
// 如果有值,则打印出来
if (fruit && fruit.name) {
console.log (fruit.name);
} else {
console.log('unknown');
}
}
//测试结果
test(undefined); // unknown
test({ }); // unknown
test({ name: 'apple', color: 'red' }); // apple观察上面的例子,当水果名称属性存在时,我们希望将其打印出来,否则打印『unknown』。
我们可以通过默认参数和解构赋值的方法来避免写出 fruit && fruit.name 这种条件。
// 解构 —— 只得到 name 属性
// 默认参数为空对象 {}
function test({name} = {}) {
console.log (name || 'unknown');
}
//测试结果
test(undefined); // unknown
test({ }); // unknown
test({ name: 'apple', color: 'red' }); // apple 既然我们只需要 fruit 的 name 属性,我们可以使用 {name}来将其解构出来,之后我们就可以在代码中使用 name 变量来取代 fruit.name。
我们还使用 {} 作为其默认值。
如果我们不这么做的话,
在执行 test(undefined) 时,你会得到一个错误 Cannot destructure property name of ‘undefined’ or ‘null’.,
因为 undefined 上并没有 name 属性。
(译者注:这里不太准确,其实因为解构只适用于对象(Object),而不是因为undefined 上并没有 name 属性(空对象上也没有)。参考解构赋值 – MDN)
如果你不介意使用第三方库的话,有一些方法可以帮助减少空值(null)检查:
使用 Lodash get 函数;
使用 Facebook 开源的 idx 库(需搭配 Babeljs)。
这里有一个使用 Lodash 的例子:
// 使用 lodash 库提供的 _ 方法
function test(fruit) {
// 获取属性 name 的值,如果没有,设为默认值 unknown
console.log(_.get(fruit, 'name', 'unknown');
}
//测试结果
test(undefined); // unknown
test({ }); // unknown
test({ name: 'apple', color: 'red' }); // apple你可以在这里运行演示代码。
另外,如果你偏爱函数式编程(FP),你可以选择使用 Lodash fp——函数式版本的 Lodash(方法名变为 get 或 getOr)。
相较于 switch,Map / Object 也许是更好的选择
让我们看下面的例子,我们想要根据颜色打印出各种水果:
function test(color) {
// 使用 switch case 来找到对应颜色的水果
switch (color) {
case 'red':
return ['apple', 'strawberry'];
case 'yellow':
return ['banana', 'pineapple'];
case 'purple':
return ['grape', 'plum'];
default:
return [];
}
}//测试结果
test(null); // []
test(‘yellow’); // [‘banana’, ‘pineapple’]
上面的代码看上去并没有错,但是就我个人而言,它看上去很冗长。同样的结果可以通过对象字面量来实现,语法也更加简洁:
// 使用对象字面量来找到对应颜色的水果
const fruitColor = {
red: ['apple', 'strawberry'],
yellow: ['banana', 'pineapple'],
purple: ['grape', 'plum']
};
function test(color) {
return fruitColor[color] || [];
}或者,你也可以使用 Map 来实现同样的效果:
// 使用 Map 来找到对应颜色的水果
const fruitColor = newMap()
.set('red', ['apple', 'strawberry'])
.set('yellow', ['banana', 'pineapple'])
.set('purple', ['grape', 'plum']);
function test(color) {
return fruitColor.get(color) || [];
}Map 是 ES2015 引入的新的对象类型,允许你存放键值对。
那是不是说我们应该禁止使用 switch 语句?别把自己限制住。
我自己会在任何可能的时候使用对象字面量,但是这并不是说我就不用 switch,这得视场景而定。
就以上的例子,事实上我们可以通过重构我们的代码,使用 Array.filter 实现同样的效果。
const fruits = [
{ name: 'apple', color: 'red' },
{ name: 'strawberry', color: 'red' },
{ name: 'banana', color: 'yellow' },
{ name: 'pineapple', color: 'yellow' },
{ name: 'grape', color: 'purple' },
{ name: 'plum', color: 'purple' }
];
function test(color) {
// 使用 Array filter 来找到对应颜色的水果
return fruits.filter(f => f.color == color);
}解决问题的方法永远不只一种。对于这个例子我们展示了四种实现方法。
Coding is fun!
使用 Array.every 和 Array.some 来处理全部/部分满足条件
最后一个小技巧更多地是关于使用新的(也不是很新了)JavaScript 数组函数来减少代码行数。
观察以下的代码,我们想要检查是否所有的水果都是红色的:
const fruits = [
{ name: 'apple', color: 'red' },
{ name: 'banana', color: 'yellow' },
{ name: 'grape', color: 'purple' }
];
function test() {
let isAllRed = true;
// 条件:所有的水果都必须是红色
for (let f of fruits) {
if (!isAllRed) break;
isAllRed = (f.color == 'red');
}
console.log(isAllRed); // false
} 这段代码也太长了!我们可以通过 Array.every 来缩减代码
const fruits = [
{ name: 'apple', color: 'red' },
{ name: 'banana', color: 'yellow' },
{ name: 'grape', color: 'purple' }
];
function test() {
// 条件:(简短形式)所有的水果都必须是红色
const isAllRed = fruits.every(f => f.color == 'red');
console.log(isAllRed); // false
}清晰多了对吧?
类似的,如果我们想要检查是否有至少一个水果是红色的,我们可以使用 Array.some 仅用一行代码就实现出来。
const fruits = [
{ name: 'apple', color: 'red' },
{ name: 'banana', color: 'yellow' },
{ name: 'grape', color: 'purple' }
];
function test() {
// 条件:至少一个水果是红色的
const isAnyRed = fruits.some(f => f.color == 'red');
console.log(isAnyRed); // true
}让我们一起写出可读性更高的代码吧。希望这篇文章能给你们带来一些帮助。就是这样啦~
以上就是W3Cschool编程狮关于5个小技巧让你写出更好的JavaScript的相关介绍了,希望对大家有所帮助。