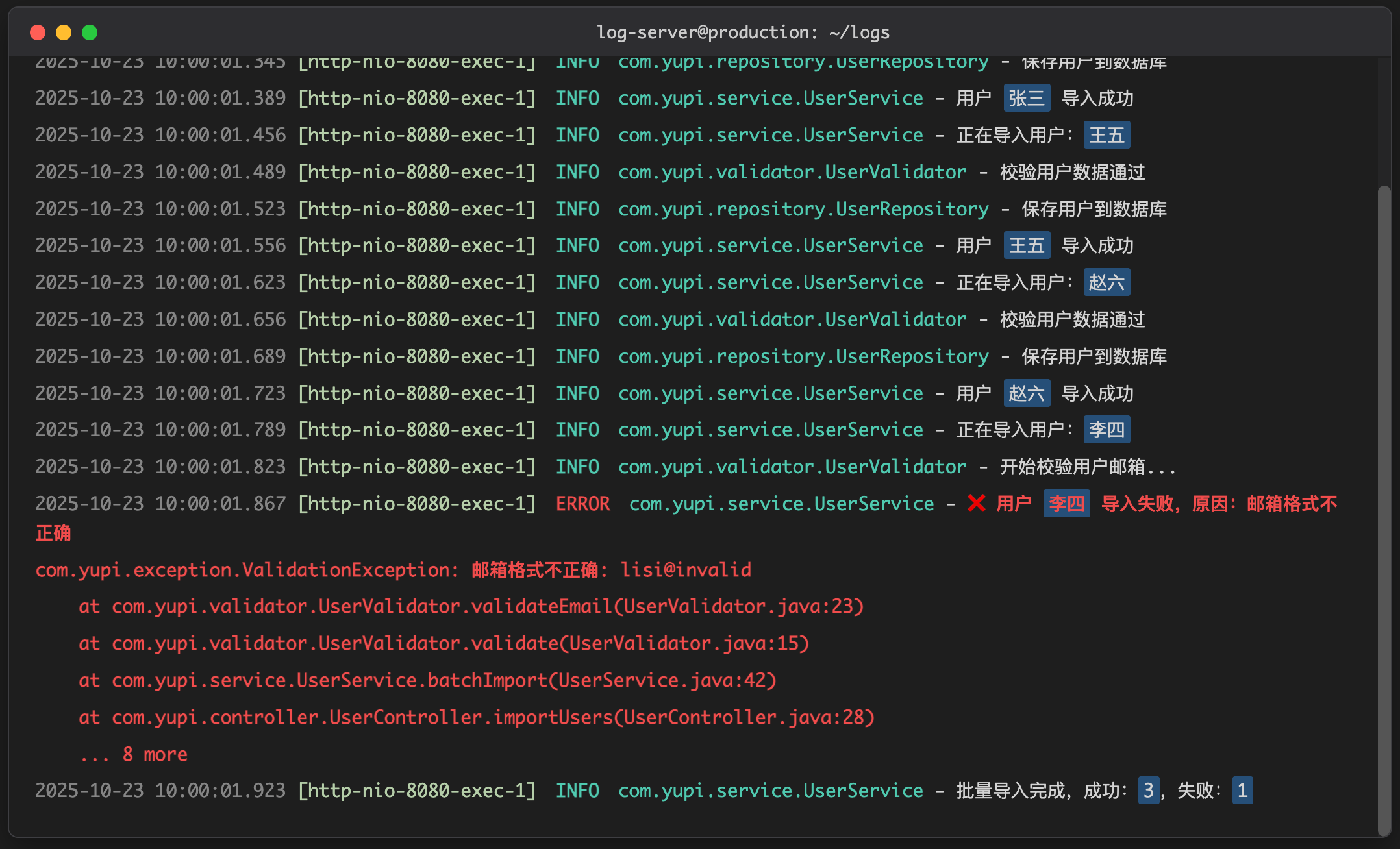
ASP.NET Core Blazor 核心功能三:Blazor与JavaScript互操作——让Web开发更灵活
嗨,大家好!我是码农刚子。今天我们来聊聊Blazor中C#与JavaScript互操作。我知道很多同学在听到”Blazor”和”JavaScript”要一起工作时会有点懵,但别担心,我会用最简单的方式带你掌握这个技能!
为什么要学JavaScript互操作?
想象一下:你正在用Blazor开发一个超棒的应用,但突然需要用到某个只有JavaScript才能实现的炫酷效果,或者要集成一个超好用的第三方JS库。这时候,JavaScript互操作就是你的救星!
简单来说,它让Blazor和JavaScript可以”握手合作”,各展所长。下面我们就从最基础的部分开始。
1. IJSRuntime – 你的JavaScript通行证
在Blazor中,IJSRuntime是与JavaScript沟通的桥梁。获取它超级简单:
@inject IJSRuntime JSRuntime <button @onclick="ShowAlert">点我弹窗!</button> @code { private async Task ShowAlert() { await JSRuntime.InvokeVoidAsync("alert", "Hello from Blazor!"); } }
就两行关键代码:
@inject IJSRuntime JSRuntime– 拿到通行证InvokeVoidAsync– 调用不返回值的JS函数
实际场景:比如用户完成某个操作后,你想显示一个提示,用这种方式就特别方便。
2. 调用JavaScript函数 – 不只是简单弹窗
当然,我们不会只满足于弹窗。来看看更实用的例子:
首先,在wwwroot/index.html中添加我们的JavaScript工具函数:
<script>
// 创建命名空间避免全局污染
window.myJsHelpers = {
showNotification: function (message, type) {
// 模拟显示一个漂亮的提示框
const notification = document.createElement('div');
notification.style.cssText = `
position: fixed;
top: 20px;
right: 20px;
padding: 15px 20px;
border-radius: 5px;
color: white;
z-index: 1000;
transition: all 0.3s ease;
`;
if (type === 'success') {
notification.style.backgroundColor = '#28a745';
} else if (type === 'error') {
notification.style.backgroundColor = '#dc3545';
} else {
notification.style.backgroundColor = '#17a2b8';
}
notification.textContent = message;
document.body.appendChild(notification);
// 3秒后自动消失
setTimeout(() => {
notification.remove();
}, 3000);
},
getBrowserInfo: function () {
return {
userAgent: navigator.userAgent,
language: navigator.language,
platform: navigator.platform
};
},
// 带参数的计算函数
calculateDiscount: function (originalPrice, discountPercent) {
return originalPrice * (1 - discountPercent / 100);
}
};
</script>
然后在Blazor组件中使用:
@inject IJSRuntime JSRuntime <div class="demo-container"> <h3>JavaScript函数调用演示</h3> <button @onclick="ShowSuccessNotification" class="btn btn-success"> 显示成功提示 </button> <button @onclick="ShowErrorNotification" class="btn btn-danger"> 显示错误提示 </button> <button @onclick="GetBrowserInfo" class="btn btn-info"> 获取浏览器信息 </button> <button @onclick="CalculatePrice" class="btn btn-warning"> 计算折扣价格 </button> @if (!string.IsNullOrEmpty(browserInfo)) { <div class="alert alert-info mt-3"> <strong>浏览器信息:</strong> @browserInfo </div> } @if (discountResult > 0) { <div class="alert alert-success mt-3"> <strong>折扣价格:</strong> ¥@discountResult </div> } </div> @code { private string browserInfo = ""; private decimal discountResult; private async Task ShowSuccessNotification() { await JSRuntime.InvokeVoidAsync("myJsHelpers.showNotification", "操作成功!数据已保存。", "success"); } private async Task ShowErrorNotification() { await JSRuntime.InvokeVoidAsync("myJsHelpers.showNotification", "出错了!请检查网络连接。", "error"); } private async Task GetBrowserInfo() { var info = await JSRuntime.InvokeAsync<BrowserInfo>("myJsHelpers.getBrowserInfo"); browserInfo = $"语言: {info.Language}, 平台: {info.Platform}"; } private async Task CalculatePrice() { discountResult = await JSRuntime.InvokeAsync<decimal>( "myJsHelpers.calculateDiscount", 1000, 20); // 原价1000,8折 } // 定义接收复杂对象的类 private class BrowserInfo { public string UserAgent { get; set; } public string Language { get; set; } public string Platform { get; set; } } }

Note
- 使用
InvokeVoidAsync调用不返回值的函数 - 使用
InvokeAsync<T>调用有返回值的函数,记得指定返回类型 - 复杂对象会自动序列化/反序列化
3. 把.NET方法暴露给JavaScript – 双向操作
有时候,我们也需要让JavaScript能调用我们的C#方法。这就用到[JSInvokable]特性了。
@inject IJSRuntime JSRuntime @implements IDisposable <div class="demo-container"> <h3>.NET方法暴露演示</h3> <div class="mb-3"> <label>消息内容:</label> <input @bind="message" class="form-control" /> </div> <div class="mb-3"> <label>重复次数:</label> <input type="number" @bind="repeatCount" class="form-control" /> </div> <button @onclick="RegisterDotNetMethods" class="btn btn-primary"> 注册.NET方法给JavaScript使用 </button> <div id="js-output" class="mt-3 p-3 border rounded"> <!-- JavaScript会在这里输出内容 --> </div> </div> @code { private string message = "Hello from .NET!"; private int repeatCount = 3; private DotNetObjectReference<MyComponent> dotNetHelper; protected override void OnInitialized() { dotNetHelper = DotNetObjectReference.Create(this); } private async Task RegisterDotNetMethods() { await JSRuntime.InvokeVoidAsync("registerDotNetHelper", dotNetHelper); } [JSInvokable] public string GetFormattedMessage() { return string.Join(" ", Enumerable.Repeat(message, repeatCount)); } [JSInvokable] public async Task<string> ProcessDataAsync(string input) { // 模拟一些异步处理 await Task.Delay(500); return $"处理后的数据: {input.ToUpper()} (处理时间: {DateTime.Now:HH:mm:ss})"; } [JSInvokable] public void ShowAlert(string alertMessage) { // 这个方法会被JavaScript调用 // 在实际应用中,你可能会更新组件状态或触发其他操作 Console.WriteLine($"收到JavaScript的警告: {alertMessage}"); } public void Dispose() { dotNetHelper?.Dispose(); } }
对应的JavaScript代码:
// 在index.html中添加 function registerDotNetHelper(dotNetHelper) { // 存储.NET引用供后续使用 window.dotNetHelper = dotNetHelper; // 演示调用.NET方法 callDotNetMethods(); } async function callDotNetMethods() { if (!window.dotNetHelper) { console.error('.NET helper 未注册'); return; } try { // 调用无参数的.NET方法 const message = await window.dotNetHelper.invokeMethodAsync('GetFormattedMessage'); // 调用带参数的异步.NET方法 const processed = await window.dotNetHelper.invokeMethodAsync('ProcessDataAsync', 'hello world'); // 调用void方法 window.dotNetHelper.invokeMethodAsync('ShowAlert', '这是从JS发来的消息!'); // 在页面上显示结果 const output = document.getElementById('js-output'); output.innerHTML = ` <strong>来自.NET的消息:</strong> ${message}<br> <strong>处理后的数据:</strong> ${processed} `; } catch (error) { console.error('调用.NET方法失败:', error); } }

Note
- 记得使用
DotNetObjectReference来创建引用 - 使用
Dispose()及时清理资源 - 异步方法要返回
Task或Task<T>
4. 使用JavaScript库 – 集成第三方神器
这是最实用的部分!让我们看看如何集成流行的JavaScript库。
示例:集成Chart.js图表库
首先引入Chart.js:
<!-- 在index.html中 --> <script src="https://cdn.jsdelivr.net/npm/chart.js"></script>
创建图表辅助函数:
// 在index.html中或单独的JS文件 window.chartHelpers = { createChart: function (canvasId, config) { const ctx = document.getElementById(canvasId).getContext('2d'); return new Chart(ctx, config); }, updateChart: function (chart, data) { chart.data = data; chart.update(); }, destroyChart: function (chart) { chart.destroy(); } };
Blazor组件:
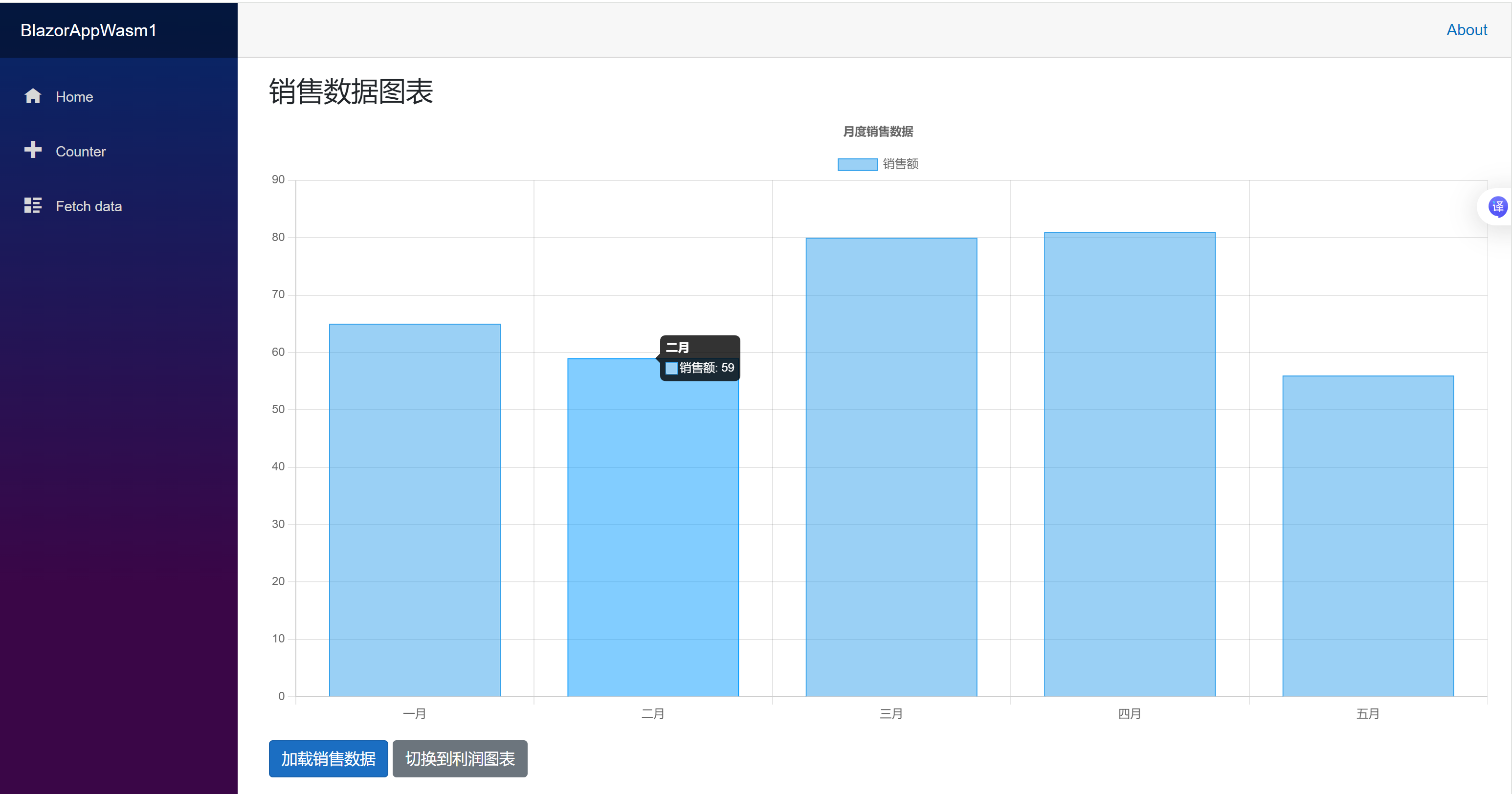
@inject IJSRuntime JSRuntime @implements IDisposable <div class="chart-demo"> <h3>销售数据图表</h3> <canvas id="salesChart" width="400" height="200"></canvas> <div class="mt-3"> <button @onclick="LoadSalesData" class="btn btn-primary">加载销售数据</button> <button @onclick="SwitchToProfitChart" class="btn btn-secondary">切换到利润图表</button> </div> </div> @code { private IJSObjectReference chartInstance; private bool isSalesData = true; protected override async Task OnAfterRenderAsync(bool firstRender) { if (firstRender) { await InitializeChart(); } } private async Task InitializeChart() { var config = new { type = "bar", data = new { labels = new[] { "一月", "二月", "三月", "四月", "五月" }, datasets = new[] { new { label = "销售额", data = new[] { 65, 59, 80, 81, 56 }, backgroundColor = "rgba(54, 162, 235, 0.5)", borderColor = "rgba(54, 162, 235, 1)", borderWidth = 1 } } }, options = new { responsive = true, plugins = new { title = new { display = true, text = "月度销售数据" } } } }; chartInstance = await JSRuntime.InvokeAsync<IJSObjectReference>( "chartHelpers.createChart", "salesChart", config); } private async Task LoadSalesData() { var newData = new { labels = new[] { "一月", "二月", "三月", "四月", "五月", "六月" }, datasets = new[] { new { label = "销售额", data = new[] { 65, 59, 80, 81, 56, 75 }, backgroundColor = "rgba(54, 162, 235, 0.5)" } } }; await JSRuntime.InvokeVoidAsync("chartHelpers.updateChart", chartInstance, newData); } private async Task SwitchToProfitChart() { isSalesData = !isSalesData; var newData = isSalesData ? new { labels = new[] { "Q1", "Q2", "Q3", "Q4" }, datasets = new[] { new { label = "销售额", data = new[] { 100, 120, 110, 130 }, backgroundColor = "rgba(54, 162, 235, 0.5)" } } } : new { labels = new[] { "Q1", "Q2", "Q3", "Q4" }, datasets = new[] { new { label = "利润", data = new[] { 30, 45, 35, 50 }, backgroundColor = "rgba(75, 192, 192, 0.5)" } } }; await JSRuntime.InvokeVoidAsync("chartHelpers.updateChart", chartInstance, newData); } public async void Dispose() { if (chartInstance != null) { await JSRuntime.InvokeVoidAsync("chartHelpers.destroyChart", chartInstance); } } }
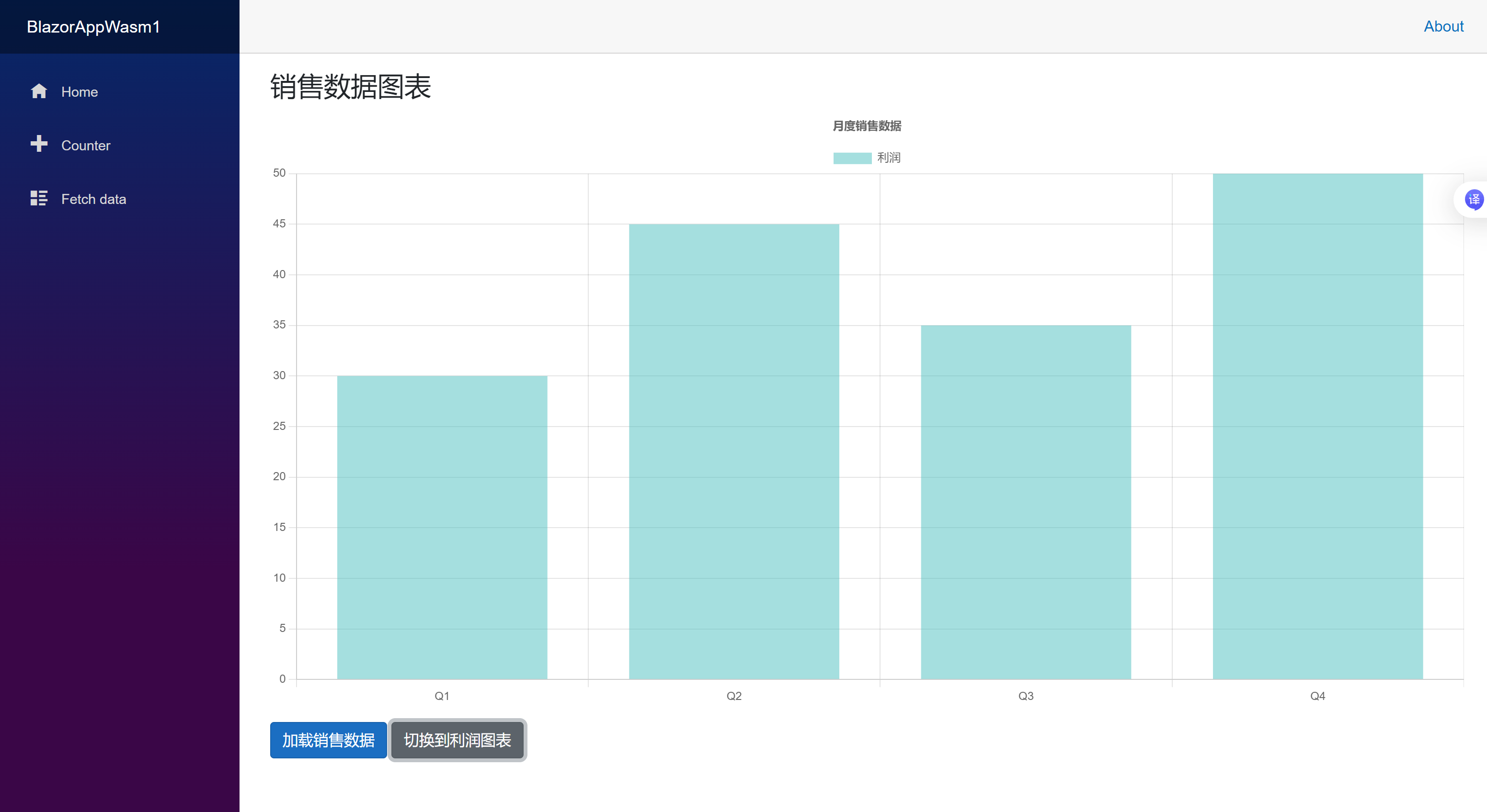
常见问题与解决方案
问题1:JS互操作调用失败
症状:控制台报错,函数未定义
解决:
try { await JSRuntime.InvokeVoidAsync("someFunction"); } catch (JSException ex) { Console.WriteLine($"JS调用失败: {ex.Message}"); // 回退方案 await JSRuntime.InvokeVoidAsync("console.warn", "功能不可用"); }
问题2:性能优化
对于频繁调用的JS函数,可以使用IJSInProcessRuntime:
@inject IJSRuntime JSRuntime @code { private IJSInProcessRuntime jsInProcess; protected override void OnInitialized() { jsInProcess = (IJSInProcessRuntime)JSRuntime; } private void HandleInput(ChangeEventArgs e) { // 同步调用,更高效 jsInProcess.InvokeVoidAsync("handleInput", e.Value.ToString()); } }
问题3:组件销毁时资源清理
@implements IDisposable @code { private DotNetObjectReference<MyComponent> dotNetRef; private IJSObjectReference jsModule; protected override async Task OnInitializedAsync() { dotNetRef = DotNetObjectReference.Create(this); jsModule = await JSRuntime.InvokeAsync<IJSObjectReference>( "import", "./js/myModule.js"); } public async void Dispose() { dotNetRef?.Dispose(); if (jsModule != null) { await jsModule.DisposeAsync(); } } }
Blazor的JavaScript互操作其实没那么难的。记住这几个关键点:
- IJSRuntime 是你的通行证
- InvokeVoidAsync 和 InvokeAsync 是主要工具
- [JSInvokable] 让.NET方法对JS可见
- 及时清理资源 很重要
现在你已经掌握了Blazor与JavaScript互操作的核心技能!试着在自己的项目中实践一下,示例源码更放在仓库:https://github.com/shenchuanchao/BlazorApp/tree/master/BlazorAppWasm/Pages
以上就是《ASP.NET Core Blazor 核心功能二:Blazor与JavaScript互操作——让Web开发更灵活》的全部内容,希望你有所收获。关注、点赞,持续分享。 posted @
2025-11-05 21:34
码农刚子 阅读(
149) 评论(
0)
收藏
举报

















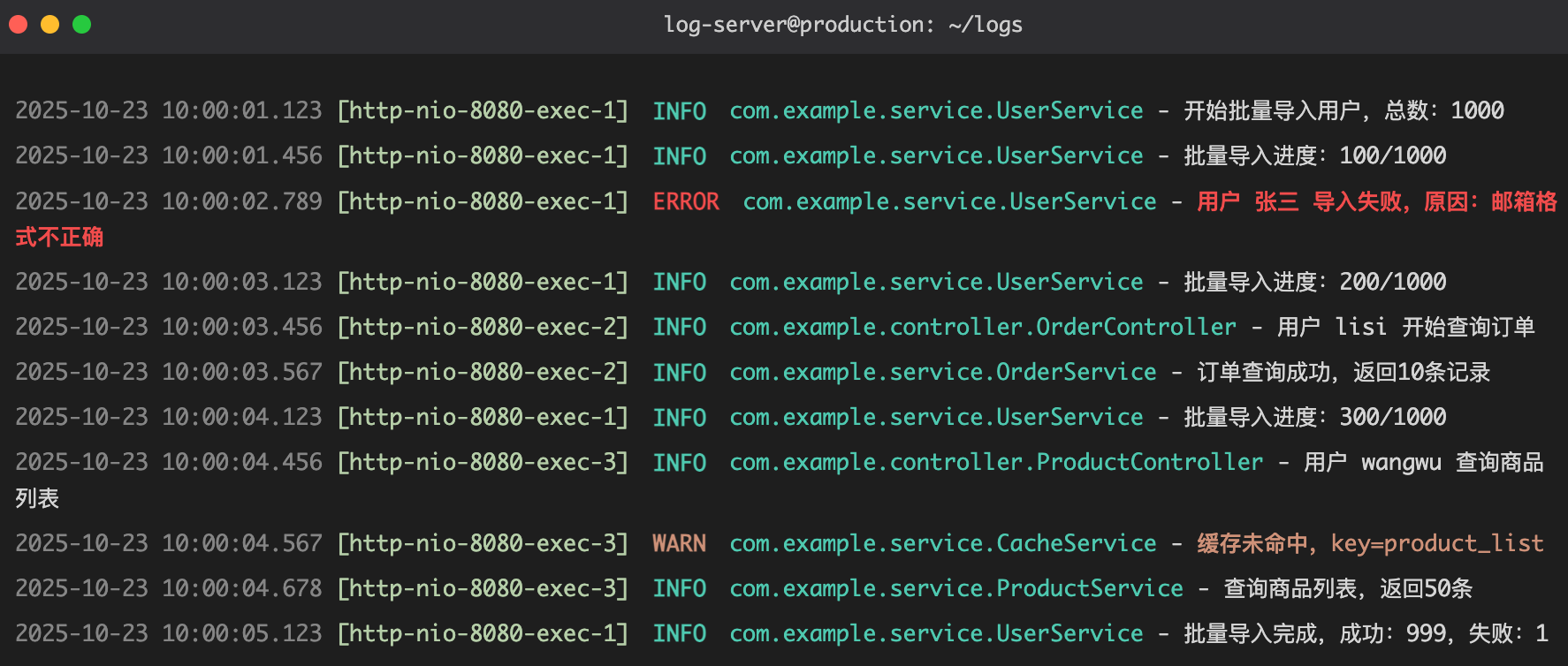
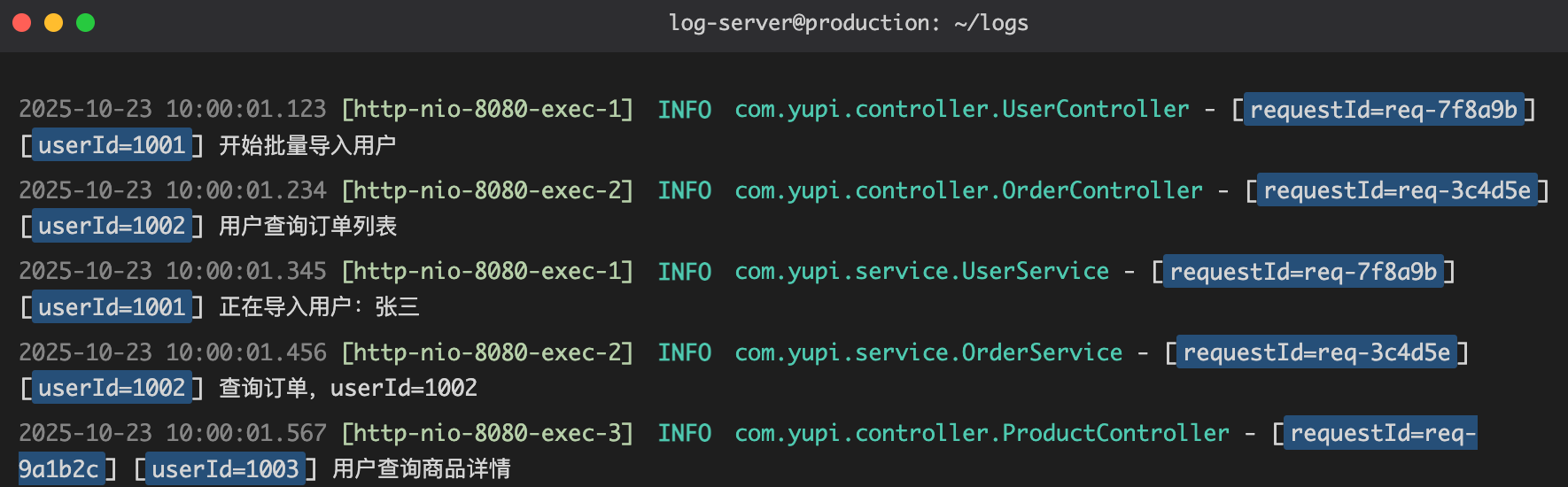
 日志不是写给机器看的,是写给未来的你和你的队友看的!
日志不是写给机器看的,是写给未来的你和你的队友看的!