winapp CLI 是微软推出的一个
命令行工具,旨在为 Windows 应用开发者提供统一、简洁的开发体验。它整合了 Windows SDK、App SDK、应用打包(MSIX)、证书管理、清单生成、调试身份配置等核心功能,适用于各种开发框架(如 Electron、.NET、C++、Rust、Tauri、Python 等)。
AI开发-python-langchain框架(1-5 使用 Few-Shot Prompting 实现多跳推理问答:以历史人物寿命比较为例)
结果如下:
从0构建WAV文件:读懂计算机文件的本质
今天,我们就从最朴素的方式入手,通过手动构建一个WAV音频文件,拆解WAV格式的底层逻辑,同时理解一个核心认知:只要掌握了文件的格式规范,任何类型的文件都能像搭积木一样,一行行代码“拼”出来。
算竞一题中的代码设计与技巧解析
DBShadow.net之性能优化的坎坷路
如果大家喜欢请动动您发财的小手手帮忙点一下Star,谢谢!!!
TCP三次握手与四次挥手:两个“社恐”程序的破冰与告别仪式
其实说白了,三次握手是客户端和服务器的“破冰仪式”,就像两个社恐网友第一次打电话,反复确认信号通不通才敢开唠;而四次挥手则是“体面告别”,好比聊天结束后,双方要反复确认“你说完了吗”“我说完了,你可以挂了”,生怕挂早了漏了重要内容。前面咱们用生活化场景拆解了三次握手的实际流程,接下来就顺着节奏,把四次挥手的通俗逻辑和底层原理一并讲透。
kubectl plugin:neat 的安装与使用
使用
kubectl-neat 插件,可以自动移除这些由集群生成的冗余字段,仅保留有意义的内容,使 yaml 更加简洁,方便复用。
GitHub Issues 集成
这带来了几个明显的痛点:
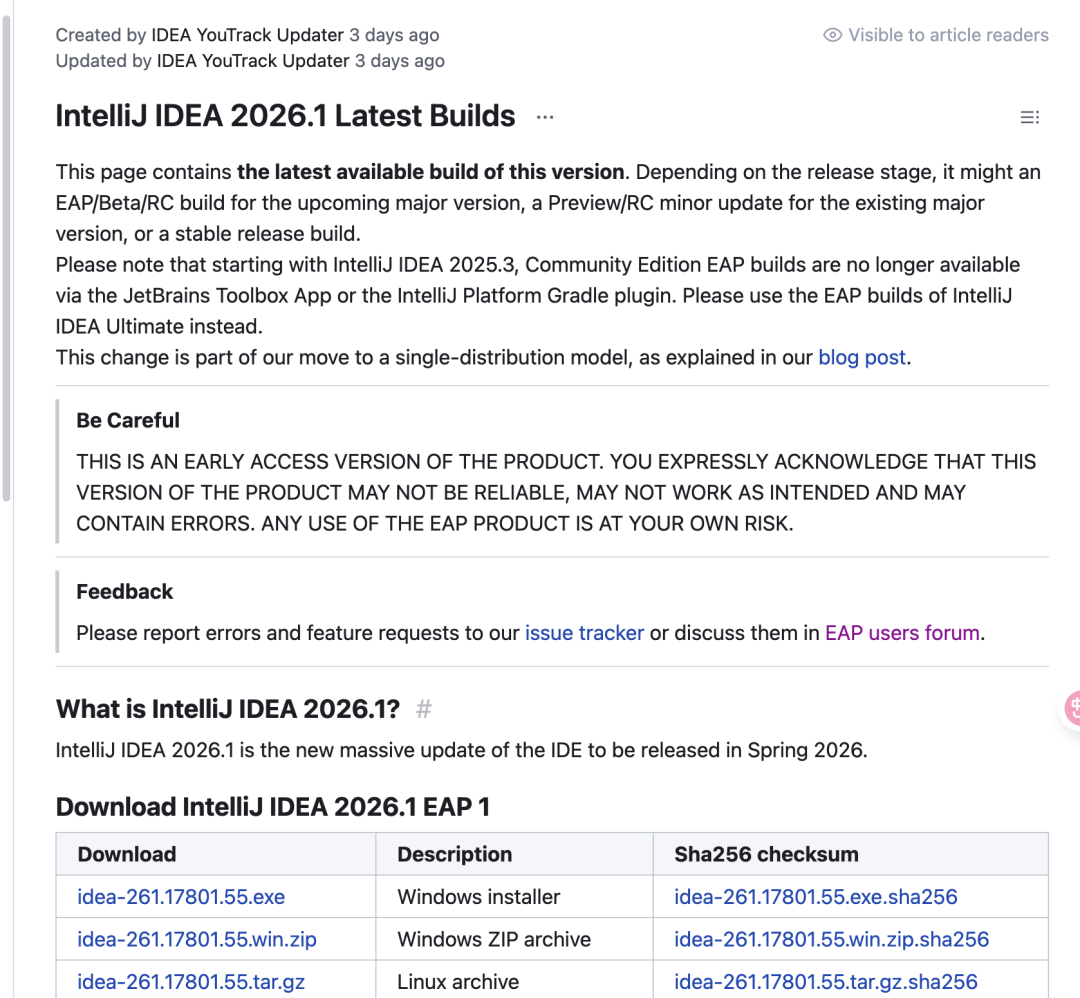
IntelliJ IDEA 2026.1 EAP 发布!拥抱 Java 26,Spring Boot 4 深度支持!
langchain 快速入门(二):chain链的应用
根据查阅的资料,langchain的chain链结构如下: