不过凡事不加限制就会出问题,如果不加节制的滥用 goroutine 就可能导致内存泄露,增加 Go 运行时调度负担等。
吴恩达深度学习课程二: 改善深层神经网络 第三周:超参数调整,批量标准化和编程框架 课后习题和代码实践
本篇为第二课第三周的课程习题和代码实践部分笔记。
Solon Web 的“分身术”:单应用多端口监听,化身多重服务
典型应用场景:
大语言模型排行榜!ChatGPT 稳居榜首,国产模型表现亮眼
近年来,随着人工智能技术的飞速发展,大语言模型(LLM)逐渐成为科技领域的热门话题。
这些模型拥有强大的语言理解和生成能力,可以进行文本摘要、问答、翻译、代码生成等多种任务,并展现出巨大的应用潜力。
然而,面对琳琅满目的模型,如何判断哪个模型更强大、更适合自己的需求呢?
为了更好地了解不同模型的优劣,各大研究机构和科技公司纷纷发布了大语言模型排行榜,为用户提供参考。
这些排行榜通常基于模型在不同任务上的表现进行排名,例如语言理解、生成能力、代码生成等。
SuperCLUE是一个由中国科学院自动化研究所和清华大学联合发布的中文语言理解评估基准,其总排行榜涵盖了多个语言理解任务,为我们提供了一个重要的参考标准。
今天我们一起看看SuperCLUE给出的9月大模型语言排行榜。
1.排名总榜
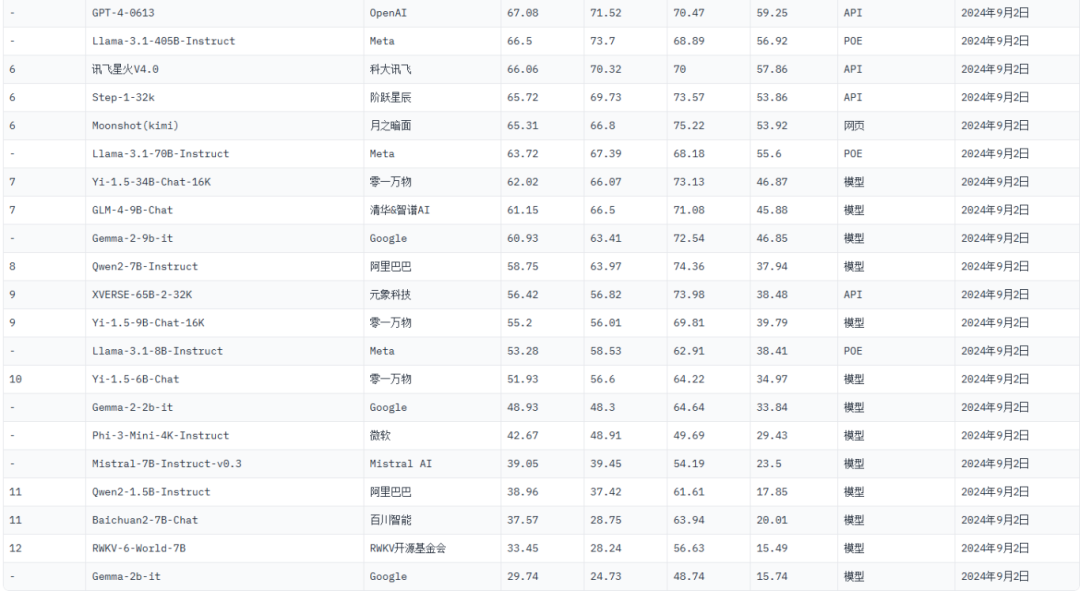
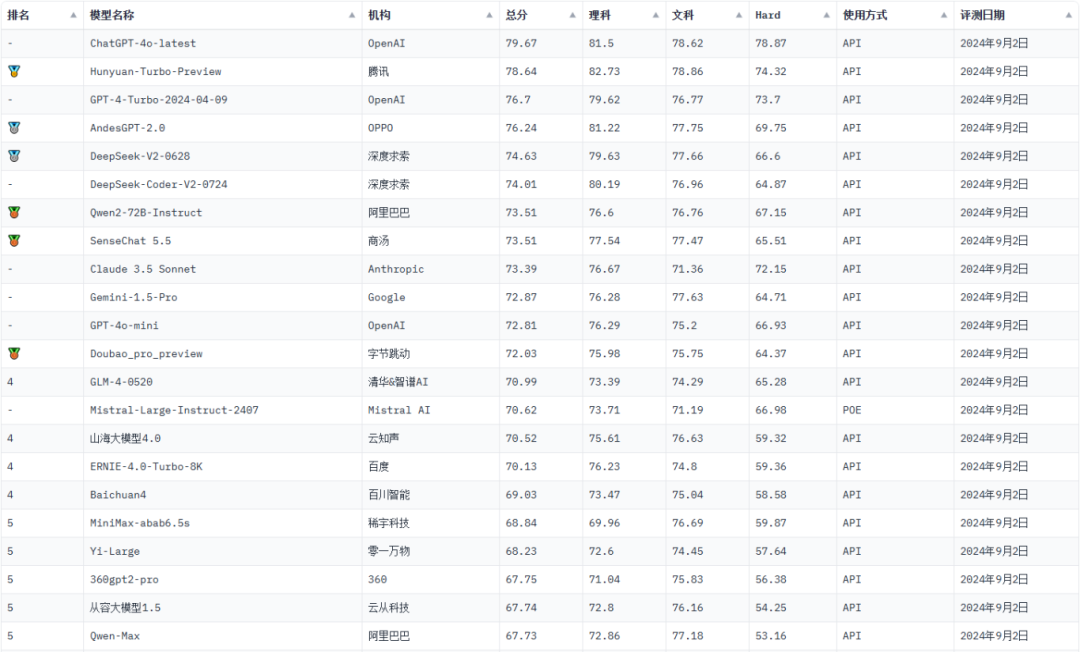
OpenAI的ChatGPT-4o-latest稳居榜首,总分为79.67, 在理科、文科和Hard任务上均取得了领先优势,展现出强大的综合能力。
腾讯的Hunyuan-Turbo-Preview位居第二,总分为78.64, 在理科任务上表现突出,展现出其在逻辑推理和知识理解方面的优势。
OpenAI的GPT-4-Turbo-2024-04-09位居第三,总分为76.7, 在文科任务上表现出色,展现出其在语言表达和情感分析方面的优势。
2.榜单亮点
国产模型崛起
除了OpenAI和Google等国际巨头,国内厂商也涌现出许多优秀的模型。
例如百度的文心一言、华为的盘古模型、阿里的通义千问等,在榜单中占据重要地位,展现出国产大模型的蓬勃发展态势。
多任务能力提升
榜单中大多数模型在多个任务上都取得了不错的成绩,展现出大语言模型在多任务处理能力上的进步。
模型规模和性能的平衡
榜单中既有参数规模巨大的模型,例如GPT-4、文心一言等;也有参数规模相对较小的模型,例如Qwen2-7B-Instruct、GLM-4-9B-Chat等,展现出模型规模和性能之间的平衡。
3.选择建议
根据需求选择
用户应根据自己的实际需求选择合适的模型,例如需要进行逻辑推理和知识理解的任务可以选择Hunyuan-Turbo-Preview,需要进行语言表达和情感分析的任务可以选择GPT-4-Turbo-2024-04-09。
综合考虑多个指标
用户应综合考虑模型在不同任务上的表现,以及模型的可用性、成本等因素,进行综合判断。
关注模型更新
大语言模型领域发展迅速,用户应关注模型的最新更新和改进,选择最符合自身需求的模型。
SuperCLUE总榜为我们提供了当前大语言模型的竞争格局,并为用户选择合适的模型提供了重要参考。
未来,随着人工智能技术的不断发展,大语言模型将会继续朝着更加强大、更加智能的方向发展,并为我们的生活带来更多便利和改变。
排名榜单链接
https://www.superclueai.com/
DaPy:实现数据分析与处理
DaPy是一个用于数据分析和处理的Python库,它提供了一系列强大的工具和功能,使开发者能够高效地进行数据清洗、转换和分析。本文将深入解析DaPy库的特点、功能以及使用示例,帮助读者了解如何利用DaPy库处理和分析数据,以提升数据分析的效率和准确性。
DaPy库简介
DaPy是一个基于Python的开源库,专注于数据分析和处理。它提供了一套简洁而灵活的工具和函数,使开发者能够对数据进行各种操作,如数据清洗、转换、筛选和聚合等。DaPy库的设计目标是帮助开发者在数据分析过程中高效地处理和分析数据,从而得出准确的结论和洞察。

DaPy库的特点
- 数据清洗和转换:DaPy库提供了丰富的数据清洗和转换函数,如缺失值处理、重复值删除、数据类型转换等,使开发者能够轻松地对数据进行预处理和规整。
- 数据筛选和排序:DaPy库支持基于条件的数据筛选和排序,开发者可以通过简单的代码实现对数据的灵活筛选和排序,以满足特定的分析需求。
- 数据聚合和统计:DaPy库提供了强大的聚合和统计函数,如分组聚合、数据透视表等,使开发者能够方便地进行数据汇总和统计分析。
- 高效的数据处理:DaPy库采用了优化的数据处理算法和数据结构,以提高数据处理的效率和性能,特别是在处理大规模数据时表现出色。
- 可扩展性:DaPy库具有良好的可扩展性,开发者可以根据需要自定义函数和操作,以满足特定数据处理和分析的需求。
DaPy库的使用示例
下面是一个简单的示例,展示了如何使用DaPy库进行数据清洗和统计分析:
import dapy as dp
# 导入数据
data = dp.read_csv('data.csv')
# 数据清洗
data = data.drop_duplicates() # 删除重复值
data = data.dropna() # 删除缺失值
# 数据筛选
filtered_data = data[data['age'] > 30] # 筛选年龄大于30的数据
# 数据聚合和统计
grouped_data = filtered_data.groupby('gender')
summary = grouped_data['income'].mean() # 计算不同性别的平均收入
print(summary)在上面的示例中,我们首先导入了DaPy库,并使用read_csv()函数导入了一个CSV格式的数据文件。然后,我们使用drop_duplicates()函数和dropna()函数对数据进行了清洗,删除了重复值和缺失值。接下来,我们使用条件筛选语句data['age'] > 30对数据进行了筛选,只保留了年龄大于30的数据。最后,我们使用groupby()函数对筛选后的数据进行了分组,然后使用mean()函数计算了不同性别的平均收入。
DaPy库的应用场景
DaPy库适用于各种数据处理和分析的场景,包括但不限于:
- 数据清洗和预处理:通过DaPy库的数据清洗和转换函数,开发者可以对数据进行去重、缺失值处理、数据类型转换等预处理操作。
- 数据筛选和排序:DaPy库提供了灵活的数据筛选和排序功能,可以满足开发者对数据进行条件筛选和排序的需求。
- 数据聚合和统计分析:通过DaPy库的聚合和统计函数,开发者可以方便地对数据进行分组聚合、计算统计指标等操作,从而获取对数据的全面认识。
- 大规模数据处理:由于DaPy库采用了优化的算法和数据结构,它在处理大规模数据时表现出色,可以帮助开发者高效地处理海量数据。
- 自定义操作和扩展功能:DaPy库具有良好的可扩展性,开发者可以根据需要自定义函数和操作,以满足特定的数据处理和分析需求。
总结
DaPy是一个功能强大的Python库,专注于数据分析和处理。它提供了丰富的工具和函数,使开发者能够高效地进行数据清洗、转换、筛选和聚合等操作。通过使用DaPy库,开发者可以提升数据分析的效率和准确性,从而得出准确的结论和洞察。无论是进行数据清洗和预处理,还是进行数据筛选和排序,亦或是进行数据聚合和统计分析,DaPy库都能够满足各种数据处理和分析的需求。
Java DB 搬家了?关于 Java DB 地址的常见误解
Java DB,一个基于 Apache Derby 的关系数据库管理系统,以其轻量级、易于部署的特点,深受 Java 开发者的青睐。然而,关于 Java DB 的地址问题,却存在一些常见的误解,导致很多开发者在寻找资源时走弯路。本文将详细阐述 Java DB 的地址问题,并澄清一些误解。
Java DB 没有“新地址”
首先需要明确的是,Java DB 本身并没有一个独立的网站或下载地址。这是因为 Java DB 并非一个独立的项目,而是 Apache Derby 数据库的一个子项目。准确地说,Java DB 是 Sun Microsystems(现已被 Oracle 收购)对 Apache Derby 的一个发行版,它包含了 Derby 的核心引擎以及一些额外的工具和功能。
如何获取 Java DB?
既然 Java DB 没有独立的地址,那么我们如何获取它呢?答案很简单:
- 从 JDK 中获取: Java DB 默认包含在 Java SE Development Kit (JDK) 中。如果你已经安装了 JDK,那么你可以在 JDK 的安装目录下的
db文件夹中找到 Java DB。 - 从 Apache Derby 网站下载: 你也可以从 Apache Derby 的官方网站下载 Derby 的二进制文件或源代码,然后自行构建 Java DB。
为什么会有“新地址”的误解?
之所以会有“Java DB 新地址”的误解,主要是因为以下几个原因:
- 过时的信息: 一些早期的 Java DB 文档或教程可能包含了指向 Sun Microsystems 网站的链接,而这些链接现在已经失效。
- 混淆 Java DB 和 Apache Derby: 有些开发者可能将 Java DB 和 Apache Derby 混淆,认为它们是两个独立的项目,因此会去寻找 Java DB 的独立网站。
- 第三方网站: 一些第三方网站可能提供了 Java DB 的下载链接,但这些链接的可靠性和安全性无法保证。
建议
为了避免混淆和获取可靠的资源,建议开发者遵循以下建议:
- 始终从官方渠道获取 Java DB: 优先从 JDK 中获取 Java DB,或者从 Apache Derby 的官方网站下载 Derby。
- 参考官方文档: 查阅 Oracle 和 Apache Derby 的官方文档,获取最新的信息和资源。
- 谨慎使用第三方网站: 避免从不可靠的第三方网站下载 Java DB,以防安全风险。
总结
Java DB 并没有独立的“新地址”,它始终是 Apache Derby 的一部分。开发者可以通过 JDK 或 Apache Derby 的官方网站获取 Java DB。了解这一点,可以帮助开发者避免误解,更有效地利用 Java DB 进行开发工作。
2023 年,开发者都在用哪个 Python 版本?

Python 作为编程语言界的常青树,其简洁易懂和丰富的生态系统吸引了大批拥趸。然而,Python 版本众多也让不少开发者犯了难:究竟哪个版本才是主流?哪个版本更适合我?
本文将用数据说话,带你一探 Python 版本的江湖地位,并用表格清晰展示不同版本的优缺点,助你做出明智选择。
Python 版本现状一览
| 版本 | 发布时间 | 支持状态 | 主要特点 | 使用率 | 推荐指数 |
|---|---|---|---|---|---|
| Python 2.7 | 2010 年 | 已停止支持 | 经典版本,拥有大量第三方库,但语法和功能相对落后 | < 5% | |
| Python 3.6 | 2016 年 | 安全更新结束 | 引入 f-string、类型注解等实用功能 | < 10% | |
| Python 3.7 | 2018 年 | 安全更新结束 | 新增数据类、延迟加载模块等功能 | < 15% | |
| Python 3.8 | 2019 年 | 安全更新中 | 引入海象运算符、位置参数等语法糖,性能提升 | < 20% | |
| Python 3.9 | 2020 年 | 安全更新中 | 改进类型提示,新增字符串方法和字典合并运算符 | < 30% | |
| Python 3.10 | 2021 年 | 安全更新中 | 引入结构化模式匹配、改进错误提示等 | > 20% |
数据来源:JetBrains 2021 开发者生态系统调查, Stack Overflow 开发者调查
解读:
- Python 3 已经成为绝对主流,使用率超过 95%。
- Python 3.7 以上版本占据了大部分市场份额。
- 最新版本 Python 3.9 和 3.10 势头强劲,功能更丰富,性能更优越。
如何选择适合你的版本?
- 新项目:毫不犹豫地选择最新稳定版 Python 3,享受最新功能和最佳性能。
- 旧项目:如果项目依赖于特定版本的 Python 库,则需要选择兼容的版本。
- 学习目的:如果你是 Python 初学者,建议直接学习最新版本,紧跟技术发展步伐。
特别提醒
- Python 2 已经于 2020 年停止支持,不再进行安全更新和错误修复,强烈建议迁移至 Python 3。
- 选择 Python 版本时,还需要考虑你的操作系统和开发环境是否支持。
总结
Python 版本选择并非一成不变,需要根据具体情况进行权衡。但总体而言,选择最新稳定版 Python 3 是最佳选择,既能享受最新技术带来的便利,又能获得更长久的安全支持。
Python 开发工具哪家强?从入门到大神,总有一款适合你!

Python 作为一门简洁易学、功能强大的编程语言,近年来备受开发者青睐。学习 Python,除了掌握语言本身,选择合适的开发工具也至关重要。一款优秀的开发工具能大幅提升编码效率,让编程过程更加轻松愉悦。
面对市面上琳琅满目的 Python 开发工具,新手往往感到眼花缭乱,不知该如何选择。本文将从不同角度出发,为你推荐几款备受欢迎的 Python 开发工具,助你找到最趁手的那一款!
一、轻量级选手:代码编辑器
代码编辑器以其轻便灵活的特点,成为众多 Python 开发者的首选,尤其适合初学者和进行小型项目开发。
- Visual Studio Code (VS Code):微软出品,必属精品!VS Code 拥有丰富的扩展插件,支持代码高亮、自动补全、调试等功能,几乎可以满足你对代码编辑器的所有需求。其轻量级和跨平台特性也广受好评。
- Sublime Text:以其快速、简洁和强大的功能著称。Sublime Text 支持多种编程语言,并拥有强大的代码编辑功能,例如多行编辑、代码片段等。虽然是付费软件,但可以无限期免费试用。
- Atom:由 GitHub 开发的开源编辑器,拥有时尚的界面和丰富的插件库。Atom 支持多种编程语言,并提供实时协作功能,适合团队合作开发。
二、重量级选手:集成开发环境 (IDE)
集成开发环境 (IDE) 为开发者提供了更全面的功能,包括代码编辑、调试、版本控制等,适合大型项目开发和专业程序员使用。
- PyCharm:JetBrains 出品的 Python IDE,功能强大且易于使用。PyCharm 提供智能代码补全、代码重构、调试、版本控制等功能,并支持 Web 开发框架,例如 Django 和 Flask。
- Spyder:专为科学计算和数据分析设计的 Python IDE,集成了 IPython 控制台、变量浏览器、绘图工具等功能,适合数据科学家和工程师使用。
- Thonny:专为 Python 初学者设计的 IDE,界面简洁直观,易于上手。Thonny 提供代码调试、变量可视化等功能,帮助初学者理解代码执行过程。
三、其他工具
除了代码编辑器和 IDE,还有一些其他工具可以帮助你更好地进行 Python 开发:
- Jupyter Notebook:交互式编程环境,允许你将代码、文本、图像等内容整合到一个文档中,方便进行数据分析、机器学习等工作。
- Anaconda:Python 数据科学平台,预装了 NumPy、Pandas、Scikit-learn 等常用数据科学库,方便进行数据分析和机器学习项目开发。
四、如何选择?
面对如此多的选择,你可能会感到困惑,不知该如何选择。以下是一些建议:
- 初学者:建议从轻量级的代码编辑器开始,例如 VS Code 或 Sublime Text。这些编辑器易于上手,并且可以通过安装插件来扩展功能。
- 专业开发者:可以考虑使用功能更强大的 IDE,例如 PyCharm 或 Spyder。这些 IDE 提供了更全面的功能,可以帮助你更高效地进行开发。
- 数据科学家: 推荐使用 Anaconda 或 Spyder,这些工具集成了常用的数据科学库,并提供了方便的数据分析工具。
五、总结
Python 开发工具的选择没有绝对的对错,最重要的是找到适合自己的那一款。希望本文能帮助你了解不同 Python 开发工具的特点,并根据自身需求做出最佳选择。
最后,请记住,工具只是辅助,更重要的是不断学习和实践,才能成为一名优秀的 Python 开发者!
Java数据类型有哪几种?

在Java编程语言中,数据类型是构建程序的基础。它们决定了变量可以存储的数据种类以及可以对这些数据执行的操作。理解Java数据类型对于编写高效、可靠的代码至关重要。本文将深入探讨Java中的各种数据类型,并解释其用途和区别。
Java数据类型主要分为两大类:
- 基本数据类型 (Primitive Data Types)
- 引用数据类型 (Reference Data Types)
一、基本数据类型
基本数据类型是Java语言预先定义的、最基础的数据类型,用于表示简单的数值、字符和布尔值。Java中有8种基本数据类型,可以进一步细分为四类:
1. 整数类型:
- byte:占用1个字节,取值范围为-128到127。适用于存储小型整数,例如年龄、数量等。
- short:占用2个字节,取值范围为-32,768到32,767。适用于存储稍大范围的整数,例如年份、端口号等。
- int:占用4个字节,取值范围为-2,147,483,648到2,147,483,647。这是最常用的整数类型,适用于存储大多数整数数据,例如数组索引、计数器等。
- long:占用8个字节,取值范围为-9,223,372,036,854,775,808到9,223,372,036,854,775,807。适用于存储极大范围的整数,例如时间戳、文件大小等。
2. 浮点类型:
- float:占用4个字节,用于存储单精度浮点数。适用于存储需要小数部分但精度要求不高的数值,例如温度、汇率等。
- double:占用8个字节,用于存储双精度浮点数。这是最常用的浮点类型,适用于存储需要较高精度的数值,例如科学计算、金融数据等。
3. 字符类型:
- char:占用2个字节,用于存储单个Unicode字符,例如字母、数字、符号等。
4. 布尔类型:
- boolean:占用1个字节,只有两个取值:true和false。适用于表示逻辑状态,例如条件判断、开关状态等。
二、引用数据类型
引用数据类型用于存储对象的引用,即存储对象的内存地址,而不是对象本身。Java中所有的类都是引用数据类型,此外还有数组、接口、枚举等。
- 类 (Class):类是创建对象的蓝图,它定义了对象的属性和方法。例如,String类表示字符串,Date类表示日期和时间。
- 数组 (Array):数组是存储相同类型数据元素的固定长度的集合。例如,int[]表示整型数组,String[]表示字符串数组。
- 接口 (Interface):接口定义了一组方法的签名,但不提供实现。类可以实现接口,从而继承接口定义的方法。
- 枚举 (Enum):枚举定义了一组命名的常量,例如星期几、颜色等。
三、基本数据类型和引用数据类型的区别
| 特性 | 基本数据类型 | 引用数据类型 |
|---|---|---|
| 存储内容 | 实际数据 | 对象的引用(内存地址) |
| 默认值 | 有默认值,例如int为0 | null |
| 传递方式 | 值传递 | 引用传递 |
| 内存分配 | 在栈内存中分配 | 在堆内存中分配 |
四、总结
了解Java数据类型是编写Java程序的基础。正确选择和使用数据类型可以提高程序的效率、可读性和可维护性。选择数据类型时,需要考虑数据的范围、精度和存储空间等因素。
希望本文能够帮助您更好地理解Java数据类型,并在实际编程中做出明智的选择。
Pino:现代化的Node.js日志记录器
在Node.js开发中,日志记录是一个至关重要的组成部分。它帮助开发人员实时监控应用程序的运行状况,捕获错误和异常,并提供有关系统行为的有用信息。Pino是一个流行的Node.js日志记录器,它以其高性能、灵活性和易用性而闻名。
什么是Pino?
Pino是一个轻量级、快速且可扩展的Node.js日志记录器。它的目标是成为最快的Node.js日志记录器之一,并提供简单的API和可插拔的功能,以满足各种日志记录需求。

特点和优势
- 高性能:Pino的设计注重性能,通过采用异步写入和最小的开销来实现出色的性能表现。它是当前最快的Node.js日志记录器之一,可以在高负载环境下保持低延迟。
- 灵活性:Pino提供了丰富的配置选项,可以根据需求进行自定义设置。它允许开发人员选择不同的输出格式(如JSON、纯文本等),设置日志级别、日志目标(如文件、控制台等)以及日志的滚动策略。
- 可扩展性:Pino支持插件机制,可以轻松地扩展其功能。开发人员可以编写自定义插件来实现特定的日志记录需求,例如添加身份验证、请求追踪等功能。
- 零依赖:Pino是一个零依赖的日志记录器,它不依赖于任何其他第三方库。这使得它在安装和使用上更加简单,同时减少了潜在的冲突和兼容性问题。
使用示例
下面是一个简单的示例,展示了如何在Node.js应用程序中使用Pino进行日志记录:
const pino = require('pino');
const logger = pino();
logger.info('Hello, Pino!');
try {
// 一些代码逻辑
} catch (error) {
logger.error(error, 'An error occurred');
}在上面的示例中,我们首先引入了Pino模块,并创建了一个日志记录器实例。然后,我们可以使用不同级别的日志方法(如info和error)记录信息和错误。
生态系统和整合
Pino拥有一个活跃的生态系统,并与其他常用的Node.js工具和框架整合良好。它可以与Express、Koa、Fastify等Web框架无缝集成,还支持与各种存储后端(如Elasticsearch、MongoDB等)和日志分析工具(如Logstash、Splunk等)的整合。
总结
Pino是一个出色的Node.js日志记录器,它以其高性能、灵活性和易用性而受到开发人员的青睐。无论是构建小型应用程序还是大型分布式系统,Pino都提供了强大的日志记录功能,帮助开发人员更好地理解和监控应用程序的运行情况。如果您正在寻找一个现代化的、高性能的Node.js日志记录器,不妨考虑使用Pino。