在当今数字化时代,哈希算法成为了信息安全和数据完整性的关键技术。无论是密码学、数据存储还是网络通信,哈希算法都扮演着重要的角色。本文将深入探究哈希算法,解释其原理、特性以及广泛应用的领域。
哈希算法的原理
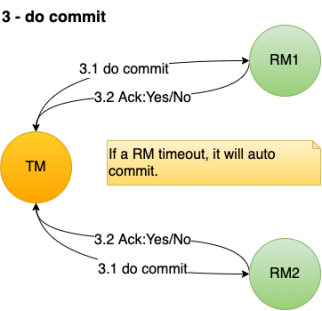
哈希算法是一种将任意长度的输入数据转换为固定长度输出的算法。它通过哈希函数对输入数据进行处理,生成称为哈希值或摘要的固定长度输出。
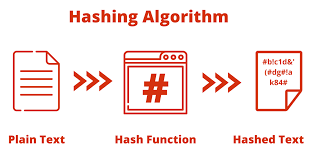
哈希函数的特性
- 确定性:对于相同的输入,哈希函数始终产生相同的哈希值。
- 快速计算:哈希函数能够高效地计算出哈希值。
- 不可逆性:从哈希值无法推导出原始输入数据。
- 雪崩效应:输入数据的微小改变会导致输出哈希值的巨大变化。
哈希算法的应用
- 数据完整性验证哈希算法用于验证数据的完整性。发送方可以通过计算数据的哈希值,并将其附加到数据中。接收方在接收数据后,重新计算哈希值,并与接收到的哈希值进行比较。如果哈希值匹配,说明数据在传输过程中没有被篡改。
- 密码存储哈希算法在密码存储中起到关键作用。而不是直接存储用户密码,网站通常会将密码的哈希值存储在数据库中。当用户尝试登录时,系统会计算输入密码的哈希值,并与数据库中存储的哈希值进行比较。这种方法可以保护用户密码的安全性,即使数据库受到攻击,攻击者也无法轻易还原密码。
- 数据索引和查找哈希算法被广泛用于数据索引和查找。例如,哈希表(Hash Table)是一种基于哈希算法实现的数据结构,它能够以常数时间复杂度进行高效的数据插入、查找和删除操作。哈希索引在数据库和搜索引擎等领域中得到了广泛应用,提高了数据的检索效率。
以下是示例代码,用Python演示了数据完整性验证和密码存储的应用:
import hashlib
# 数据完整性验证
data = "Hello, World!"
original_hash = hashlib.sha256(data.encode()).hexdigest()
# 在传输过程中数据被篡改
modified_data = "Hello, Modified!"
modified_hash = hashlib.sha256(modified_data.encode()).hexdigest()
# 验证数据完整性
if original_hash == modified_hash:
print("数据完整性验证通过")
else:
print("数据完整性验证失败")
# 密码存储
password = "mypassword123"
hashed_password = hashlib.sha256(password.encode()).hexdigest()
# 假设用户输入密码进行登录
login_password = input("请输入密码: ")
hashed_login_password = hashlib.sha256(login_password.encode()).hexdigest()
# 验证密码
if hashed_password == hashed_login_password:
print("密码正确,登录成功")
else:
print("密码错误,登录失败")常见的哈希算法
- MD5(Message Digest Algorithm 5):MD5是一种广泛使用的哈希算法,生成128位的哈希值。然而,由于其安全性被发现存在漏洞,现已不推荐用于密码存储等安全场景。以下是计算MD5哈希值的示例代码:
import hashlib
data = "Hello, World!"
md5_hash = hashlib.md5(data.encode()).hexdigest()
print("MD5 Hash:", md5_hash)- SHA(Secure Hash Algorithm):SHA系列算法是较为安全的哈希算法,包括SHA-1、SHA-256、SHA-512等。SHA-256和SHA-512在密码存储和数字证书等领域广泛应用。以下是计算SHA-256哈希值的示例代码:
import hashlib
data = "Hello, World!"
sha256_hash = hashlib.sha256(data.encode()).hexdigest()
print("SHA-256 Hash:", sha256_hash)哈希算法的局限性与挑战
尽管哈希算法在许多场景下表现出色,但仍存在一些局限性和挑战。例如,碰撞攻击是一种攻击方式,攻击者试图找到两个不同的输入数据,它们产生相同的哈希值。为了应对这些挑战,密码学家和研究人员不断提出新的哈希算法和安全策略。
总结
哈希算法是一种重要的技术,用于数据完整性验证、密码存储、数据索引等多重要领域。它通过将任意长度的输入数据转换为固定长度的哈希值,确保数据的完整性和安全性。尽管存在一些挑战和局限性,但哈希算法在信息安全和数据管理方面的应用仍然不可忽视。深入理解和应用哈希算法,将有助于增强数据保护和安全性,推动数字化时代的发展。