1.什么是跨域
我们常常会在页面上使用 ajax 要求访问其他服务器的数据,此时,客户端会出现跨域问题.
跨域问题是由于 javascript 语言安全限制中的同源策略酿成的.
简单来讲,同源策略是指一段脚本只能读取来自同一来源的窗口和文档的属性,这里的同一来源指的是主机名、协议和端口号的组合.
例如:
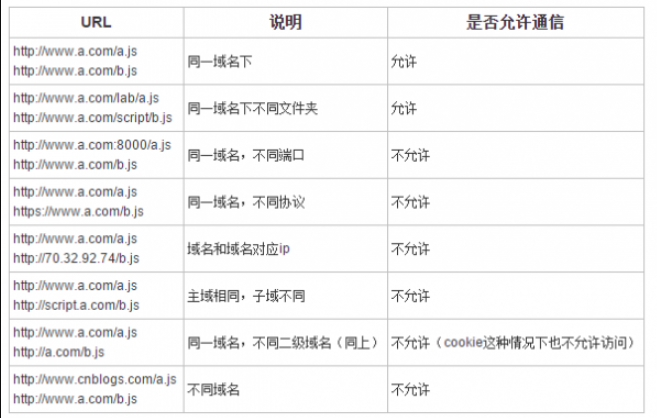
2.实现原理
在 HTML DOM 中,Script 标签是可以跨域访问服务器上的数据的.因此,可以指定 script 的 src 属性为跨域的 url, 从而实现跨域访问.
例如:
这类访问方式是不行的.但是以下方式,却是可以的.
这里对返回的数据有个要求,即:服务器返回的数据不能是单纯的如{“Name”:”zhangsan”}
如果返回的是这个 json 字符串,我们是没有办法援用这个字符串的.所以,要求返回的值,务必是 var json={“Name”:”zhangsan”},或json({“Name”:”zhangsan”})
为了使程序不报错,我们务必还要建立个 json 函数.
3.解决方案
方案1
服务器端:
protected void Page_Load(object sender, EventArgs e)
{
string result = “callback({“name”:”zhangsan”,”date”:”2012⑴2-03″})”;
Response.Clear();
Response.Write(result);
Response.End();
}
客户端:
<!DOCTYPE html PUBLIC “-//W3C//DTD XHTML 1.0 Transitional//EN” “http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd”>
<html xmlns=”http://www.w3.org/1999/xhtml”>
<head>
<title></title>
<script type=”text/javascript”>
var result = null; window.onload = function () {
var script = document.createElement(“script”);
script.type = “text/javascript”;
script.src = “http://192.168.0.101/ExampleBusinessApplication.Web/web2.aspx”;
var head = document.getElementsByTagName(“head”)[0];
head.insertBefore(script, head.firstChild); };
function callback(data) { result = data; }
function b_click() { alert(result.name); }
</script>
</head>
<body>
<input type=”button” value=”click me!” onclick=”b_click();” />
</body>
</html>
方案2,通过 jQuery 来完成
通过jquery的jsonp的方式.使用此方式,对服务器端有要求.
服务器端以下:
protected void Page_Load(object sender, EventArgs e)
{
string callback = Request.QueryString[“jsoncallback”];
string result = callback + “({“name”:”zhangsan”,”date”:”2012⑴2-03″})”;
Response.Clear();
Response.Write(result);
Response.End();
}
客户端:
$.ajax({ async: false, url: “http://192.168.0.5/Web/web1.aspx”, type: “GET”, dataType: ‘jsonp’,
//jsonp的值自定义,如果使用jsoncallback,那么服务器端,要返回一个 jsoncallback 的值对应的对象. jsonp: ‘jsoncallback’,
//要传递的参数,没有传参时,也一定要写上 data: null, timeout: 5000,
//返回Json类型 contentType: “application/json;utf⑻”,
//服务器段返回的对象包括name,data属性.
success: function (result) { alert(result.date); }, error: function (jqXHR, textStatus, errorThrown) { alert(textStatus); } });
实际上,在我们履行这段 js 时,js 向服务器发出了这样一个要求:
http://192.168.0.5/Web/web1.aspx?jsoncallback=jsonp1354505244726&_=1354505244742
而服务器也响应的返回了以下对象:
jsonp1354506338864({“name”:”zhangsan”,”date”:”2012⑴2-03″})
此时就实现了跨域范文数据的要求