演讲者 | 李飞飞
最近研究Vue源码时我发现的一些好玩函数
最近在深入研究 vue 源码,把学习过程中,看到的一些好玩的的函数方法收集起来做分享,希望对大家对深入学习 js 有所帮助。如果大家都能一眼看懂这些函数,说明技术还是不错的哦。
1. 数据类型判断
Object.prototype.toString.call() 返回的数据格式为 [object Object] 类型,然后用 slice 截取第8位到倒一位,得到结果为 Object
var _toString = Object.prototype.toString;
function toRawType (value) {
return _toString.call(value).slice(8, -1)
}运行结果测试
toRawType({}) // Object
toRawType([]) // Array
toRawType(true) // Boolean
toRawType(undefined) // Undefined
toRawType(null) // Null
toRawType(function(){}) // Function2. 利用闭包构造map缓存数据
vue 中判断我们写的组件名是不是 html 内置标签的时候,如果用数组类遍历那么将要循环很多次获取结果,如果把数组转为对象,把标签名设置为对象的 key,那么不用依次遍历查找,只需要查找一次就能获取结果,提高了查找效率。
function makeMap (str, expectsLowerCase) {
// 构建闭包集合map
var map = Object.create(null);
var list = str.split(',');
for (var i = 0; i < list.length; i++) {
map[list[i]] = true;
}
return expectsLowerCase
? function (val) { return map[val.toLowerCase()]; }
: function (val) { return map[val]; }
} // 利用闭包,每次判断是否是内置标签只需调用isHTMLTag
var isHTMLTag = makeMap('html,body,base,head,link,meta,style,title')
console.log('res', isHTMLTag('body')) // true3. 二维数组扁平化
vue中_createElement格式化传入的children的时候用到了simpleNormalizeChildren函数,原来是为了拍平数组,使二维数组扁平化,类似lodash中的flatten方法。
// 先看lodash中的flatten
_.flatten([1, [2, [3, [4]], 5]])
// 得到结果为 [1, 2, [3, [4]], 5]
// vue中
function simpleNormalizeChildren (children) {
for (var i = 0; i < children.length; i++) {
if (Array.isArray(children[i])) {
return Array.prototype.concat.apply([], children)
}
}
return children
}
// es6中 等价于
function simpleNormalizeChildren (children) {
return [].concat(...children)
}4. 方法拦截
vue中利用Object.defineProperty收集依赖,从而触发更新视图,但是数组却无法监测到数据的变化,但是为什么数组在使用push pop等方法的时候可以触发页面更新呢,那是因为 vue 内部拦截了这些方法。
// 重写push等方法,然后再把原型指回原方法
var ARRAY_METHOD = [ 'push', 'pop', 'shift', 'unshift', 'reverse', 'sort', 'splice' ];
var array_methods = Object.create(Array.prototype);
ARRAY_METHOD.forEach(method => {
array_methods[method] = function () {
// 拦截方法
console.log('调用的是拦截的 ' + method + ' 方法,进行依赖收集');
return Array.prototype[method].apply(this, arguments);
}
});运行结果测试
var arr = [1,2,3]
arr.__proto__ = array_methods // 改变arr的原型
arr.unshift(6) // 打印结果: 调用的是拦截的 unshift 方法,进行依赖收集5. 继承的实现
vue 中调用Vue.extend实例化组件,Vue.extend 就是 VueComponent构造函数,而 VueComponent 利用Object.create继承 Vue,所以在平常开发中 Vue 和 Vue.extend区别不是很大。这边主要学习用 es5 原生方法实现继承的,当然了,es6中 class 类直接用 extends 继承。
// 继承方法
function inheritPrototype(Son, Father) {
var prototype = Object.create(Father.prototype)
prototype.constructor = Son
// 把Father.prototype赋值给 Son.prototype
Son.prototype = prototype
}
function Father(name) {
this.name = name
this.arr = [1,2,3]
}
Father.prototype.getName = function() {
console.log(this.name)
}
function Son(name, age) {
Father.call(this, name)
this.age = age
}
inheritPrototype(Son, Father)
Son.prototype.getAge = function() {
console.log(this.age)
}运行结果测试
var son1 = new Son("AAA", 23)
son1.getName() //AAA
son1.getAge() //23
son1.arr.push(4)
console.log(son1.arr) //1,2,3,4
var son2 = new Son("BBB", 24)
son2.getName() //BBB
son2.getAge() //24
console.log(son2.arr) //1,2,36. 执行一次
once 方法相对比较简单,直接利用闭包实现就好了
function once (fn) {
var called = false;
return function () {
if (!called) {
called = true;
fn.apply(this, arguments);
}
}
}7. 浅拷贝
简单的深拷贝我们可以用 JSON.stringify() 来实现,不过vue 源码中的looseEqual 浅拷贝写的也很有意思,先类型判断再递归调用,总体也不难,学一下思路。
function looseEqual (a, b) {
if (a === b) { return true }
var isObjectA = isObject(a);
var isObjectB = isObject(b);
if (isObjectA && isObjectB) {
try {
var isArrayA = Array.isArray(a);
var isArrayB = Array.isArray(b);
if (isArrayA && isArrayB) {
return a.length === b.length && a.every(function (e, i) {
return looseEqual(e, b[i])
})
} else if (!isArrayA && !isArrayB) {
var keysA = Object.keys(a);
var keysB = Object.keys(b);
return keysA.length === keysB.length && keysA.every(function (key) {
return looseEqual(a[key], b[key])
})
} else {
/* istanbul ignore next */
return false
}
} catch (e) {
/* istanbul ignore next */
return false
}
} else if (!isObjectA && !isObjectB) {
return String(a) === String(b)
} else {
return false
}
}
function isObject (obj) {
return obj !== null && typeof obj === 'object'
} 以上就是W3Cschool编程狮关于最近研究Vue源码时我发现的一些好玩函数的相关介绍了,希望对大家有所帮助。
从小白到高手,你需要理解同步与异步(内含10张图)
在这篇文章中我们来讨论一下到底什么是同步,什么是异步,以及在编程中这两个极为重要的概念到底意味着什么。
相信很多同学遇到同步异步这两个词的时候大脑瞬间就像红绿灯失灵的十字路口一样陷入一片懵逼的状态:

是的,这两个看上去很像实际上也很像的词汇给博主造成过很大的困扰,这两个词背后所代表的含义到底是什么呢?
我们先从工作场景讲起。
苦逼程序员
假设现在老板分配给了你一个很紧急并且很重要的任务,让你下班前必须完成(万恶的资本主义)。为了督促进度,老板搬了个椅子坐在一边盯着你写代码。
你心里肯定已经骂上了,“WTF,你有这么闲吗?盯着老子,你就不能去干点其他事情吗?”
老板仿佛接收到了你的脑电波一样:“我就在这等着,你写完前我哪也不去,厕所也不去。”
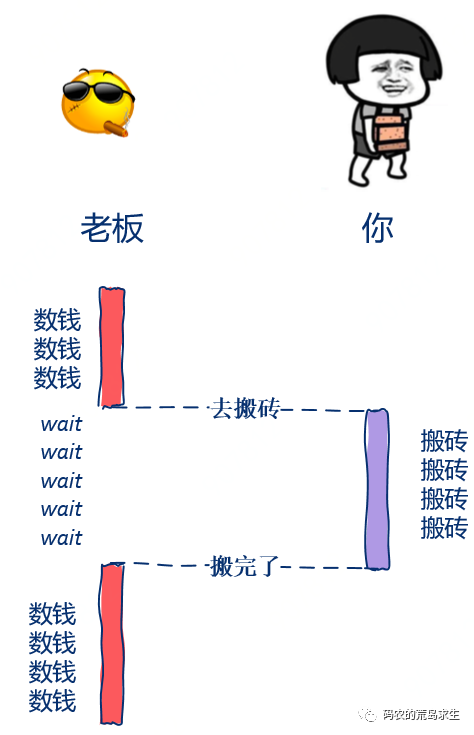
这个例子中老板交给你任务后就一直等待,什么都不做直到你写完,这个场景就是所谓的同步。
第二天,老板又交给了你一项任务。
不过这次就没那么着急啦,这次老板轻描淡写,“小伙子可以啊,不错不错,你再努力干一年,明年我就财务自由了,今天的这个任务不着急,你写完告诉我一声就行”。
这次老板没有盯着你写代码,而是转身刷视频去了,你写完后简单的和老板报告一声“我写完了”。
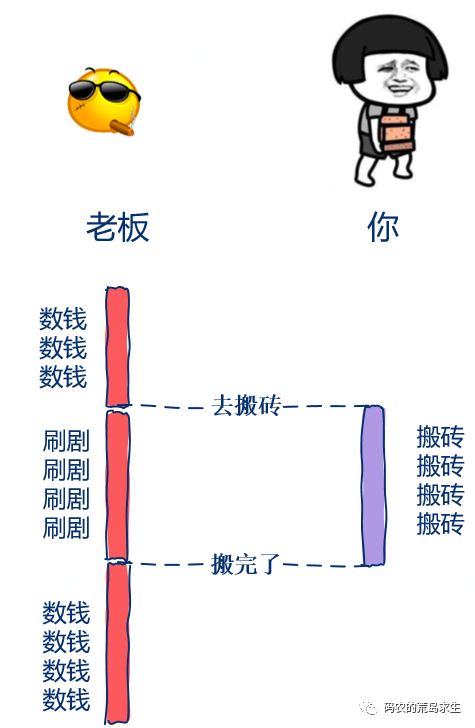
在这个例子中老板交代完任务后不再一直等着什么都不做而是就去忙其它事情,你完成任务后简单的告诉老板任务完成,这就是所谓的异步。
值得注意的是,在异步这种场景下重点是在你写代码的同时老板在刷剧,这两件事在同时进行,而不是一方等待另一方,因此这就是为什么一般来说异步比同步高效的本质所在,不管同步异步应用在什么场景下。
我们可以看到同步这个词往往和任务的“依赖”、“关联”、“等待”等关键词相关,而异步往往和任务的“不依赖”,“无关联”,“无需等待”,“同时发生”等关键词相关。
By the way,如果遇到一个在身后盯着你写代码的老板,三十六计走为上策。
打电话与发邮件
作为一名苦逼的程序员是不能只顾埋头搬砖的,平时工作中的沟通免除不了,其中一种高效的沟通方式是吵架。。。啊不,是电话。

通常打电话时都是一个人在说另一个人听,一个人在说的时候另一个人等待,等另一个人说完后再接着说,因此在这个场景中你可以看到,“依赖”、“关联”、“等待”这些关键词出现了,因此打电话这种沟通方式就是所谓的同步。
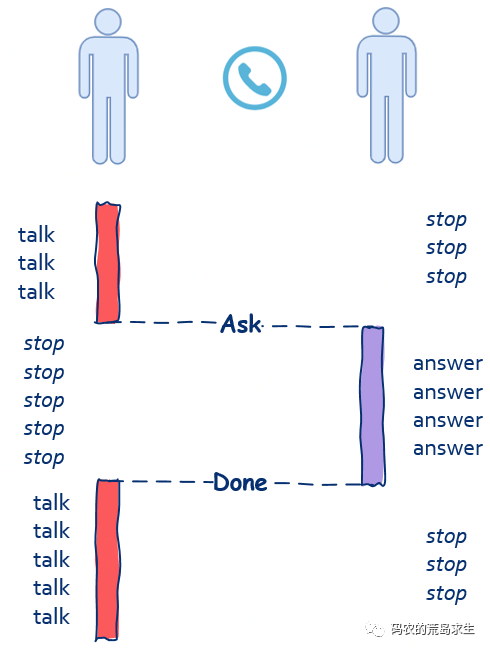
另一种码农常用的沟通方式是邮件。
邮件是另一种必不可少沟通方式,因为没有人傻等着你写邮件什么都不做,因此你可以慢慢悠悠的写,当你在写邮件时收件人可以去做一些像摸摸鱼啊、上个厕所、和同时抱怨一下为什么十一假期不放两周之类有意义的事情。
同时当你写完邮件发出去后也不需要干巴巴的等着对方回复什么都不做,你也可以做一些像摸鱼之类这样有意义的事情。

在这里,你写邮件别人摸鱼,这两件事又在同时进行,收件人和发件人都不需要相互等待,发件人写完邮件的时候简单的点个发送就可以了,收件人收到后就可以阅读啦,收件人和发件人不需要相互依赖、不需要相互等待。
你看,在这个场景下“不依赖”,“无关联”,“无需等待”这些关键词就出现了,因此邮件这种沟通方式就是异步的。
同步调用
现在终于回到编程的主题啦。
既然现在我们已经理解了同步与异步在各种场景下的意义(I hope so),那么对于程序员来说该怎样理解同步与异步呢?
我们先说同步调用,这是程序员最熟悉的场景。
一般的函数调用都是同步的,就像这样:
funcA() {
// 等待函数funcB执行完成
funcB();
// 继续接下来的流程
} funcA 调用 funcB,那么在 funcB 执行完前,funcA 中的后续代码都不会被执行,也就是说 funcA 必须等待 funcB 执行完成,就像这样:
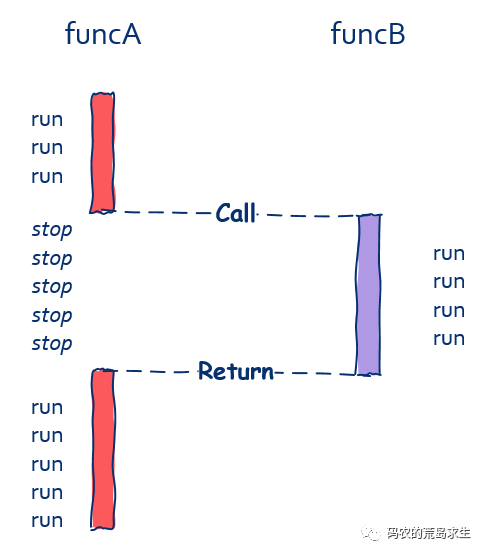
从上图中我们可以看到,在funcB运行期间funcA什么都做不了,这就是典型的同步。
注意,一般来说,像这种同步调用,funcA和funcB是运行在同一个线程中的,这是最为常见的情况。
但值得注意的是,即使运行在两个不能线程中的函数也可以进行同步调用,像我们进行 IO 操作时实际上底层是通过系统调用的方式向操作系统发出请求的,比如磁盘文件读取:
read(file, buf); 这就是阻塞式 I/O,在read函数返回前程序是无法继续向前推进的
read(file, buf);
// 程序暂停运行,
// 等待文件读取完成后继续运行如图所示:
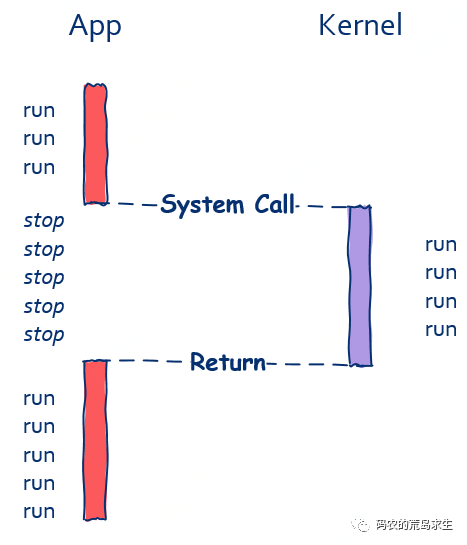
只有当read函数返回后程序才可以被继续执行。
注意,和上面的同步调用不同的是,函数和被调函数运行在不同的线程中。
因此我们可以得出结论,同步调用和函数与被调函数是否运行在同一个线程是没有关系的。
在这里我们还要再次强调,同步方式下函数和被调函数无法同时进行。
同步编程对程序员来说是最自然最容易理解的。
但容易理解的代价就是在一些场景下,同步并不是高效的,原因很简单,因为任务没有办法同时进行。
接下来我们看异步调用。
异步调用
有同步调用就有异步调用。
如果你真的理解了本节到目前为止的内容的话,那么异步调用对你来说不是问题。
一般来说,异步调用总是和 I/O 操作等耗时较高的任务如影随形,像磁盘文件读写、网络数据的收发、数据库操作等。
我们还是以磁盘文件读取为例。
在read函数的同步调用方式下,文件读取完之前调用方是无法继续向前推进的,但如果read函数可以异步调用情况就不一样了。
假如read函数可以异步调用的话,即使文件还没有读取完成,read函数也可以立即返回。
read(file, buff);
// read函数立即返回
// 不会阻塞当前程序就像这样:
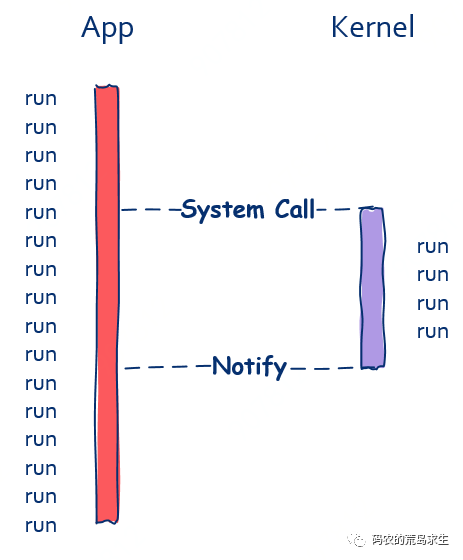
可以看到,在异步这种调用方式下,调用方不会被阻塞,函数调用完成后可以立即执行接下来的程序。
这时异步的重点就在于调用方接下来的程序执行可以和文件读取同时进行,从上图中我们也能看出这一点,这就是异步的高效之处。
但是,请注意,异步调用对于程序员来说在理解上是一种负担,代码编写上更是一种负担,总的来说,上帝在为你打开一扇门的时候会适当的关上一扇窗户。
有的同学可能会问,在同步调用下,调用方不再继续执行而是暂停等待,被调函数执行完后很自然的就是调用方继续执行,那么异步调用下调用方怎知道被调函数是否执行完成呢?
这就分为了两种情况:
- 调用方根本就不关心执行结果
- 调用方需要知道执行结果
第一种情况比较简单,无需讨论。
第二种情况下就比较有趣了,通常有两种实现方式:
一种是通知机制,也就是说当任务执行完成后发送信号来通知调用方任务完成,注意这里的信号有很多实现方式,Linux 中的signal,或者使用信号量等机制都可以实现。
另一种是就是回调,也就是我们常说的callback,关于回调我们将在下一篇文章中重点讲解,本篇会有简短的讨论。
接下来我们用一个具体的例子讲解一下同步调用与异步调用。
同步 VS 异步
我们以常见的 Web 服务来举例说明这一问题。
一般来说 Web Server 接收到用户请求后会有一些典型的处理逻辑,最常见的就是数据库查询(当然,你也可以把这里的数据库查询换成其它 I/O 操作,比如磁盘读取、网络通信等),在这里我们假定处理一次用户请求需要经过步骤 A、B、C,然后读取数据库,数据库读取完成后需要经过步骤 D、E、F,就像这样:
# 处理一次用户请求需要经过的步骤:
A;
B;
C;
数据库读取;
D;
E;
F;其中步骤 A、B、C 和 D、E、F 不需要任何 I/O ,也就是说这六个步骤不需要读取文件、网络通信等,涉及到 I/O 操作的只有数据库查询这一步。
一般来说这样的 Web Server 有两个典型的线程:主线程和数据库处理线程,注意,这讨论的只是典型的场景,具体业务实际上可会有差别,但这并不影响我们用两个线程来说明问题。
首先我们来看下最简单的实现方式,也就是同步。
这种方式最为自然也最为容易理解:
// 主线程
main_thread() {
A;
B;
C;
发送数据库查询请求;
D;
E;
F;
}
// 数据库线程
DataBase_thread() {
while(1) {
处理数据库读取请求;
返回结果;
}
}这就是最为典型的同步方法,主线程在发出数据库查询请求后就会被阻塞而暂停运行,直到数据库查询完毕后面的 D、E、F 才可以继续运行,就像这样:
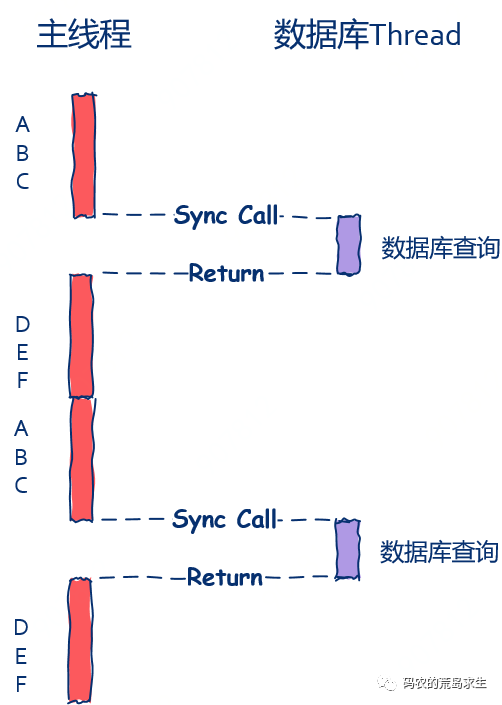
从图中我们可以看到,主线程中会有“空隙”,这个空隙就是主线程的“休闲时光”,主线程在这段休闲时光中需要等待数据库查询完成才能继续后续处理流程。
在这里主线程就好比监工的老板,数据库线程就好比苦逼搬砖的程序员,在搬完砖前老板什么都不做只是紧紧的盯着你,等你搬完砖后才去忙其它事情。
显然,高效的程序员是不能容忍主线程偷懒的。
是时候祭出大杀器了,这就是异步。
在异步这种实现方案下主线程根本不去等待数据库是否查询完成,而是发送完数据库读写请求后直接处理下一个请求。
有的同学可能会有疑问,一个请求需要经过 A、B、C、数据库查询、D、E、F 这七个步骤,如果主线程在完成 A、B、C、数据库查询后直接进行处理接下来的请求,那么上一个请求中剩下的 D、E、F 几个步骤怎么办呢?
如果大家还没有忘记上一小节内容的话应该知道,这有两种情况,我们来分别讨论。
1,主线程不关心数据库操作结果
在这种情况下,主线程根本就不关心数据库是否查询完毕,数据库查询完毕后自行处理接下来的 D、E、F 三个步骤,就像这样:

看到了吧,接下来重点来了哦。
我们说过一个请求需要经过七个步骤,其中前三个是在主线程中完成的,后四个是在数据库线程中完成的,那么数据库线程是怎么知道查完数据库后要处理 D、E、F 这几个步骤呢?
这时,我们的另一个主角回调函数就开始登场啦。
没错,回调函数就是用来解决这一问题的。
我们可以将处理 D、E、F 这几个步骤封装到一个函数中,假定将该函数命名为handle_DEF_after_DB_query:
void handle_DEF_after_DB_query () {
D;
E;
F;
}这样主线程在发送数据库查询请求的同时将该函数一并当做参数传递过去:
DB_query(request, handle_DEF_after_DB_query); 数据库线程处理完后直接调用handle_DEF_after_DB_query就可以了,这就是回调函数的作用。
也有的同学可能会有疑问,为什么这个函数要传递给数据库线程而不是数据库线程自己定义自己调用呢?
因为从软件组织结构上讲,这不是数据库线程该做的工作。
数据库线程需要做的仅仅就是查询数据库、然后调用一个处理函数,至于这个处理函数做了些什么数据库线程根本就不关心,也不应该关心。
你可以传入各种各样的回调函数。也就是说数据库系统可以针对回调函数这一抽象的函数变量来编程,从而更好的应对变化,因为回调函数的内容改变不会影响到数据库线程的逻辑,而如果数据库线程自己定义处理函数那么这种设计就没有灵活性可言了。
而从软件开发的角度看,假设数据库线程逻辑封装为了库提供给其它团队,当数据库团队在研发时怎么可能知道数据库查询后该做什么呢?
显然,只有使用方才知道查询完数据库后该做些什么,因此使用方在使用时简单的传入这个回调函数就可以了。
这样复杂数据库的团队就和使用方团队实现了所谓的解耦。
现在你应该明白回调函数的作用了吧。
如果你觉得有帮到你,请伸出你的小手帮忙分享再看一下,原创不易,你的一个在看是对博主最大的肯定,拜托大家啦。

不容易啊,容我喝口水叉会儿腰歇一歇。
我们继续。
另外仔细观察上面两张图,你能看出为什么异步比同步高效吗?
原因很简单,这也是我们在本篇提到过的,异步天然就无需等待,无依赖。
从上一张图中我们可以看到主线程的“休闲时光”不见了,取而代之的是不断的工作、工作、工作,就像苦逼的 996 程序员一样,而且数据库线程也没有那么大段大段的空闲了,取而代之的也是工作、工作、工作。

主线程处理请求和数据库处理查询请求可以同时进行,因此从系统性能上看,这样的设计能更加充分的利用系统资源,更加快速的处理请求;从用户的角度看,系统的响应也会更加迅速。
这就是异步的高效之处。
但我们应该也可以看出,异步编程并不如同步来的容易理解,系统可维护性上也不如同步模式。
那么有没有一种方法既能结合同步模式的容易理解又能结合异步模式的高效呢?答案是肯定的,我们将在后续章节详细讲解这一技术。
接下来我们看第二种情况,那就是主线程需要关心数据库查询结果。
2. 主线程关心数据库操作结果
在这种情况下,数据库线程需要将查询结果利用通知机制发送给主线程,主线程在接收到消息后继续处理上一个请求的后半部分,就像这样:
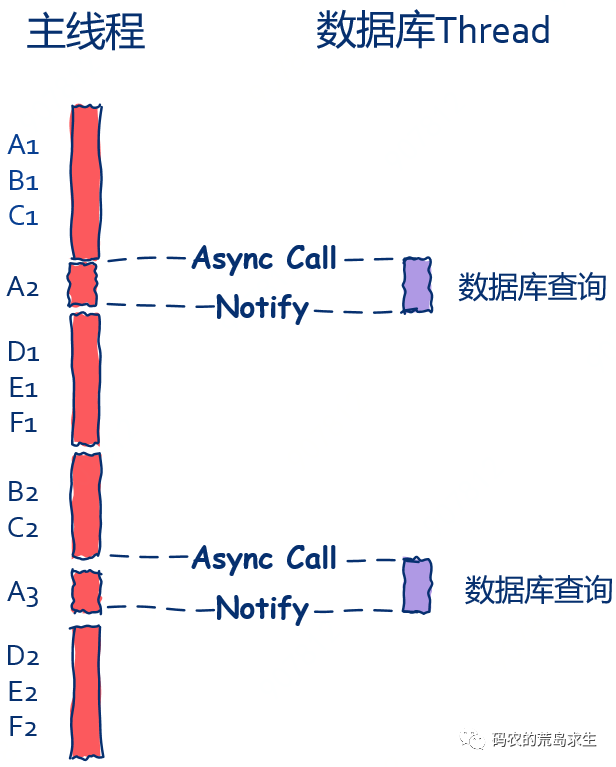
从这里我们可以看到,ABCDEF 几个步骤全部在主线中处理,同时主线程同样也没有了“休闲时光”,只不过在这种情况下数据库线程是比较清闲的,从这里并没有上一种方法高效,但是依然要比同步模式下要高效。
最后需要注意的是,并不是所有的情况下异步都一定比同步高效,还需要结合具体业务以及 IO 的复杂度具体情况具体分析。
总结
在这篇文章中我们从各种场景分析了同步与异步这两个概念,但是不管在什么场景下,同步往往意味着双方要相互等待、相互依赖,而异步意味着双方相互独立、各行其是。希望本篇能对大家理解这两个重要的概念有所帮助。
来源:公众号
作者: 码农的荒岛求生
2020年国内常用开源镜像站大全
什么是开源镜像站?
开源镜像站即一个放置开源系统镜像文件的站点。免费提供镜像文件下载下来可以刻盘也可以直接用虚拟光驱安装操作系统,开源的软件,LINUX 源码网站。
开源镜像站是干嘛的?
其作用是免费提供镜像文件下载。我们在编程开发过程中肯定要下载一些开源软件,但是这些国外软件的官网由于众所周知的原因,经常不稳定:打开很慢,甚至打不开,所以提供极速全面稳定的系统镜像服务就显得尤为必要。
目前很多国内的知名平台都提供了这些开源软件的镜像下载服务,以下为 w3cschool 为同学们整理的2020年国内最新、最常用的一些国内开源镜像站汇总,欢迎参考!
国内开源镜像站汇总(2020)
站点版
| 名称 | 地址 |
|---|---|
| 阿里开源镜像站 | developer.aliyun.com/mirror/ |
| 腾讯软件源 | mirrors.cloud.tencent.com/ |
| 网易开源镜像站 | mirrors.163.com/ |
| 华为开源镜像站 | mirrors.huaweicloud.com/ |
| 搜狐开源镜像站 | mirrors.sohu.com/ |
教育站
| 名称 | 地址 |
|---|---|
| 清华大学 | mirrors.tuna.tsinghua.edu.cn/ |
| 中国科技大学 | mirrors.ustc.edu.cn/ |
| 北京交通大学 | mirror.bjtu.edu.cn/cn/ |
| 上海交通大学 | ftp.sjtu.edu.cn/ |
| 北京理工大学 | mirror.bit.edu.cn/web/ |
| 浙江大学 | mirrors.zju.edu.cn |
| 北京理工大学 | mirror.bit.edu.cn |
| 华中科技大学 | mirrors.hust.edu.cn/ |
官方镜像
非国内镜像
| 名称 | 地址 |
|---|---|
| CentOS | mirror-status.centos.org/#cn |
| Archlinux | archlinux.org/mirrors/status/ |
| Ubuntu | launchpad.net/ubuntu/+cdmirrors |
| Debian | mirror.debian.org/status.html |
| Fedora Linux/Fedora EPEL | admin.fedoraproject.org/mirrormana |
| Apache | apache.org/mirrors/#cn |
| Cygwin | cygwin.com/mirrors.html |
开源镜像站哪个好?
主要从稳定性和速度方面考虑,国内有些镜像站时间久了无人维护,或者关闭,我个人一般常用的是阿里开源镜像站和华为开源镜像站。
开源镜像站怎么用?
直接打开如上网址,找到自己所需的软件,下载即可!
开源镜像站版权
用户在使用开源产品时,不但需表明产品来自开源软件和注明源代码编写者姓名,而且还应把所修改产品返回给开源软件,否则所修改产品就可视为侵权。目前,国内的盗版很泛滥,即便闭源的软件,都会被肆意盗版甚至篡改版权,开源软件就更别说了,篡改版权就是个查找替换的简单操作而已。版权意识的淡漠才是国内开源发展的最大障碍。
相关阅读
- 2020年10月编程语言排行榜:Python 即将超越 Java
- GitHub 全球开发者榜单 TOP200
- GitHub 优质开源项目与资源 2020版
- GitHub 2020精选实战项目
- Google 开源项目风格指南 (中文版)
- 开源软件架构
- 开源软件指南

10 个你可能还不知道 VS Code 使用技巧
- 作者:梧忌
- 来源:淘系前端团队

经常帮一些同学 One-on-One 地解决问题,在看部分同学使用 VS Code 的时候,有些蹩脚,实际上一些有用的技巧能够提高我们的日常工作效率。
一、重构代码
VS Code 提供了一些快速重构代码的操作,例如:
将一整段代码提取为函数:选择要提取的源代码片段,然后单击做成槽中的灯泡查看可用的重构操作。代码片段可以被提取到一个新方法中,或者在不同的范围内(当前闭包、当前函数内、当前类中、当前文件内)提取到一个新函数中。在提取重构期间,VS Code 会引导为该函数进行命名。

将表达式提取到常量:为当前选定的表达式创建新的常量。

移动到新的文件:将指定的函数移动到新的文件,VS Code 将自动命名并创建文件,且在当前文件内引入新的文件。

转换导出方式:export const name 或者 export default。

合并参数:将函数的多个参数合并为单个对象参数:
![]()
参考: 重构操作 、JS/TS 重构操作
二、自定义视图布局
VS Code 的布局系统非常灵活,可以在工作台上的活动栏、面板中移动视图。

参考:重新排列视图
三、快速调试代码
在 VS Code 内调试 JS/TS 代码非常简单,只需要使用 Debug: Open Link 命令即可。这在调试前端或 Node 项目时非常有用,这类型的项目通常会启动一个本地服务,这时候只需要将本地服务地址填写到 Debug: Open Link 输入框中即可。

参考:Debug
四、查看和更新符号的引用
查看符号的引用、快速修改引用的上下文:例如,快速预览某个函数在哪些地方被调用了及其调用时上下文,还可以在预览视图中更新调用上下文的代码。

重命名符号及其引用:接着上面的例子,如果想更新函数名以及所有调用,怎么实现?按 F2 键,然后键入所需的新名称,再按 Enter 键进行提交。符号的所有引用都将被重命名,该操作还是跨文件的。

参考:Peek 、Rename Symbol
五、符号导航
在查看一个长文件的时候,代码定位会是非常痛苦的事情。一些开发者会使用 VS Code 的小地图,但其实还有更便捷的方法:可以使用 ⇧⌘O 快捷键唤起符号导航面板,在当前编辑的文件中通过符号快速定位代码。在输入框中键入字符可以进行筛选,在列表中通过箭头来进行上下导航。这种方式对于 Markdown 文件也非常友好,可以通过标题来快速导航。

参考:Go to Symbol
六、拆分编辑器
当对内容特别多的文件进行编辑的时候,经常需要在上下文中进行切换,这时候可以通过拆分编辑器来使用两个编辑器更新同一个文件:按下快捷键 ⌘\ 将活动编辑器拆分为两个。

可以继续无尽地拆分编辑器,通过拖拽编辑器组的方式排列编辑器视图。

七、重命名终端
VS Code 提供了集成终端,可以很方便地快速执行命令行任务。用得多了经常会打开多个终端,这时候给终端命名可以提高终端定位的效率。

八、Git 操作
VS Code 内置了 Git 源代码管理功能,提供了一些便捷的 Git 操作方式。例如:
解决冲突:VS Code 会识别合并冲突,冲突的差异会被突出显示,并且提供了内联的操作来解决冲突。

暂存或撤销选择的代码行:在编辑器内可以针对选择的行来撤销修改、暂存修改、撤销暂存。

九、搜索结果快照
VS Code 提供了跨文件搜索功能,搜索结果快照可以提供更多的搜索结果的信息,例如代码所在行码、搜索关键字的上下文,并且可以对搜索结果进行编辑和保存。

十、可视化搭建页面
在 VS Code 中可以通过可视化搭建的方式生成 Web 页面,这是通过安装 VS Code 的 Iceworks 插件实现的。安装插件后,通过 ⇧⌘P 唤起命名面板,在命令面板中输入『可视化搭建』即可唤起可视化搭建界面,在界面内通过选择网页元素、进行拖拽布局、设置元素样式和属性来搭建页面,最后点击『生成代码』就可以生成 React 代码。

相关阅读
工程师的基本功是什么?该如何练习?听听美团技术大咖怎么说
- 作者:美团技术学院
- 来源:美团技术团队
在美团有一句老话,叫做“苦练基本功”。美团创始人王兴解读的基本功是业务和管理的基本动作。只要能把基本功扎实练好,就能产生巨大价值。然而滴水石穿非一日之功,练好基本功是一个长期的事情。
苦练基本功,我们要调整好心态面对长期的挑战,同时在重复工作中得到自我提升,将简单的事情做到更好,将我们的能力提高一大截。
那么对于技术团队来说,专业基本功是什么?又该如何练习呢?一起听听美团技术大咖是如何理解技术基本功的吧……
技术基本功存在于每一行代码中
@美团金融技术负责人
“好” 的程序员和 “差” 的程序员,一般来讲都可以实现同样的需求。但是,他们写出来的程序在效率、质量、可维护性、可读性、可扩展性等维度可能存非常明显的差别,这种差别很大程度上取决于他们的技术基本功。 技术基本功存在于每一个项目、每一个代码文件、每一行代码中,是需要技术同学持续积累、持续锻炼的。 如何练好技术基本功?我认为最关键的是要不满足于仅搞定当下的需求,还要不断对自己提出更高的要求——Bug 能否更少?以前趟过的坑是否可以避免?能否满足未来变化的需求?是否可以做到代码即文档?只有不断提高标准,持续地实践,才能不断打磨好基本功,让自己变得更加优秀。
把基础技能练扎实,就能形成肌肉记忆
@美团平台技术负责人
技术基本功就是我们在从事技术工作过程中最基础的技能。把基础技能练扎实,就能形成肌肉记忆,收获的不仅是工作交付的质量变得更高,更重要的是工作也会变得更高效。只有这样,我们才可能有更多的时间和精力学习更高的技能,负责更复杂、更重要的工作。 我认为的技术基本功,应该包括计算机技术基础知识、编程规范与原则、设计模式、单元测试等等。而技术基本功的特征是那些最通用、最泛用的基础技能,不受具体业务或问题的束缚,不受技术角色与水平的束缚,也不受实现路径与方法的束缚。 如何练好呢?一是学习行业标准的基础技能,不断提升自己的认知;二是经年累月的大量实践;三是经常总结复盘,Review自己过去的工作,不断找到待提升点。
基本功易学难精,并具备持续的可提升性
@美团快驴技术负责人
一万小时定律说:“人们眼中的天才之所以卓越非凡,并非天资超人一等,而是付出了持续不断的努力。1万小时的锤炼,是任何人从平凡变成世界级大师的必要条件”。对技术同学来说更是如此。
基本功是基础的知识和技能,易学难精,并具备持续的可提升性,反复训练提升后才能发挥巨大的价值。建议大家能够保持好奇心,坚持深度思考,脚踏实地,追求卓越,长期有耐心。
练习基本功没有捷径
@美团到店餐饮技术负责人
技术基本功决定了公司整体的技术水平,也是区别工程师段位的重要特征。对工程师而言,设计、编码、定位 Bug 是三项重要的基本功。技术基本功不易衡量和考核,它的提升更多源于工程师内心的技术理想以及把技术工作做到极致的态度。
练习基本功也没有捷径,需要务实的心态、严谨的逻辑。当然,每一次设计、编码和 Bug 定位都是提升技术基本功的机会。此外,阶段性复盘对工作的持续提升也有帮助。
用最高的工作标准牵引基本功的锻炼
@美团交通技术负责人
技术基本功,应该是工程师日常工作中高频发生的动作,比如做设计、写代码、Code Review、问题排查等等,是每一个工程师都必须掌握并且可锻炼提升的一些基本能力。只有基本功动作过硬,才能赢得团队信任,才能持续攻下山头,最终拿到业务结果,实现个人的成长。 在训练方法上,我认为重要的一点是坚持在日常工作中「追求卓越」,用最高的工作标准牵引基本功的锻炼,然后通过基本功提升来支撑更高的交付标准。希望大家能够认识到技术基本功的重要性,提高苦练技术基本功的意识,并在日常工作中对其反复锻炼和提升。

写在后面
除了技术大咖的分享之外,我们也为大家准备了美团技术团队工程师此前写的两篇成长心法。
第一篇是《工程师如何在工作中提升自己?》,古人云:“活到老,学到老。”互联网技术日新月异,很多工程师都疲于应付,叫苦不堪。如何在繁忙的工作中做好技术积累,构建个人核心竞争力,相信是很多工程师同行都在思考的问题:
- 文章的第一部分阐述了一些学习的原则。任何时候,遵循一些经过检验的原则,这些都是影响效率的重要因素,正确的方法是成功的秘诀。
- 提升工作和学习效率的另一个重要因素是释惑和良好心态。第二部分分析了作者在工作中碰到和看到的一些典型困惑。
- 成为优秀的架构师是大部分初中级工程师的阶段性目标。第三部分剖析架构师的能力模型,让大家对目标所需能力有一个比较清晰的认知。
第二篇是《写给工程师的十条精进原则》,作者分享了自己用8年的时间从一个职场小白逐步成长为一名技术 Leader 的经验。
很多技术同学工作中并不是不努力,但收效甚微,到底是哪里出了问题呢?经过一段时间的观察与思考后,作者总结了很重要的一项原因:大多数同学在工作中缺乏原则的指导。原则,犹如指引行动的“灯塔”,它连接着我们的价值观与行动。
桥水基金创始人雷·达里奥在《原则》一书中写道,我们每个人都应该有自己的原则,当我们需要作出选择时,一定要坚持以原则为中心。这篇文章总结了十条工程师的精进原则:
- 原则一:Owner意识
- 原则二:时间观念
- 原则三:以终为始
- 原则四:闭环思维
- 原则五:保持敬畏
- 原则六:事不过二
- 原则七:设计优先
- 原则八:产出/产能平衡
- 原则九:善于提问
- 原则十:空杯心态
以上这些原则有的侧重于个人做事情的方法,比如“Owner 意识”、“时间观念”、“以终为始”、”闭环思维”等等;有的侧重于团队工作标准规范,如“保持敬畏”、“事不过二”、“设计优先”等等;有的侧重于团队或个人效能提升,如“产出与产能平衡”、“善于提问”、“空杯心态”等等。这些原则也是作者多年在工作与学习中,不断总结得来的经验。希望对大家的进阶成长能够有所帮助。
招聘信息
美团技术运营团队纳新啦!这是一个温馨有爱且非常重视学习和成长的小团队,做的事情有意思也很有挑战。加入我们的话,你可以跟美团近万名优秀工程师同学打交道,你能够接触到很多前沿的技术、思想,还能近距离接触很多业界的技术牛人……
期待优秀的你加入我们,欢迎大家自荐或者推荐~ ~
岗位职责
- 根据公司战略方向,规划公司内外支持研发团队的运营项目,包括内容产出、线上线下活动策划组织等。
- 有效拓展、运营、维护传播渠道,建立完善的合作、传播机制和体系。
- 独立负责项目的实施,通过与项目相关方沟通获取必备资源,通过数据分析评估各类运营动作的效果。
- 有效整合各方资源,促进公司内部研发团队的分享交流,提升研发团队对外的技术影响力。
任职要求
- 喜欢和研发同学打交道,了解他们的喜怒哀乐。
- 本科及以上学历,3年以上运营工作经验。
- 思路清晰,注重细节,具备较好的数据分析和时间管理能力。
- 有责任感,聪明并热爱学习,自信开朗。
- 优秀的文字功底和表达能力,一定的活动/会议/展览组织、执行能力,有产品或用户运营、项目管理、市场文案及编辑记者经验者优先。
感兴趣的同学可投递简历至:tech@meituan.com(邮件标题注明:技术运营)
相关阅读
规范 GIT 代码提交信息 & 自动化版本管理
前言
git作为一个开发人员必不可少的工具,代码提交也是日常一个非常频繁的操作,如果你或你的团队目前对提交信息还没有一个规范或约束,那么你有必要看看本文的内容了。
为什么要规范提交信息
首先规范提交信息肯定是有必要的,简单总结下几点好处:
- 让项目的维护或使用人员能了解提交了哪些更改
- 清晰的历史记录,可能某天自己就需要查到呢
- 规范的提交记录可用于自动生成修改日志(CHANGELOG.MD)
- 基于提交类型,触发构建和部署流程
使用什么规范
Conventional Commits(约定式提交规范),是目前使用最广泛的提交信息规范,其主要受AngularJS规范 的启发,下面是一个规范信息的结构:
[optional scope]:
//空一行
[optional body]
//空一行
[optional footer(s)]规范说明
type 提交的类别,必须是以下类型中的一个
feat:增加一个新功能
fix:修复bug
docs:只修改了文档
style:做了不影响代码含义的修改,空格、格式化、缺少分号等等
refactor:代码重构,既不是修复bug,也不是新功能的修改
perf:改进性能的代码
test:增加测试或更新已有的测试
chore:构建或辅助工具或依赖库的更新 scope 可选,表示影响的范围、功能、模块
subject 必填,简单说明,不超过 50个字
body 选填,用于填写更详细的描述
footer 选填,用于填关联issus,或BREAK CHANGE
BREAKING CHANGE
必须是大写,表示引入了破坏性 API 变更,通常是一个大版本的改动,BREAKING CHANGE: 之后必须提供描述,下面一个包含破坏性变更的提交示例
feat: allow provided config object to extend other configs
BREAKING CHANGE: `extends` key in config file is now used for extending other config files更详细的说明请看约定式提交规范
如何约束规范
怎么确保每个提交都能符合规范呢,最好的方式就是通过工具来生成和校验,commitizen是一个nodejs命令行工具,通过交互的方式,生成符合规范的git commit,界面如下:

开始安装:
# 全局安装
npm install -g commitizen
# 或者本地安装
$ npm install --save-dev commitizen
# 安装适配器
npm install cz-conventional-changelog packages.json在配置文件中指定使用哪种规范
...
"config": {
"commitizen": {
"path": "cz-conventional-changelog"
}
} 安装完成后可以使用git cz 来代替git commit,然后根据提示一步步输入即可
格式校验commitlint
可能你不想每次都通过交互界面来生成,还是想使用git commit -m 'message',那么为了确保信息的正确性,可以结合husky对提交的信息进行格式验证
安装依赖
npm install --save-dev @commitlint/{config-conventional,cli}
# 安装husky
npm install --save-dev husky 添加 commitlint.config.js文件到项目
echo "module.exports = {extends: ['@commitlint/config-conventional']}" > commitlint.config.js
```
`package.json`配置
#git提交验证
“husky”: {
“hooks”: {
“commit-msg”: “commitlint -E HUSKY_GIT_PARAMS”
}
}, OK到这一步就完成了,最后给你项目 README.MD 加上一个commitizen-friendly的标识吧
![]()
[ _blank](http://commitizen.github.io/cz-cli/)
## 自动版本管理和生成CHANGELOG
规范化的提交信息除了能很好描述项目的修改,还有一个很好的作用就是能根据提交记录来生成CHANGELOG.MD和自动生成版本号等功能。
### standard-version
一个用于生成`CHANGELOG.md`和进行`SemVer(语义化版本号)`发版的命令行工具
主要功能:
* 自动修改最新版本号,可以是`package.json`或者自定义一个文件
* 读取最新版本号,创建一个最新的`git tag`
* 根据提交信息,生成`CHANGELOG.md`
* 创建一个新提交包括 `CHANGELOG.md`和`package.json`
### 语义化版本控制(SemVer)
先简单了解下什么是语义化的版本控制,其是由`GitHub`发起的一份用于规范版本号递增的规则,
##### 版本格式
主版本号.次版本号.修订号,版本号递增规则如下:
* 主版本号(major):当你做了不兼容的 API 修改,
* 次版本号(minor):当你做了向下兼容的功能性新增,可以理解为Feature版本,
* 修订号(patch):当你做了向下兼容的问题修正,可以理解为Bug fix版本。
先行版本号可以加到“主版本号.次版本号.修订号”的后面,作为延伸。
##### 先行版本
当即将发布大版本改动前,但是又不能保证这个版本的功能 100% 正常,这个时候可以发布先行版本:
* alpha: 内部版本
* beta: 公测版本
* rc: 候选版本(Release candiate)
比如:1.0.0-alpha.0,1.0.0-alpha.1,1.0.0-rc.0,1.0.0-rc.1等。
`standard-version` 会根据提交的信息类型来自动更改对应的版本号,如下:
* feat: 次版本(minor)+1
* fix: 修订号(patch) +1
* BREAK CHANGE: 主板号(marjor) +1
> `standard-verstion` 生成的`CHANGELOG`只会包含`feat`,`fix`,`BREACK-CHANGE`类型的提交记录
#### 使用
``` bash
npm i --save-dev standard-version 添加npm script
{
scripts:{
"release": "standard-version",
"release:alpha": "standard-version --prerelease alpha",
"release:rc": "standard-version --prerelease rc"
}
}执行:
# npm run script
npm run release
# or global bin
standard-version或者你想指定发行版本号:
#指定类型 patch/minor/marjor
npm run release -- --release-as patch
#指定版本号
npm run release -- -- release-as 1.1.0生命周期
prerelease:所有脚本执行之前prebump/postbump: 修改版本号之前和之后prechangelog/postchangelog:生成changelog和生成changelog之后pretag/postag:生成tag标签和之后
standard-version本身只针对本地,并没有push才操作,我们可以在最后一步生成 tag 后,执行 push 操作,在paceage.json中添加
"standard-version": {
"scripts": {
"posttag": "git push --follow-tags origin master && npm publish"
}
}还有更多配置功能自行查阅 官方文档
其它类似工具
除了standard-version,还有其它类似的工具,有兴趣可以去了解下
修改Git Commit
为了使CHANGELOG.MD更能加直观看到每个版本的修改,我们尽量保证每次提交都是有意义的,但实际开发过程中,不可避免会提交了一些错误的 commit message,下面介绍几个git命令来修改commit
1 修改最后一次提交
git commit --amend该命令会创建一个提交并覆盖上次提交,如果是因为写错或者不满意上次的提交信息,使用该命令就非常适合。
2 合并多条提交
git reset --soft [commitID] 如果你想合并最近几条提交信息的话,那么就需要使用上面的命令来操作,指定要撤销的 ccommitId ,该命令会保留当前改动并撤销指定提交后的所有commit记录,如果不指定ID的话可以使用HEAD~{num} 来选择最近{num}条提交
git reset --soft HEAD~2 #合并最近两条提交
git commit -m 'feat: add new feat'带
--soft参数的区别在于把改动内容添加到暂存区 相当于执行了git add .
git rebase -i
git rebase的功能会更加强大,如果我想修改最近3条提交记录,执行
git rebase -i HEAD~3会出现如下编辑器界面(vim编辑器):
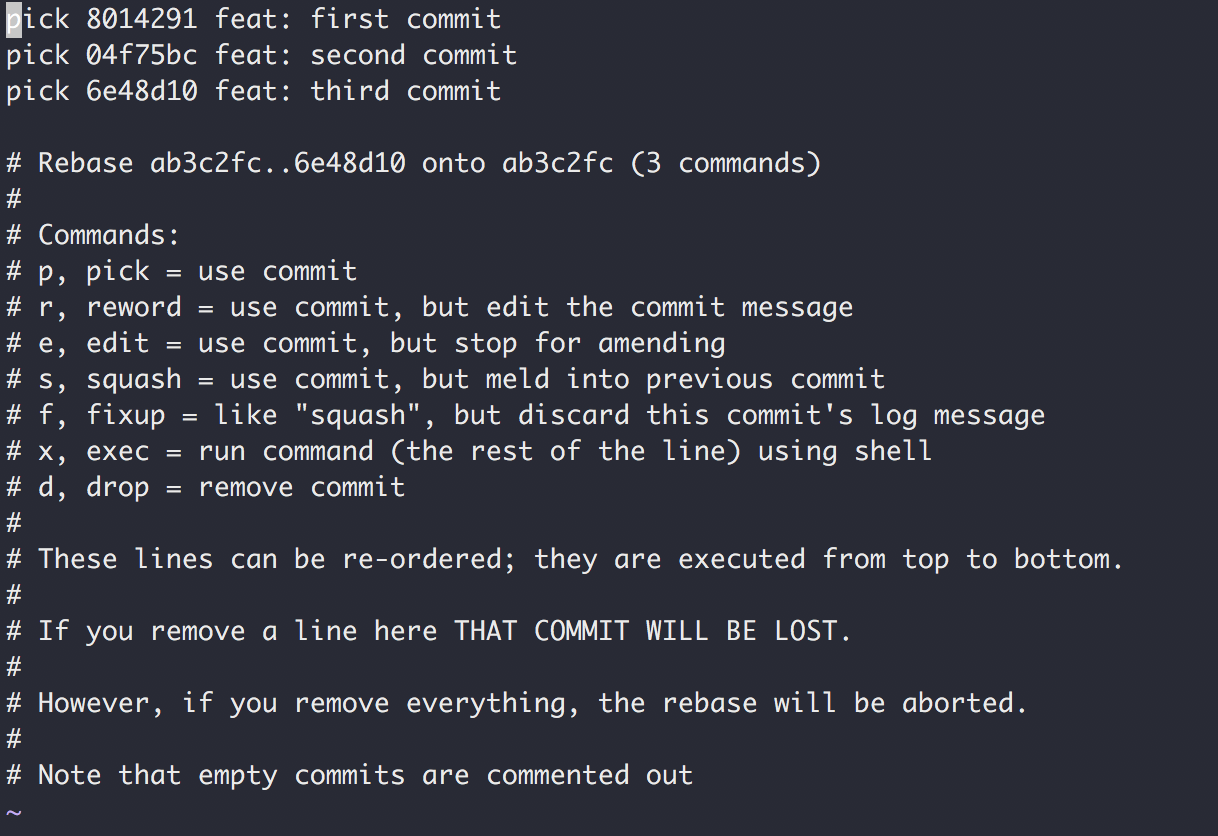
上面显示的是我最近 3条提交信息 ,下面是命令说明, 修改方式就是将 commit 信息前的pick改为你需要的命令,然后退出:wq保存
下面是常用的命令说明:
p,pick = 使用提交
r,reword = 使用提交,但修改提交说明
e,edit = 使用提交,退出后使用git commit --amend 修改
s,squash = 使用提交,合并前一个提交
f,fixup = 和squash相同,但丢弃提交说明日志
d,drop = 删除提交,丢弃提交记录最后
文本主要介绍了如何规范git commit和自动语义化版本管理,以及如何修改git commit,遵循一个规范其实没比之前随意填写信息增加多少工作量,但依赖规范却可以实现更多提升效率的事情。
参考
相关阅读
- git使用手册
- Git 教程
- GitHub 官方帮助文档中文版
- Github 教程
- GitHub 2020精选实战项目
- GitHub 优质开源项目与资源 2020版
- GitHub 中国开发者榜单 TOP200
- GitHub 全球开发者榜单 TOP200
作者:eijil
来源:凹凸实验室
CompletableFuture 超时功能有大坑!使用不当直接生产事故!
上一篇文章《
如何实现超时功能(以CompletableFuture为例)》中我们讨论了 CompletableFuture 超时功能的具体实现,从整体实现来说,JDK21前的版本有着内存泄露的bug,不过很少对实际生产有影响,因为任务的编排涉及的对象并不多,少量内存泄露最终会被回收掉。从单一功能内聚的角度来说,超时功能的实现是没有问题;然而由于并发编程的复杂性,可能会出现 Delayer 线程延迟执行的情况。本文将详细复现与讨论 CompletableFuture 超时功能的大坑,同时提供一些最佳实践指导。
快速入门 DeepSeek-R1 大模型
DeepSeek的官方网站地址如下:
https://www.deepseek.com/
本地部署DeepSeek
本地化方案非常简单:Ollama + DeepSeek-R1 + Enchanted LLM 。