因为这里的宏改动,主要涉及CUDA头文件和CUDA文件的修改,所以Cython文件和Python文件还有异常捕获宏我们还是复用
这篇文章里面用到的。测试内容是,定义一个原始数组和一个索引数组,输出索引的结果数组。
.NET 10 首个预览版发布,跨平台开发与性能全面提升
本次更新聚焦 JIT 编译器优化、运行时性能提升和跨平台开发体验增强,同时引入多项开发者期待的功能改进。
『Python底层原理』–Python字符串的秘密
无论是处理用户输入、文件读写还是网络通信,字符串都扮演着核心角色。
基于 Trae Claude-3.7 从0到1 打造加密货币钱包Dompet-App
大家好!今天我要分享如何使用强大的AI助手Trae Claude-3.7,从零开始构建一款功能丰富的加密货币钱包应用——Dompet-App。无论你是区块链爱好者还是移动开发新手,这个项目都能让你快速掌握React Native开发的精髓!
浅谈Tox之一
What is tox?
全程使用 AI 从 0 到 1 写了个小工具
AI在各个领域都有着迅猛的发展,至于编程更甚,尤其是Cursor的问世,让许多不懂技术不懂编程的人也跃跃欲试,经常在网上看到零基础小白使用AI几小时写个APP的文章,虽然我也经常用AI来解决程序问题,但大都是写个脚本或者实现代码片段,确实很好用,但对于只用AI从0到1完整实现个项目还没体验过,本着体验过才有发言权的原则,我决定亲自去试试。恰好最近在整理RSS,于是就想通过AI来写一个简单的RSS阅读器,以满足我自己琐碎时间的阅读需求
AI 插件第二弹,更强更好用
为了让大家获得更好的使用体验,我在业余时间加紧开发,如今插件已迭代至 第四个版本!
你的登录接口真的安全吗?
前言
大家学写程序时,第一行代码都是hello world。但是当你开始学习 WEB 后台技术时,很多人的第一个功能就是写的登录 (小声:别人我不知道,反正我是)。 但是我在和很多工作经验较短的同学面试或沟通的时候,发现很多同学虽然都有在简历上写:负责项目的登录/注册功能模块的开发和设计工作,但是都只是简单的实现了功能逻辑,在安全方面并没有考虑太多。这篇文章主要是和大家聊一聊,在设计一个登录接口时,不仅仅是功能上的实现,在安全方面,我们还需要考虑哪些地方。
安全风险
暴力破解!
只要网站是暴露在公网的,那么很大概率上会被人盯上,尝试爆破这种简单且有效的方式: 通过各种方式获得了网站的用户名之后,通过编写程序来遍历所有可能的密码,直至找到正确的密码为止
伪代码如下:
# 密码字典
password\_dict = \[\]
# 登录接口
login\_url = ''
def attack(username):
for password in password\_dict:
data = {'username': username, 'password': password}
content = requests.post(login\_url, data).content.decode('utf-8')
if 'login success' in content:
print('got it! password is : %s' % password)那么这种情况,我们要怎么防范呢?
验证码
有聪明的同学就想到了,我可以在它密码错误达到一定次数时,增加验证码校验!比如我们设置,当用户密码错误达到 3 次之后,则需要用户输入图片验证码才可以继续登录操作:
伪代码如下:
fail\_count = get\_from\_redis(fail\_username)
if fail\_count >= 3:
if captcha is None:
return error('需要验证码')
check\_captcha(captcha)
success = do\_login(username, password)
if not success:
set\_redis(fail\_username, fail\_count + 1)伪代码未考虑并发,实际开发可以考虑加锁。
这样确实可以过滤掉一些非法的攻击,但是以目前的 OCR 技术来说的话,普通的图片验证码真的很难做到有效的防止机器人(我们就在这个上面吃过大亏)。当然,我们也可以花钱购买类似于三方公司提供的滑动验证等验证方案,但是也并不是 100% 的安全,一样可以被破解(惨痛教训)。
登录限制
那这时候又有同学说了,那我可以直接限制非正常用户的登录操作,当它密码错误达到一定次数时,直接拒绝用户的登录,隔一段时间再恢复。比如我们设置某个账号在登录时错误次数达到 10 次时,则 5 分钟内拒绝该账号的所有登录操作。
伪代码如下:
fail\_count = get\_from\_redis(fail\_username)
locked = get\_from\_redis(lock\_username)
if locked:
return error('拒绝登录')
if fail\_count >= 3:
if captcha is None:
return error('需要验证码')
check\_captcha(captcha)
success = do\_login(username, password)
if not success:
set\_redis(fail\_username, fail\_count + 1)
if fail\_count + 1 >= 10:
# 失败超过10次,设置锁定标记
set\_redis(lock\_username, true, 300s)umm,这样确实可以解决用户密码被爆破的问题。但是,这样会带来另一个风险:攻击者虽然不能获取到网站的用户信息,但是它可以让我们网站所有的用户都无法登录! 攻击者只需要无限循环遍历所有的用户名(即使没有,随机也行)进行登录,那么这些用户会永远处于锁定状态,导致正常的用户无法登录网站!
IP 限制
那既然直接针对用户名不行的话,我们可以针对 IP 来处理,直接把攻击者的 IP 封了不就万事大吉了嘛。我们可以设定某个 IP 下调用登录接口错误次数达到一定时,则禁止该 IP 进行登录操作。
伪代码如下:
ip = request\['IP'\]
fail\_count = get\_from\_redis(fail\_ip)
if fail\_count > 10:
return error('拒绝登录')
# 其它逻辑
# do something()
success = do\_login(username, password)
if not success:
set\_redis(fail\_ip, true, 300s)这样也可以一定程度上解决问题,事实上有很多的限流操作都是针对 IP 进行的,比如 niginx 的限流模块就可以限制一个 IP 在单位时间内的访问次数。 但是这里还是存在问题:
- 比如现在很多学校、公司都是使用同一个出口 IP,如果直接按 IP 限制,可能会误杀其它正常的用户
- 现在这么多 VPN,攻击者完全可以在 IP 被封后切换 VPN 来攻击
手机验证
那难道就没有一个比较好的方式来防范吗? 当然有。 我们可以看到近些年来,几乎所有的应用都会让用户绑定手机,一个是国家的实名制政策要求,第二个是手机基本上和身份证一样,基本上可以代表一个人的身份标识了。所以很多安全操作都是基于手机验证来进行的,登录也可以。
- 当用户输入密码次数大于 3 次时,要求用户输入验证码(最好使用滑动验证)
- 当用户输入密码次数大于 10 次时,弹出手机验证,需要用户使用手机验证码和密码双重认证进行登录
手机验证码防刷就是另一个问题了,这里不展开,以后再有时间再聊聊我们在验证码防刷方面做了哪些工作。
伪代码如下:
fail\_count = get\_from\_redis(fail\_username)
if fail\_count > 3:
if captcha is None:
return error('需要验证码')
check\_captcha(captcha)
if fail\_count > 10:
# 大于10次,使用验证码和密码登录
if dynamic\_code is None:
return error('请输入手机验证码')
if not validate\_dynamic\_code(username, dynamic\_code):
delete\_dynamic\_code(username)
return error('手机验证码错误')
success = do\_login(username, password, dynamic\_code)
if not success:
set\_redis(fail\_username, fail\_count + 1)我们结合了上面说的几种方式的同时,加上了手机验证码的验证模式,基本上可以阻止相当多的一部分恶意攻击者。但是没有系统是绝对安全的,我们只能够尽可能的增加攻击者的攻击成本。大家可以根据自己网站的实际情况来选择合适的策略。
中间人攻击?
什么是中间人攻击
中间人攻击 (man-in-the-middle attack, abbreviated to MITM),简单一点来说就是,A 和 B 在通讯过程中,攻击者通过嗅探、拦截等方式获取或修改 A 和 B 的通讯内容。
举个栗子: 小白给小黄发快递,途中要经过快递点 A,小黑就躲在快递点 A,或者干脆自己开一个快递点 B 来冒充快递点 A。然后偷偷的拆了小白给小黄的快递,看看里面有啥东西。甚至可以把小白的快递给留下来,自己再打包一个一毛一样的箱子发给小黄。
那在登录过程中,如果攻击者在嗅探到了从客户端发往服务端的登录请求,就可以很轻易的获取到用户的用户名和密码。
HTTPS
防范中间人攻击最简单也是最有效的一个操作,更换 HTTPS,把网站中所有的 HTTP 请求修改为强制使用 HTTPS。
为什么 HTTPS 可以防范中间人攻击? HTTPS 实际上就是在 HTTP 和 TCP 协议中间加入了 SSL/TLS 协议,用于保障数据的安全传输。相比于 HTTP,HTTPS 主要有以下几个特点:
- 内容加密
- 数据完整性
- 身份验证
具体的 HTTPS 原理这里就不再扩展了,大家可以自行 Google
加密传输
在 HTTPS 之外,我们还可以手动对敏感数据进行加密传输:
- 用户名可以在客户端使用非对称加密,在服务端解密
- 密码可以在客户端进行 MD5 之后传输,防止暴露密码明文
其它
除了上面我们聊的这些以外,其实还有很多其它的工作可以考虑,比如:
- 操作日志,用户的每次登录和敏感操作都需要记录日志(包括 IP、设备等)
- 异常操作或登录提醒,有了上面的操作日志,那我们就可以基于日志做风险提醒,比如用户在进行非常登录地登录、修改密码、登录异常时,可以短信提醒用户
- 拒绝弱密码 注册或修改密码时,不允许用户设置弱密码
- 防止用户名被遍历 有些网站在注册时,在输入完用户名之后,会提示用户名是否存在。这样会存在网站的所有用户名被泄露的风险(遍历该接口即可),需要在交互或逻辑上做限制
- …
后记
现在国家不断的出台各种法律,对用户的数据越来越看重。作为开发者,我们也需要在保护用户数据和用户隐私方面做更多的工作。后面我也会和大家聊一聊,我们在数据安全方面,做了哪些工作,希望可以给到大家一点点帮助。
以上就是W3Cschool编程狮关于你的登录接口真的安全吗?的相关介绍了,希望对大家有所帮助。
Java面试题:谈谈String、StringBuffer、StringBuilder的区别?
文章来源于公众号:程序新视界 作者:丑胖侠二师兄
关于字符串的面试题除了内存分布、equals 比较,最常见的就是与StringBuffer和StringBuilder之间的区别了。
如果你回答:String 类是不可变的,StringBuffer和StringBuilder是可变类,StringBuffer是线程安全的,StringBuilder则不是线程安全的。
就上面的总结而言,好像知道的有点少。本篇文章就带领大家全面的了解一下它们三个的区别与底层实现。
String字符串的拼接
关于String字符串前面多篇文章已经详细描述过,它的不可变性也是因为每当通过“+”操作时,都会在内存中生成新的字符串而导致的。
String a = "hello ";
String b = "world!";
String ab = a + b;针对上述代码,内存分布图如下:
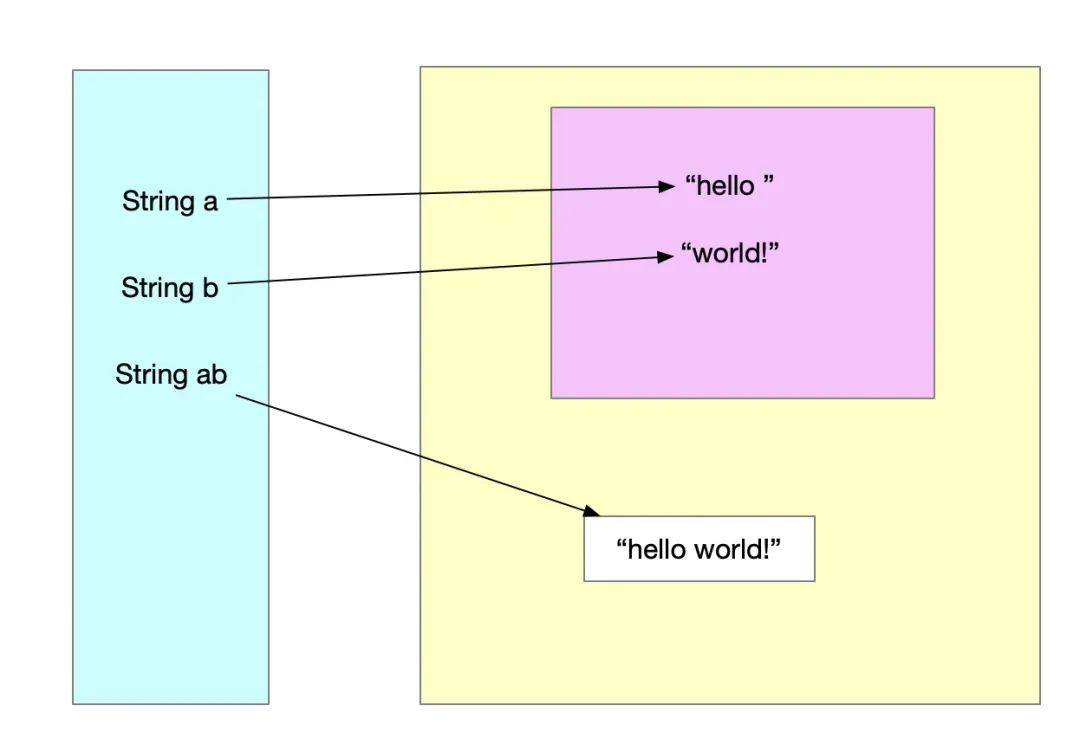
其中 a 和 b 初始化时位于字符串常量池,ab 拼接后的对象位于堆中。可以很直观的看出,经过拼接新生成了String对象。如果拼接多次,那么会生成多个中间对象。
上面的结论在Java8之前是成立的,在Java8时 JDK 对“+”号拼接进行了优化,上面所写的拼接方式会被优化为基于StringBuilder的append方法进行处理。
stack=2, locals=4, args_size=1
0: ldc #2 // String hello
2: astore_1
3: ldc #3 // String world!
5: astore_2
6: new #4 // class java/lang/StringBuilder
9: dup
10: invokespecial #5 // Method java/lang/StringBuilder."<init>":()V
13: aload_1
14: invokevirtual #6 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
17: aload_2
18: invokevirtual #6 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
21: invokevirtual #7 // Method java/lang/StringBuilder.toString:()Ljava/lang/String;
24: astore_3
25: return 上面是通过 javap -verbose命令反编译字节码的结果,很显然可以看到StringBuilder的创建和`append方法的调用。
此时,如果再笼统的回答:通过加号拼接字符串会创建多个String对象,因此性能比StringBuilder差,就是错误的了。因为本质上加号拼接的效果最终经过编译器处理之后和StringBuilder是一致的。
如果你在代码中使用如下写法:
StringBuilder sb = new StringBuilder("hello ");
sb.append("world!");
System.out.println(sb.toString()); 编译器的插件甚至建议你使用String来代替。
StringBuffer与StringBuilder的对比
StringBuffer和StringBuilder实现的核心代码基本一致,很多代码都是公用的。这两个类均继承自抽象类AbstractStringBuilder。
我们来从构造方法到append方法来逐一看一下它们的区别。先看StringBuilder的构造方法:
public StringBuilder(String str) {
super(str.length() + 16);
append(str);
} 其中super方法便是调用的AbstractStringBuilder的构造方法。对应StringBuffer的构造方法中实现也是如此:
public StringBuffer(String str) {
super(str.length() + 16);
append(str);
} 从构造方法来说,StringBuffer和StringBuilder是一样的。下面再看看append方法,StringBuilder实现如下:
@Override
public StringBuilder append(String str) {
super.append(str);
return this;
} StringBuffer对应的方法如下:
@Override
public synchronized StringBuffer append(String str) {
toStringCache = null;
super.append(str);
return this;
} 很显然,在StringBuffer的append方法实现上除了内部将toStringCache变量赋值为null,唯一的不同就是在方法上使用synchronized进行了同步处理。
toStringCache是用来缓存最后一次调用toString方法时生成的字符串,当StringBuffer内容变动时,该值也会变动。
通过上面的append方法的对比,我们可以很轻易的发现StringBuffer是线程安全的,StringBuilder是非线程安全的。当然,使用synchronized进行同步处理,性能便会降低很多。
StringBuffer与StringBuilder的底层实现
StringBuffer与StringBuilder都调用了父类的构造方法:
AbstractStringBuilder(int capacity) {
value = new char[capacity];
} 通过该构造方法我们可以看到它们用来处理字符串信息的关键属性为value。在初始化时先初始化一个长度为传入字符串长度+16的char[]数组,也就是value值,用来存储实际的字符串。
在调用父类构造方法之后便是调用各自的append方法(见前面的代码),而其中的核心处理又的调用父类的append方法:
public AbstractStringBuilder append(String str) {
if (str == null)
return appendNull();
int len = str.length();
ensureCapacityInternal(count + len);
str.getChars(0, len, value, count);
count += len;
return this;
} 上述代码中其中str.getChars方法用来对传入的str字符串进行拼接,在原有的value数组后面进行填充。而count用来记录当前value数字中已经使用的长度。

那么,当没有使用synchronized进行同步操作时,线程不安全发生在哪里?上面代码中count+=len并不是原子操作。比如当前count为 5,两个线程同时执行到 ++ 操作,拿到的值都为 5,执行完加操作之后赋值给count,两个线程赋值都为 6,而不是 7。此时便出现了线程不安全的问题。
为什么String要设计成不可变
在 Java 中将String设计成不可变的是综合考虑到各种因素的结果,有如下原因:
1、字符串常量池的需要,如果字符串可变,改变一个对象会影响到另外一个独立的对象。不变这也是字符串常量池存在的前提条件。
2、Java 中String对象的哈希码被频繁地使用,比如在HashMap等容器中。字符串不变保证了hash码的唯一性,可以方向缓存并使用。
3、安全性,确保String在当做参数传递时保持不变,避免安全隐患。比如在数据库用户名、密码、访问路径等传输过程中的保持不变,防止改变字符串指向对象的值被改变。
4、由于字符串变量不可变,在多线程中可以被共享使用。
小结
单纯的死记硬背面试题我们都会,但要在记忆面试题的过程中了解更多底层实现原理,不仅仅有助于理解“为什么”,同时还能学到更多相关的知识和原理。
在本文中简化了StringBuilder和StringBuffer内部数据的 copy 、数组扩容等步骤的讲解,感兴趣的朋友可以继续对照源码进行深入研究。
以上就是W3Cschool编程狮关于Java面试题:谈谈String、StringBuffer、StringBuilder的区别?的相关介绍了,希望对大家有所帮助。
尤雨溪:TypeScript不会取代JavaScript
来源 | evrone.com
译者 | 核子可乐
策划 | 蔡芳芳
近日,Evrone 与 Vue.js 的作者尤雨溪进行了一次访谈,了解他对于无后端与全栈方法、以及 Vue.js 适用场景的看法,还有他本人如何在工作与生活之间取得平衡。
记者: 嗨 Evan,很荣幸你能接受我们的访谈。那就先从一个简单的问题开始:您的全职工作岗位是由 Patreon 资助的,大多数人恐怕都没有这样的机会。您能聊聊怎样在工作与生活之间找到平衡,特别是如何避免长期工作带来的倦怠心理吗?
尤雨溪: 虽然我这份工作看似自己说了算,而且大部分时间也都是待在家里,但我每天还是会遵照固定的时间表。庆幸我有孩子,所以只要完成了工作内容,我可以马上陪伴家人。另外,我会在感觉需要的时候给自己安排一段比较长的假期,可能是几个礼拜。这一点对于上班族来说可能比较困难。
记者: 厉害!Vue 3 版本即将发布,在此之后,您是打算休息一阵子,还是马上开始规划 Vite build 系统的下一个版本?
尤雨溪: 我总是存着一大堆工作。在 Vite 方面,目前的目标就是努力提升稳定性——这是一套新系统,用户总会在我当初的设计场景之外使用,所以我得花点时间思考项目的下一步要如何发展。关于 Vue 3.1,我也已经有了一点想法。但休息是肯定的,给自己充电非常重要!
记者: 您是 Google Creative Lab 中的创造力技术专家与艺术史专家。在 Vue 项目当中,您有没有感觉自己的数学、算法以及数据结构功底有点薄弱?在您看来,是不是只有学习过计算机科学理论才能成为程序员?还是说只要能写出平平无奇但却易于理解的代码就可以?
尤雨溪: 坦率地讲,我遇到的这类问题不太多。我个人觉得 Vue 或者说大部分前端框架对于数学和算法专业知识的要求不算太高——至少跟数据库比没那么高。 我觉得自己在算法或者数据结构方面的确不强,虽然提升这方面能够肯定会有所帮助,但想要管理好前端框架项目,最重要的还是了解用户、设计出合理的 API、建立技术社区并长期维护项目承诺。
我觉得编写所谓“平平无奇却易于理解”的代码没什么不好,我不太认同这话里隐藏的那种贬义倾向。 实际上,编写出这样的代码也需要一定经验,而且好代码的核心在于执行效率高,而不是令人拍案称奇的实现思路。 没有接受专业的计算机科学教育当然也能编写软件,不过每一位开发者都应该重视专业教育背景带来的扎实基础。我个人一直采取比较务实的态度——先开始做事,哪怕做得不好。在做的过程中,我们会找到自己的不足之处,并确定下一阶段该从哪些方面提升自己。
记者: 说得好。借助 Nuxt.js 与 JAMstack 等技术方案,开发者得以专注于处理应用程序的前端部分,因为后端部分只需要直接交给 minimal/JS/BaaS 即可。您怎么看待这些“无后端”或者说“全栈”开发方法?
尤雨溪:我觉得这是一种强调以技术推动产品制造的开发思路。开发者们之所以选择这样的栈,是因为它们正适合自己当前构建的产品类型:后端逻辑相对简单,而前端交互更值得关注。虽然不是什么万灵药,但这类方案确实非常适合特定一部分应用场景。
记者: Vue 已经经历过多次重写。如果时光可以倒流,您会对现在的年轻人们提出怎样的技术建议?
尤雨溪: 请一定认真思考这个问题:怎么才能更好地拆分与解耦内部模块。
记者: 最近几年来,我们发现 JavaScript 与 TypeScript 可以说是齐头并进。您是怎么看待这样的趋势的?是会最终向核心 JavaScript 当中添加某些类型,用 TypeScript 取代 JavaScript,还是做出其他选择?
尤雨溪: 我觉得向 JS 本体中添加类型的可能性不大——因为 JS 是一套由社区委员会负责类型设计的系统,而根据 TC39 委员会的运作方式来看,这事没戏。另外,TypeScript 也不会取代 JS,前者只是 JS 的一个超集。我个人认为,JS 与 TS(带类型的超集)并行发展才是最合理的未来方向,而且这一点在可预见的未来不会改变。
记者: Vue 的用户群体已经超过百万。您认为衡量技术采用率的最佳方法是什么?Stack Overflow 问题热度、GitHub 星评以及其他公共访问指标都不错,但也有不少企业用户需要在隔离网络中工作。他们提不出多少问题,但却实实在在在“使用技术”。我们该怎样把他们纳入到技术普及率的计算中来?
尤雨溪: 对于开源软件来说,核定采用率确实是个老牌难题了,因为用户并没有义务上报自己的使用情况。而作为软件作者,我们也确实没有可靠的采用率跟踪方法。也正因为如此,我才觉得 devtools 扩展用户数量应该作为最可靠的指标,因为它至少覆盖到了全体用户。
记者: 即将发布的 Vue.js 3 中包含大量摇树(Tree Shaking)处理方面的更新。在您看来,为什么摇树处理用了这么久才正式登陆现代框架?是因为里头有什么重大阻碍吗?
尤雨溪: 摇树的工作机制,取决于源代码的特定构造方式——换句话说,只有在项目起步时就在代码编写与 API 设计中考虑到摇树机制,才能保证摇树拥有最好的效果。而现在,我们之所以需要引入大量变更才能实现摇树友好,就是因为直接摇树要么会影响到 API 变更、要么需要进行重大的结构调整(这会带来严重风险)。
记者: Vue 3 当中“基于函数的组件 API”提案遭到了社区成员们的强烈反对。事后来看,您有哪些值得与其他开发者分享的观点?
尤雨溪: 社区成员们之所以反对,是因为他们担心项目管理方会废弃掉 Vue 当前的(2.x 版本)API,其实我们并没有这样的想法。作为项目作者与维护者,我们一般会在日常工作中与热心的早期采用者交互,而他们对于新思路的态度往往比普通用户更开放、更积极,这也导致我们没能对向下兼容性给予应有的重视。用户不喜欢自己熟悉的一切被他人硬生生夺走,我已经深切理解到了这一点。
总而言之,最重要的是了解用户需求。但这事并不简单,有时候我们需要投入大量精力才能获得可靠的需求信息。倾听是必须的,综合各方面诉求才能得出合理的结论。
记者: Vue 的用例范围非常广泛,从小型企业到中型代理机构,再到市值数十亿美元的上市公司皆在其中。LV 公司与美国宇航局也在使用 Vue。有哪些使用 Vue 编写的高复杂度真实前端案例,给您留下了深刻印象?
尤雨溪: 问题在于,大多数“高复杂度真实前端案例”都不开源。我觉得要回答这个问题,大家可以多看看 Vue Devtools 与 Vue CIL UI,虽然它们不属于典型的面向消费者型 Web 应用程序,但无疑都属于由 Vue 编写而成的强大界面成果。
以上就是W3Cschool编程狮关于尤雨溪:TypeScript不会取代JavaScript的相关介绍了,希望对大家有所帮助。