
JavaScript中的变量监听:实时捕捉变化的利器
在JavaScript开发中,经常需要监听变量的改变,并在变量值发生变化时执行相应的操作。这种实时捕捉变化的功能对于构建交互性强的应用程序至关重要。本文将介绍如何在JavaScript中监听变量的改变,以及常用的方法和技巧,帮助你更好地利用...
在JavaScript开发中,经常需要监听变量的改变,并在变量值发生变化时执行相应的操作。这种实时捕捉变化的功能对于构建交互性强的应用程序至关重要。本文将介绍如何在JavaScript中监听变量的改变,以及常用的方法和技巧,帮助你更好地利用...

在Java开发中,中文乱码问题是一个常见而又令人头疼的难题。本文将深入分析Java中文乱码问题的原因,并提供一些解决方案,帮助开发者解决中文乱码困扰,确保程序能够正确处理中文字符。 字符集和编码概念 字符集(Charset):字符集是字符的...

在Python的异步编程领域,文件操作一直是一个具有挑战性的任务。传统的文件操作函数在异步环境下无法发挥其最大的潜力,而aiofiles库应运而生。aiofiles是一个针对异步I/O操作的Python库,它简化了异步文件处理的复杂性,并提...

俄罗斯在软件开发领域拥有令人瞩目的实力,许多世界级软件的成功故事都源自这个国家。本文将介绍几个俄罗斯人的世界级软件,包括Kaspersky、Yandex、Telegram等,揭示其在安全、搜索、通信等领域的杰出贡献和全球影响力。 俄罗斯作为...

C++编程中的常量定义方式一直是个讨论的热点话题。在这场终极对决中,我们将探索const和#define两种常量定义方式的优势和劣势。通过深入剖析作用域、类型检查、编译时期和代码调试等方面的差异,帮助您选择最佳的常量定义策略,以提高代码质量...

htmx是一种经过设计的JavaScript库,旨在简化前端开发中的交互性操作。本文将介绍htmx的概念、原理和关键特性,以及它在实际项目中的应用和优势。通过了解htmx,您将发现如何使用这一现代Web技术提高开发效率和用户体验。 htmx...

在Linux操作系统中,su(切换用户)和sudo(以超级用户权限运行)是两种常见的权限提升方式,用于在Unix和类Unix操作系统中执行需要较高权限的操作。本文将介绍su和sudo的定义、原理和使用方法,以及它们之间的区别。通过了解su和...

在Java编程中,处理时间间隔是一项常见任务。Java 8引入了Duration类,提供了方便的方法来处理和计算时间间隔。本文将介绍Duration类的定义、常见用法以及与其他时间类的比较。 Duration概述 Duration...

16日,OpenAI 宣布了 2024 年迄今为止最重要的人工智能模型:Sora,这是一种最先进的文本转视频模型,可以生成不同长宽比的高质量、高保真 1 分钟视频。Sora领先于该领域的其他...
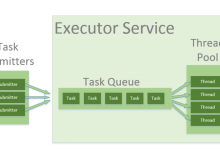
在Java中,Executor和ExecutorService是用于管理和执行异步任务的关键工具。本文将深入探讨Executor和ExecutorService的定义、功能以及它们之间的区别。通过了解这两个工具的不同之处,您将能够更好地选择...