
深入理解 C++ 静态库与动态库:从理论到实践
静态库在编译时被完整地链接到可执行文件中。你可以把它想象成一本书的章节,在印刷时就直接装订到了整本书里。
静态库在编译时被完整地链接到可执行文件中。你可以把它想象成一本书的章节,在印刷时就直接装订到了整本书里。
旧Asset Actions系统通常继承FAssetTypeActions_Base并实现核心OpenAssetEditor方法,并且一般在模块中通过IAssetTools::RegisterAssetTypeActions(MakeSha...
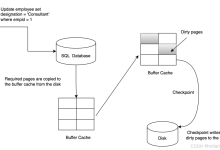
日志技术 在考虑数据库系统的持久性时,关键的考虑因素是如何在数据库中实现数据的持久化。例如,在关系型数据库中,数据被存储在表中,而这些表是通过在文件系统或块系统中的数据结构来实现的。如何保存和维护这些文件,例如在单一文件中存储索引或在多个文...

你可以通过工具调用让模型访问你自己的自定义代码。根据系统提示和消息,模型可能决定调用这些函数——而不是(或除了)生成文本或音频。
今天的主角依然是 Trae-SOLO。其实,无论是国外的主流 AI IDE,还是 Trae 本身,我的看法是:方法对了,就都能切实帮助我们提升工作效率,而不仅仅是快速写出一段代码。
FFmpeg的强大之处不仅在于其功能丰富,更在于它的灵活性和可编程性。虽然命令行界面可能让初学者望而生畏,但一旦掌握基础语法,你会发现它是一个效率倍增器。无论是处理个人媒体库,还是构建专业的音视频处理流水线,FFmpeg都能提供稳定可靠的解...
首先需要了解一下 Caffe是什么?
https://github.com/iceyhexman/flask_memory_shell
C#/.NET/.NET Core技术前沿周刊,你的每周技术指南针!记录、追踪C#/.NET/.NET Core领域、生态的每周最新、最实用、最有价值的技术文章、社区动态、优质项目和学习资源等。让你时刻站在技术前沿,助力技术成长与视野拓宽。